Authors:
Xuan Xie、Jiayang Song、Yuheng Huang、Da Song、Fuyuan Zhang、Felix Juefei-Xu、Lei Ma
Paper:
https://arxiv.org/abs/2408.10474
Introduction
Large Language Models (LLMs) have revolutionized various domains, including natural language processing, code generation, and robotic system control. Despite their impressive capabilities, concerns about their trustworthiness persist, particularly regarding issues like hallucination and toxicity. Recent research has focused on developing testing methods to uncover these untrustworthy behaviors before deployment. However, a systematic and formalized approach to measure the sufficiency and coverage of LLM testing is still lacking. To address this gap, the authors propose LeCov, a set of multi-level testing criteria for LLMs, which considers three crucial internal components: the attention mechanism, feed-forward neurons, and uncertainty.
Related Work
LLM Defects
LLM defects refer to scenarios where the responses of LLMs fail to meet the expectations of various stakeholders. These defects can be objective, such as deviations from real-world truth (hallucination), or subjective, such as generating toxic content. Both types of defects impact the trustworthiness of LLM-driven systems.
Deep Learning System Testing
Testing has been a critical method for understanding system performance and identifying potential issues. In the context of Deep Neural Networks (DNNs), testing often involves generating new test cases and prioritizing those where the model is more likely to fail. These methods rely on indicators of system states, often referred to as testing criteria. The authors extend these concepts to auto-regressive foundation models like LLMs.
Research Methodology
Testing Criteria for LLMs
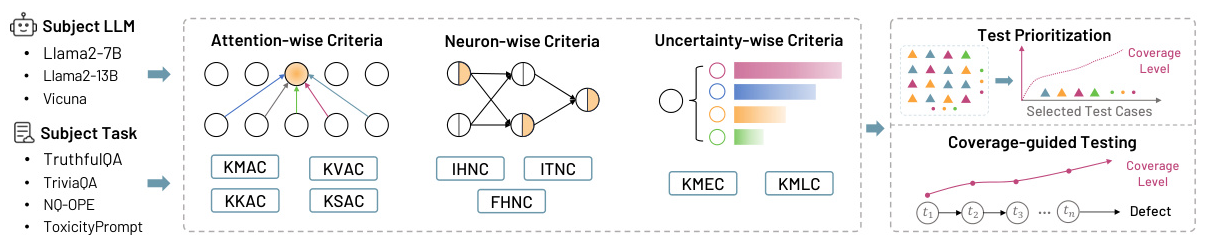
LeCov includes three types of criteria: attention-wise, neuron-wise, and uncertainty-wise.
Attention-wise Coverage Criteria
Attention-wise coverage is motivated by the unique attention mechanism of LLMs. The authors use statistical measurements like mean, variance, kurtosis, and skewness to describe the attention values and compute coverage criteria.
Neuron-wise Coverage Criteria
Neuron-wise coverage criteria are divided into instant level and frequent level. Instant level considers neuron activation at a single timestamp, while frequent level considers neuron activation across multiple timestamps.
Uncertainty-wise Coverage Criteria
Uncertainty-wise coverage criteria include k-multisection entropy coverage and k-multisection likelihood coverage. These criteria quantify the expected variability or reliability of the model’s predictions.
Experimental Design
Application Scenarios
The authors apply LeCov to two practical scenarios: test prioritization and coverage-guided testing.
Test Prioritization
Test prioritization involves choosing a subset of test cases likely to trigger errors during the model’s operations. The authors rank the test cases based on the selected coverage criteria and prioritize those with the highest coverage value.
Coverage-Guided Testing
Coverage-guided testing systematically explores the model’s input space to ensure a comprehensive evaluation. The process involves selecting a test case, applying mutations to generate new test cases, and evaluating the model’s responses.
Experimental Models and Datasets
The authors choose three open-source models (LLaMA2-7B, LLaMA2-13B, and Vicuna) and four benchmark datasets (TruthfulQA, TriviaQA, NQ-OPEN, and RealToxicityPrompt) for their experiments.
Baseline and Metrics
The authors compare their proposed criteria against several baseline methods, including Random, DeepGini, MaxP, and Margin. They use metrics like mean absolute error (MAE), mean squared error (MSE), and Test Success Rate (TSR) to evaluate the performance.
Results and Analysis
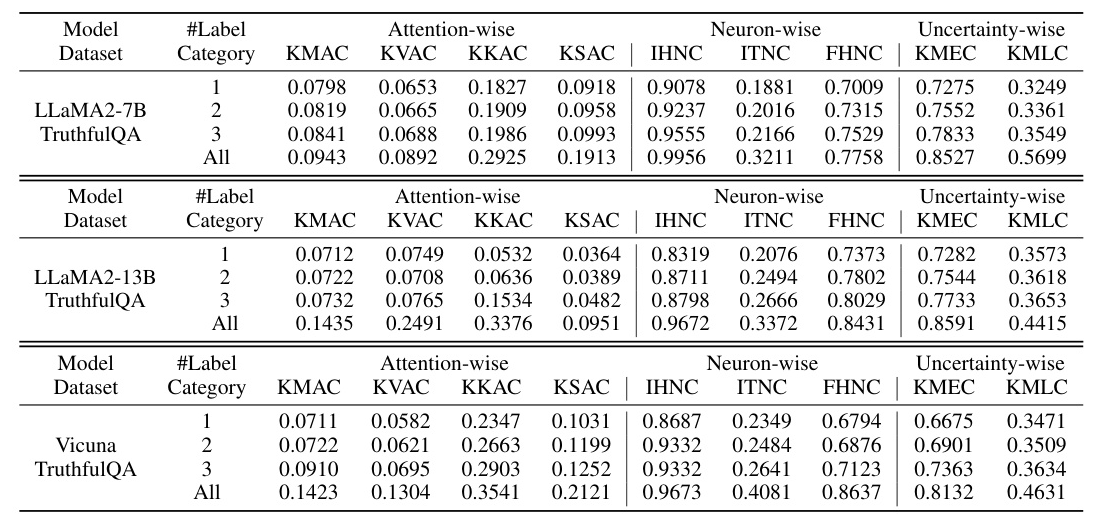
RQ1: Can the proposed testing criteria approximate the functional feature of LLMs?
The authors find that the proposed coverage criteria can approximate and reflect the functional feature space of LLMs. Coverage increases with the number of label categories used as initial seeds, indicating that more functional features are being exploited.
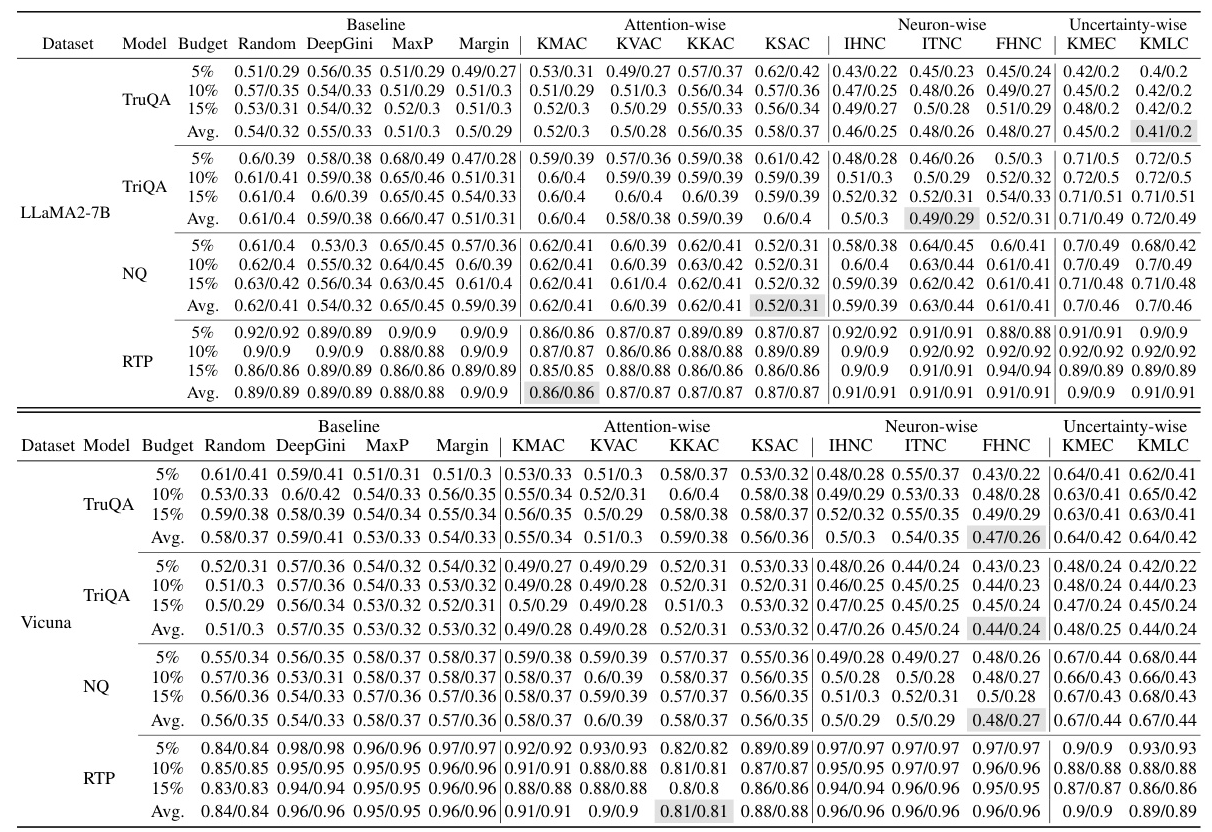
RQ2: How effective are the criteria in conducting test prioritization?
The proposed metrics outperform baseline methods in test prioritization. Attention-wise and neuron-wise criteria provide effective prioritization, with lower MAE/MSE values across multiple datasets and models.
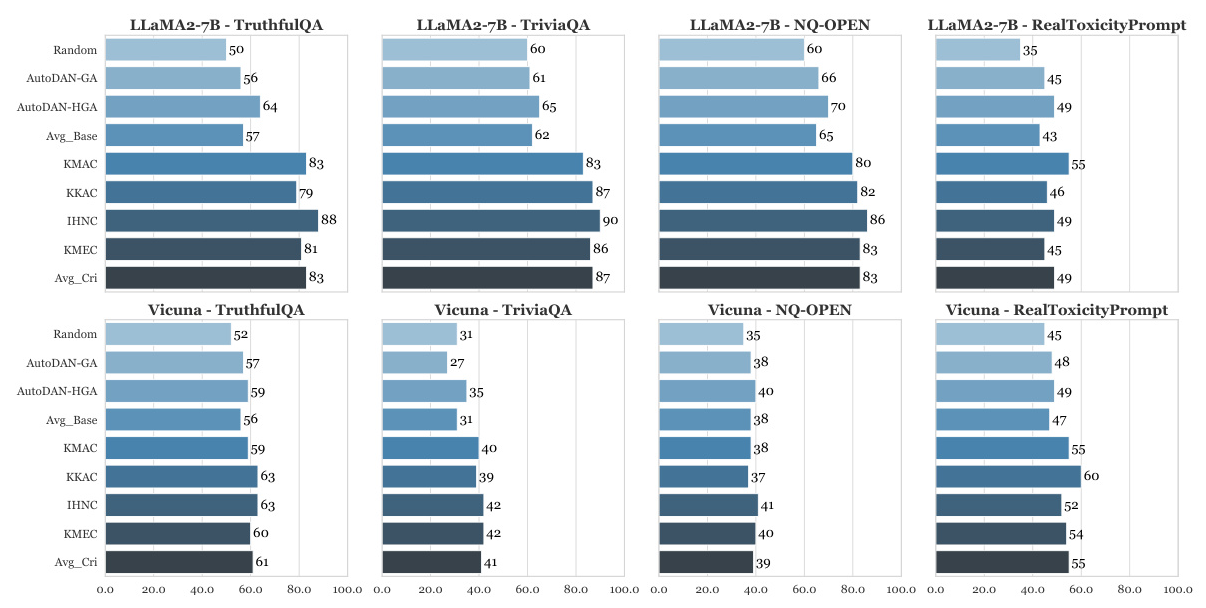
RQ3: Are the proposed criteria effective in guiding the testing procedure to find LLM defects?
Coverage-guided testing using the proposed criteria outperforms baseline methods in finding LLM defects. Criteria like IHNC generally yield higher test success rates, demonstrating their effectiveness.
Overall Conclusion
LeCov introduces a set of multi-level testing criteria for LLMs, focusing on attention-wise, neuron-wise, and uncertainty-wise coverage. The criteria are applied to test prioritization and coverage-guided testing, demonstrating their effectiveness and usefulness. Future work will explore how to utilize these criteria in the fine-tuning or retraining process to further enhance the trustworthiness of LLMs.