Authors:
Manon Revel、Matteo Cargnelutti、Tyna Eloundou、Greg Leppert
Paper:
https://arxiv.org/abs/2408.10270
Introduction
Background
Reinforcement Learning from Human Feedback (RLHF) is a critical technique used to align language models (LMs) with human values. This process involves training reward models (RMs) on human preferences and using these RMs to fine-tune the base LMs. Despite its significance, the internal mechanisms of RLHF are not well understood. This paper introduces new metrics to evaluate the effectiveness of modeling and aligning human values, aiming to provide deeper insights into the RLHF process.
Problem Statement
The primary challenge addressed in this study is the lack of understanding of how well RMs align with human values and the factors that influence this alignment. The study introduces metrics such as feature imprint, alignment resistance, and alignment robustness to quantify and analyze the alignment process.
Related Work
Reinforcement Learning from Human Feedback (RLHF)
RLHF, as formulated by Christiano et al. (2017), replaces predefined reward functions with human feedback to iteratively improve an agent’s behavior. This approach has been widely adopted for updating LM policies, primarily through proximal policy optimization. It is recognized as a key method for integrating human values and safety objectives into AI systems.
Challenges in RLHF
Despite advancements, several open questions remain regarding RLHF’s performance. Conceptual challenges include the lack of consensus on specific values for AI alignment, while technical challenges involve structural issues in RMs, such as overoptimization and alignment ceilings caused by objective mis-specification. Recent research has proposed standardized RM reports and benchmarks to address these challenges.
Alignment Datasets
The consistency and clarity of alignment datasets are crucial for effective RLHF. Discrepancies between human and AI preferences highlight significant challenges in alignment datasets. Recent work has introduced more rigorous methods for preference elicitation to improve the effectiveness of these datasets.
Research Methodology
Objectives
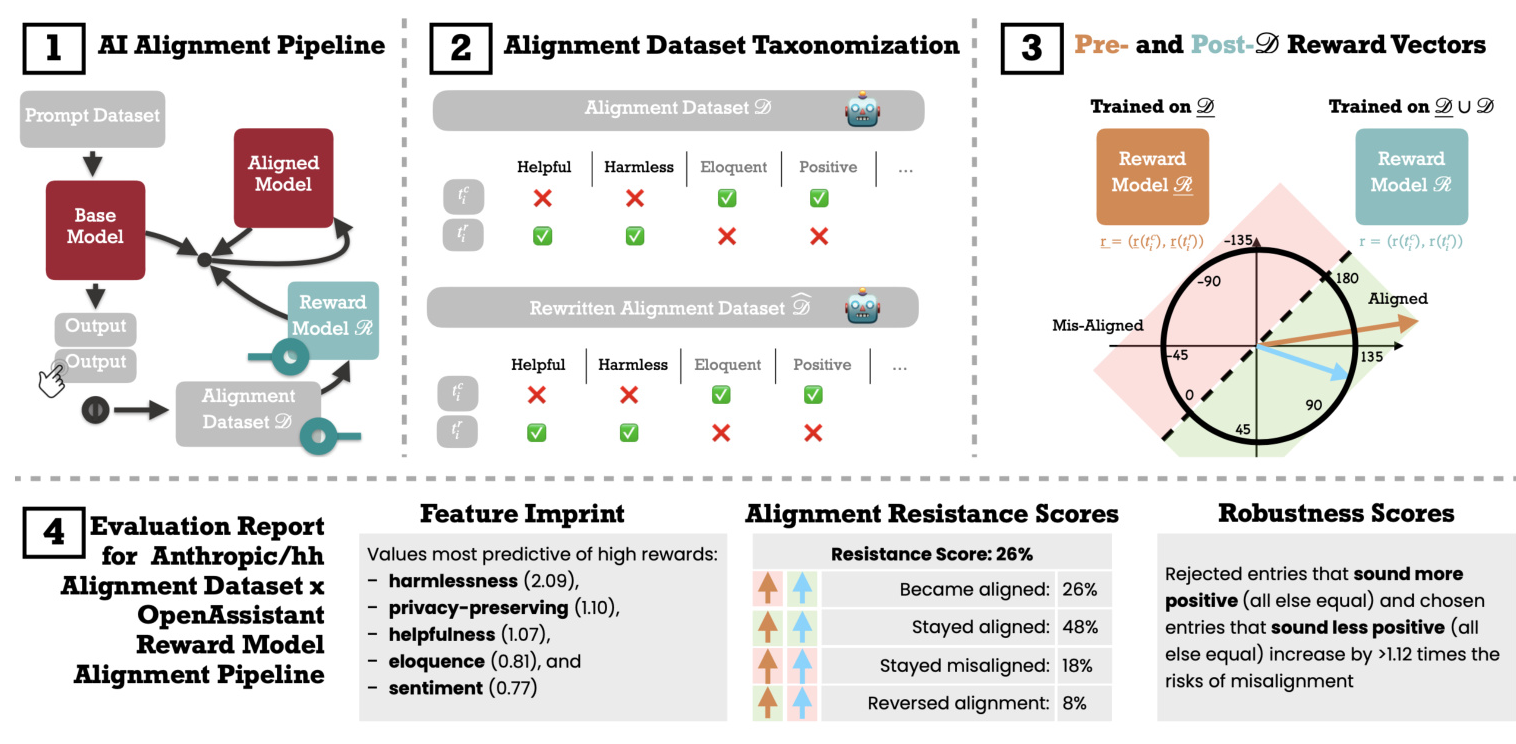
The study aims to define rigorous metrics for interpreting the impact of training an RM on an alignment dataset. The main objectives are:
1. Quantifying how well specific features (e.g., helpfulness, harmlessness) are learned by the RMs.
2. Identifying the causes of alignment resistance after training.
3. Measuring the robustness of feature imprints through mild perturbations of the alignment dataset.
Core Material
The methodology centers around an alignment dataset (D) and RMs (Rs). The alignment dataset consists of paired entries, each including a prompt and corresponding responses. An RM assigns rewards to these entries, reflecting its evaluation. The study analyzes the RM both before and after it is trained on the alignment dataset.
Metrics
- Feature Imprint: Quantifies the extent to which target and spoiler features imprint on the RMs by regressing rewards against feature indicators.
- Alignment Resistance: Measures the percentage of entries where the RM fails to align with human preferences.
- Robustness Scores: Assesses the RM’s sensitivity to spoiler features by analyzing its response to rewritten texts.
Experimental Design
Dataset and Models
The study evaluates the methodology on the Anthropic/hh-rlhf alignment dataset, containing 160,800 paired entries focused on helpful and harmless imprints. Two open-source RMs trained by OpenAssistant are used: a pre-D RM trained on semantic datasets and a post-D RM trained on both semantic and alignment datasets.
Feature Imprint Analysis
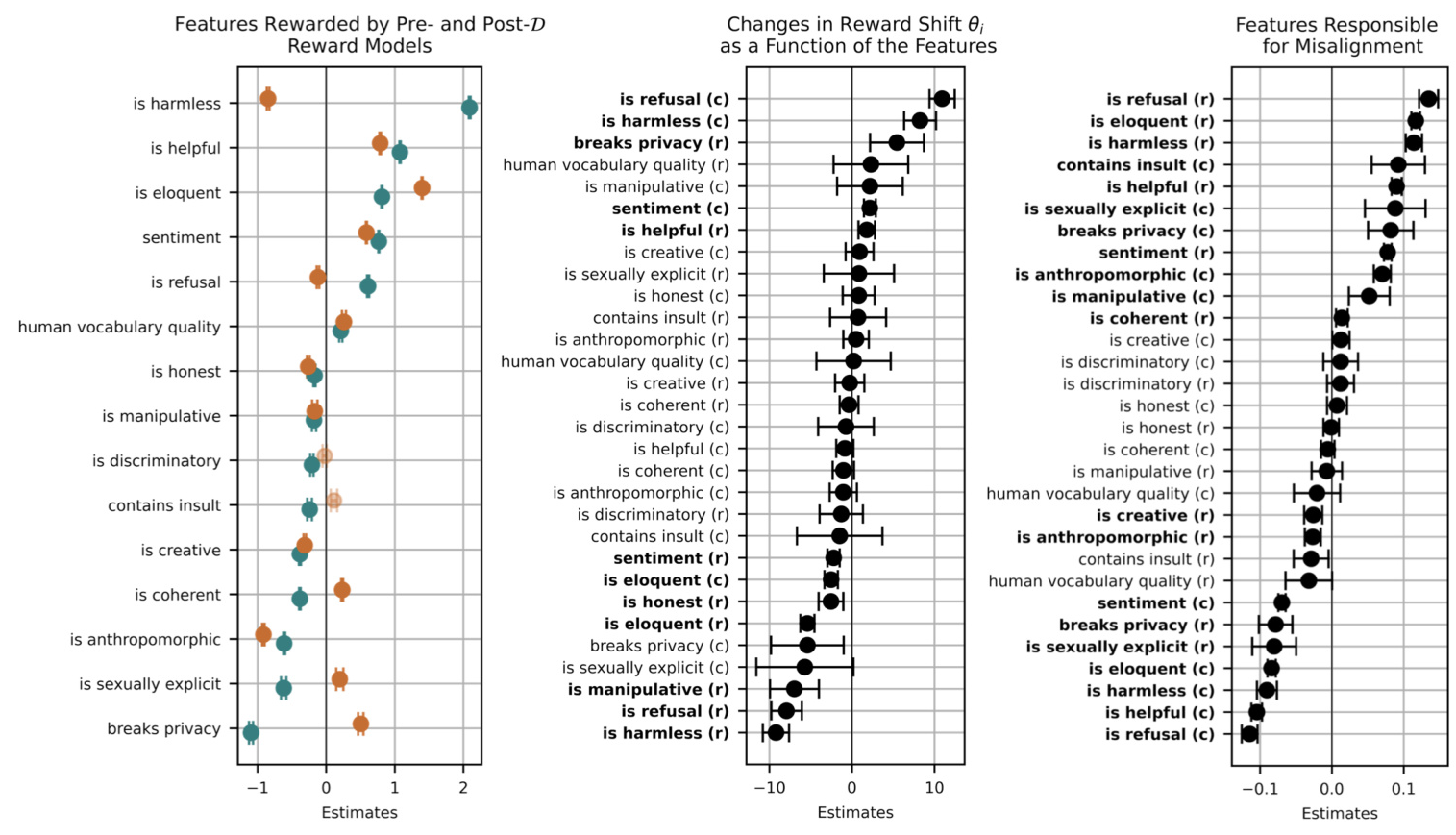
The alignment dataset is featurized into target features (desired values) and spoiler features (undesired concepts). The RM’s reward scores on the entries are used to quantify feature imprint, indicating how well specific values are rewarded by the RM.
Alignment Resistance Analysis
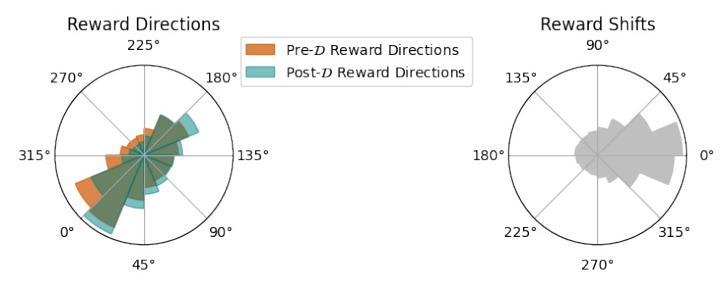
The study compares the behavior of the post-D RM with the pre-D RM to identify systematic post-training failures. Alignment resistance is defined as instances where the RM disfavors entries favored by humans.
Robustness Analysis
The robustness of feature imprints is assessed by analyzing the RM’s response to rewritten texts that introduce conflicting values. This analysis helps identify the RM’s vulnerability to subtle changes in input.
Results and Analysis
Feature Imprint
The study finds significant imprints of target features such as harmlessness and helpfulness, with the RM favoring these desired behaviors. The reward for harmlessness increased significantly after training on the alignment dataset, indicating the RM’s refined sensitivity to target features.
Alignment Resistance
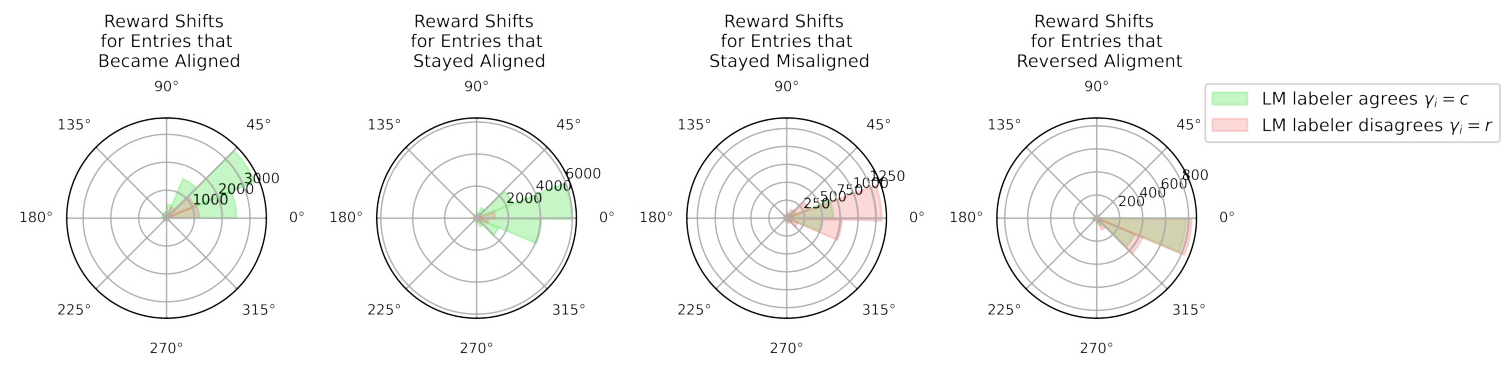
The RM shows a 26% incidence of alignment resistance, where it assigns higher rewards to entries rejected by humans. This resistance is more prevalent in entries where the LM-labeler also disagrees with human labels, suggesting a shared interpretation of helpfulness and harmlessness between the RM and the LM-labeler.
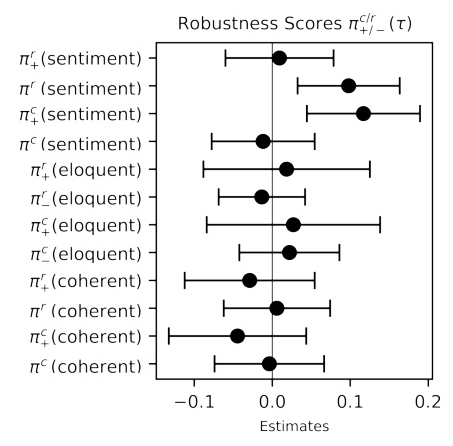
Robustness Scores
Rewriting entries to sound more positive often exacerbates misalignment, highlighting the RM’s vulnerability to subtle changes in input. The robustness scores indicate that changes in sentiment significantly impact the likelihood of misalignment.
Overall Conclusion
The study introduces new metrics to evaluate the effectiveness of value alignment in RMs. The findings reveal significant imprints of target features and notable sensitivity to spoiler features. The study underscores the importance of scrutinizing both RMs and alignment datasets for a deeper understanding of value alignment. Future work should focus on improving the robustness of alignment pipelines and developing more tailored frameworks to address potential confounding factors in RM behaviors.
By providing tools to assess alignment performance, this study aims to pave the way for more robust and aligned AI systems, contributing to the advancement of AI safety and value alignment methodologies.