Authors:
Paper:
https://arxiv.org/abs/2408.10292
Introduction
Background
Contrastive representation learning has emerged as a powerful technique in self-supervised learning, particularly for tasks such as image classification, object detection, and instance segmentation. The core idea is to learn representations by maximizing the mutual information between different views of unlabeled data. However, recent studies have shown that simply increasing the estimated mutual information does not necessarily lead to better performance in downstream tasks. This observation suggests that the learned representations may contain not only task-relevant information but also task-irrelevant (superfluous) information, which can degrade performance.
Problem Statement
The presence of superfluous information in learned representations can negatively impact the performance of downstream tasks. This paper introduces a new objective function, termed SuperInfo, designed to mitigate this issue by balancing the retention of predictive information and the elimination of superfluous information. The proposed method aims to improve the robustness and effectiveness of learned representations across various tasks.
Related Work
Contrastive Representation Learning
Contrastive representation learning has shown significant promise in self-supervised learning. Various methods have been developed to maximize the mutual information between different views of data, such as SimCLR, BYOL, and others. These methods typically involve data augmentations to create multiple views and then use a contrastive loss to learn representations.
Challenges in Mutual Information Estimation
Several studies have highlighted the limitations of maximizing mutual information. For instance, it has been observed that higher mutual information does not always correlate with better downstream performance. This discrepancy has led researchers to explore the components of mutual information, distinguishing between task-relevant and task-irrelevant information.
Prior Approaches
Previous works have attempted to address the issue of superfluous information by various means, such as the InfoMin principle, which aims to reduce mutual information appropriately, and the application of the Information Bottleneck theory. However, these methods often lack a general objective function or fail to provide a comprehensive solution.
Research Methodology
Motivation
The goal of supervised representation learning is to find a representation that is sufficient for the label information. In contrastive learning, the objective is to maximize the shared information between different views. However, this shared information can include both task-relevant and task-irrelevant components. The proposed method aims to decompose these components and design an objective function that minimizes the superfluous information while retaining the predictive information.
SuperInfo Loss Function
The SuperInfo loss function is formulated as follows:
[ J = I(z_1; z_2) – \lambda_a I(v_1; z_1 | v_2) – \lambda_b I(v_2; z_2 | v_1) ]
Where:
– ( I(z_1; z_2) ) is the mutual information between the learned representations.
– ( I(v_1; z_1 | v_2) ) and ( I(v_2; z_2 | v_1) ) represent the superfluous information.
– ( \lambda_a ) and ( \lambda_b ) are tunable coefficients.
The objective is to maximize ( J ), which involves maximizing the mutual information between representations while minimizing the superfluous information.
Experimental Design
Data and Augmentations
The experiments are conducted on CIFAR10, STL-10, and ImageNet datasets. Standard data augmentations such as random cropping, flipping, and color distortion are applied.
Architecture
The ResNet-18 architecture is used for CIFAR10 and STL-10, while ResNet-50 is used for ImageNet. An MLP is applied to the output of the ResNet to obtain a 128-dimensional vector for mutual information estimation.
Training and Evaluation
The models are pre-trained using the Adam optimizer for CIFAR10 and STL-10, and the LARS optimizer for ImageNet. The learned representations are evaluated using a linear classifier on various downstream tasks, including image classification, object detection, and instance segmentation.
Results and Analysis
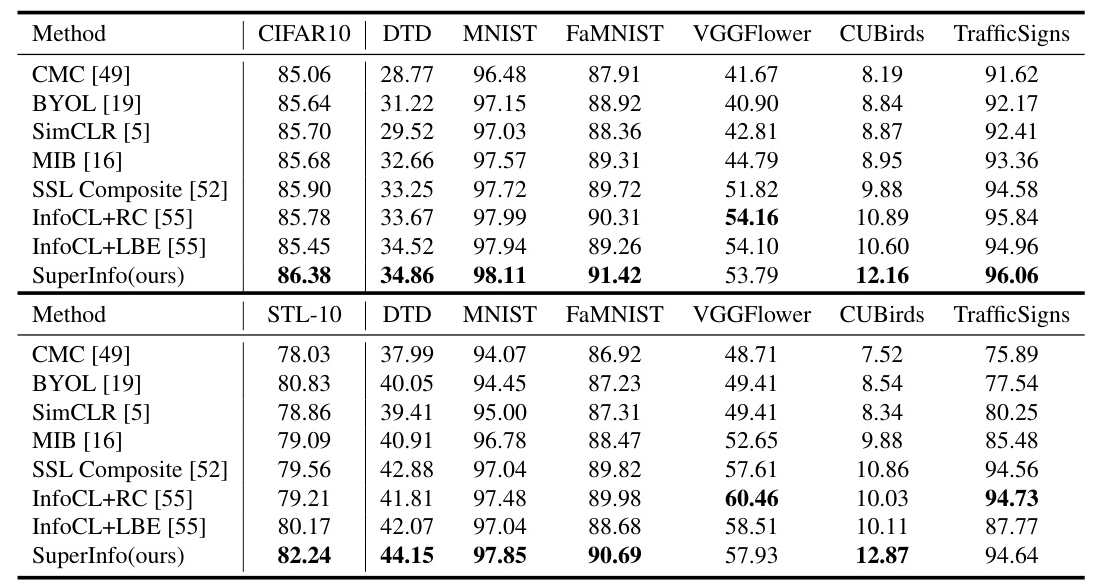
Classification Performance
The SuperInfo method outperforms previous methods on CIFAR10, STL-10, and ImageNet, achieving state-of-the-art results. The downstream classification results also show significant improvements on multiple benchmarks.
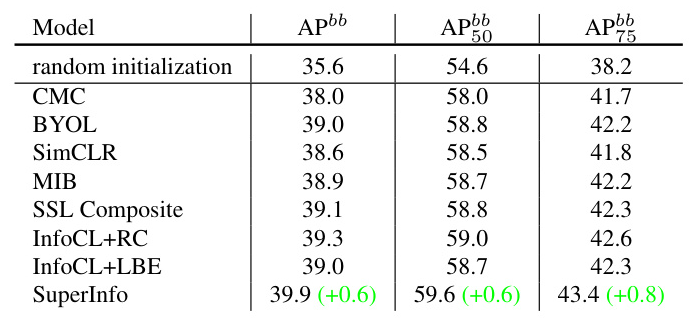
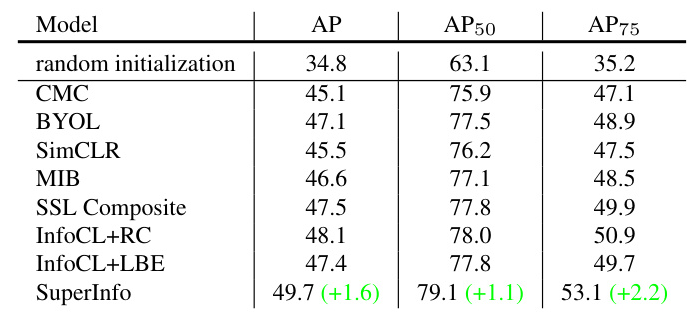
Object Detection and Segmentation
The SuperInfo method demonstrates superior performance in object detection and instance segmentation tasks on PASCAL VOC and COCO datasets, further validating its effectiveness.
Ablation Studies
Ablation studies reveal the importance of balancing the coefficients in the SuperInfo loss function. Adjusting these coefficients can help discard superfluous information while retaining non-shared task-relevant information, leading to better performance across different tasks.
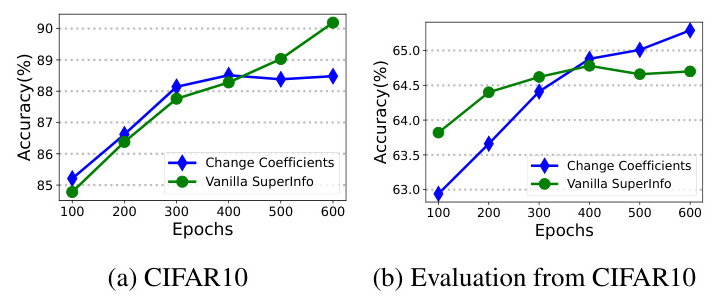
Training Epochs
The experiments show that increasing the number of training epochs does not always lead to better performance. The learned representations may overfit to the minimal sufficient representation, which can degrade performance on transfer datasets.
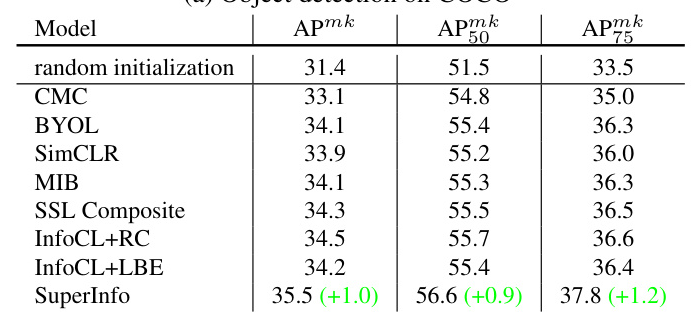
Overall Conclusion
The SuperInfo method effectively addresses the issue of superfluous information in contrastive representation learning. By balancing the retention of predictive information and the elimination of superfluous information, the proposed method achieves significant improvements in various downstream tasks. Future work could focus on automating the tuning of coefficients and exploring the method’s scalability with larger batch sizes and more training epochs.