Authors:
Chengyu Gong、Gefei Shen、Luanzheng Guo、Nathan Tallent、Dongfang Zhao
Paper:
https://arxiv.org/abs/2408.10264
Introduction
Background and Motivation
In the realm of scientific data management, one of the most resource-intensive operations is the search for the k-nearest neighbors (KNN) of a newly introduced item. Traditional indexing techniques like DBSCAN and K-means are often employed to expedite this process. However, these methods fall short when dealing with multimodal scientific data, where different types of data (e.g., images and text) are not directly comparable.
Recent advancements in multimodal machine learning offer a promising alternative by generating embedding vectors that semantically represent the original multimodal data. Despite their potential, these embedding vectors often have high dimensionality, which is impractical for time-sensitive scientific applications. This study introduces Order-Preserving Dimension Reduction (OPDR) to address this issue by reducing the dimensionality of embedding vectors while preserving the order of the k-nearest neighbors.
Proposed Work
This paper proposes a novel concept called Order-Preserving Measure (OPM) to maintain the set of nearest neighbors during dimension reduction. The study constructs a closed-form function to quantify the relationship between the target dimensionality and other variables, incorporating this function into popular dimension-reduction methods and embedding models. The effectiveness of the OPDR method is demonstrated through extensive experiments on multiple scientific datasets.
Related Work
Multimodal Scientific Data
Multimodal scientific data has garnered significant research interest. For example, the MELINDA dataset focuses on classifying biomedical experiment methods using multiple data types. Other studies, such as those on explainable AI and domain-specific language models like GIT-Mol and MatSciBERT, highlight the potential of specialized models in capturing domain-specific knowledge. However, these models often focus solely on text-based data, necessitating methods to balance information preservation and data complexity.
Contrastive Language-Image Pre-Training
The development of large language models like BERT and ViT has significantly advanced text analysis and image recognition. The CLIP model integrates both text and image data, marking a significant step forward in multimodal data processing. Various studies have proposed methods to improve the CLIP model, such as TiMix and SoftCLIP, which address issues like noisy data and alignment between text and images.
Dimension Reduction
Numerous methods have been proposed to preserve pairwise distances in lower-dimensional spaces, such as Multidimensional Scaling (MDS) and Principal Component Analysis (PCA). Recent approaches like Similarity Order Preserving Discriminant Analysis aim to preserve data order post-reduction. However, none of these methods focus on preserving the set of k-nearest neighbors during dimension reduction.
Research Methodology
Order-Preserving Measure
The Order-Preserving Measure (OPM) provides a metric for the number of nearest neighbors that remain unchanged between two spaces. For example, if the 2-closest points in a metric space X are still the same 2-closest points in a metric space Y, the map is considered order-preserving of 2 (OP2). This measure is not inclusive, meaning OPk+1 does not necessarily imply OPk.
Mathematically, a measure is a function that maps a subset of a set X to a value in the extended real line. The construction of the σ-algebra of embedding vectors involves defining the target number of preserved k-nearest neighbors and the target metric space Y. The measure function is then defined to quantify the preservation of k-nearest neighbors between the original and reduced spaces.
Closed-Form Function
The study constructs a closed-form function to quantify the relationship between the measure and other parameters, such as space dimensionality and the number of data points. The function is based on the hypothesis that the target dimensionality is positively influenced by both the accuracy of k-nearest neighbors and the cardinality of the data points. The function takes the form:
[ \text{dim}(Y) = \mathcal{O}(m \cdot 2^a) ]
where ( a ) represents the accuracy and ( m ) the number of data points. This function is verified through experiments and incorporated into dimension-reduction methods.
Experimental Design
Data Preparation
The study uses multimodal scientific data, including textual data from HDF5 files and images in formats like TIFF and PNG. Embeddings are generated using transformer-based models like CLIP, ViT, and BERT. The embeddings are then combined to create a unified representation of the multimodal data.
Dimension-Reduction Techniques
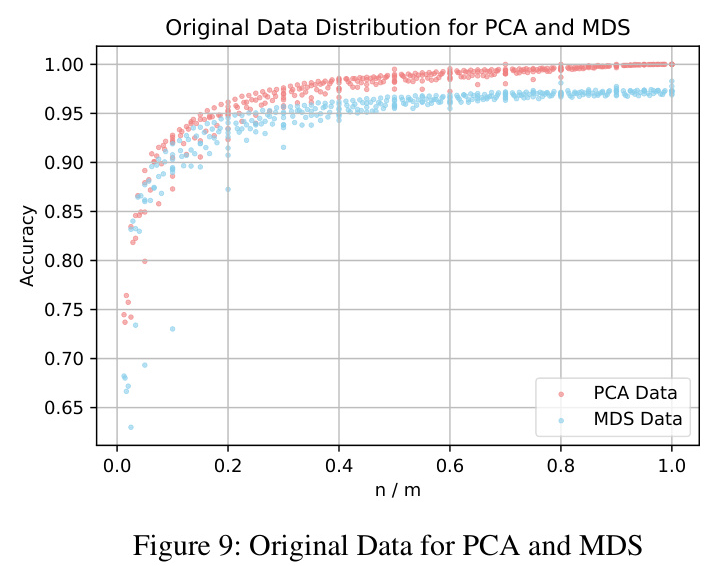
The study evaluates several dimension-reduction techniques, including PCA and MDS. PCA consistently outperformed other methods in maintaining the integrity of location information in the datasets. Various regression models are used to elucidate the relationship between the accuracy of preserved relative location information and the ratio of the target dimension to the number of samples.
Experimental Setup
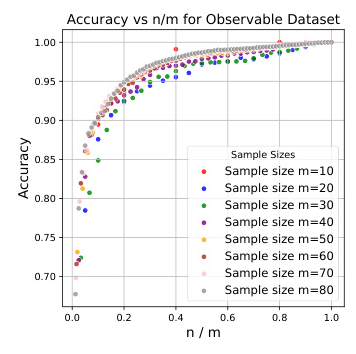
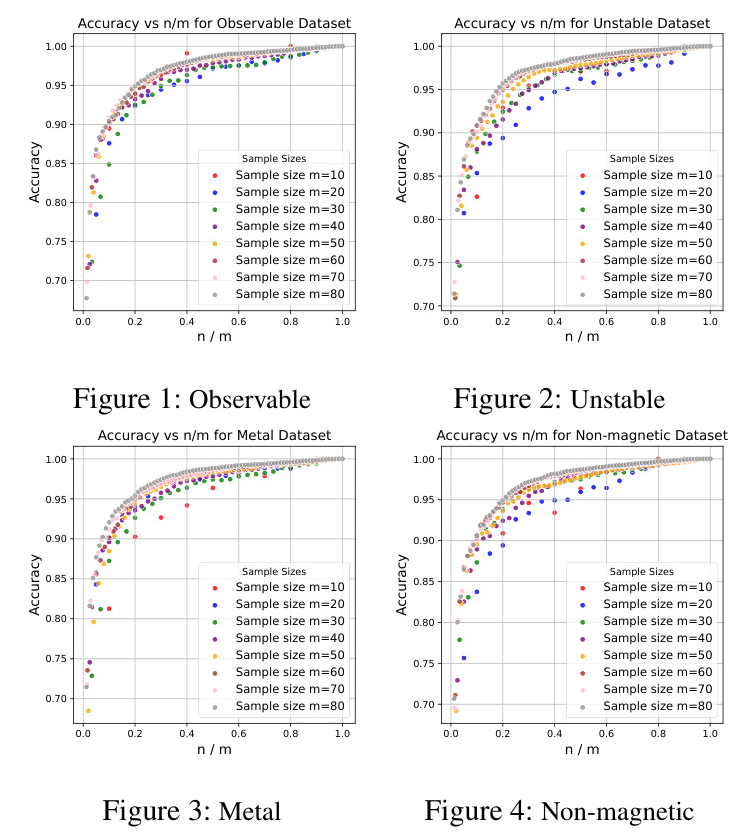
The experiments are conducted on a CloudLab machine with specific hardware configurations. The datasets used for evaluation are sourced from the Material Project and categorized into four distinct datasets: experimental Observable, stable, metal, and magnetic.
Results and Analysis
OPDR on Various Data Sets
The study evaluates the OPDR method on four datasets with distinct characteristics. The results indicate a strong positive correlation between accuracy and the ratio of the target dimension to the number of samples. The proposed OPDR algorithm performs consistently across multiple datasets, validating the initial hypotheses.
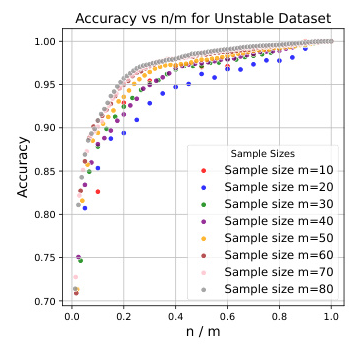
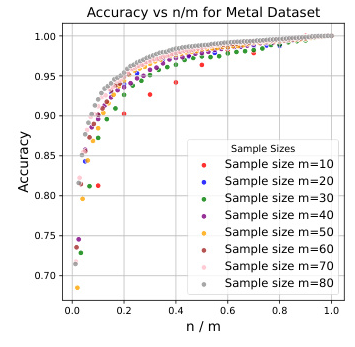
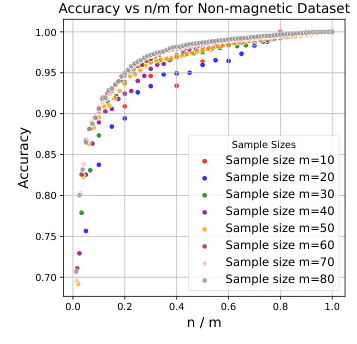
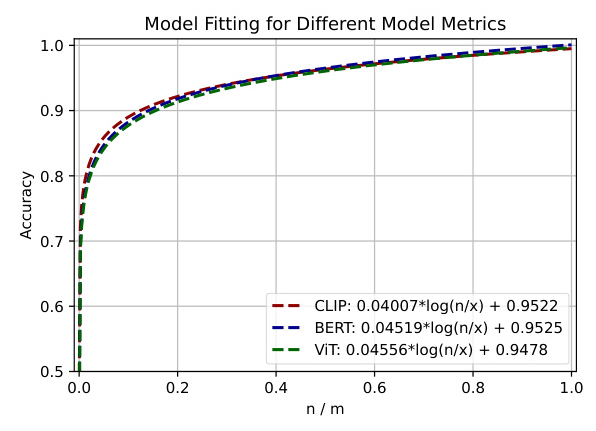
Influence of Embedding Models
The study explores the impact of using different transformer-based models (BERT, ViT, and CLIP) on the Observable dataset. The results show that the choice of model does not significantly alter the data structure, and the closed-form function is applicable to various neural network models.
Influence of Dimension-Reduction Methods
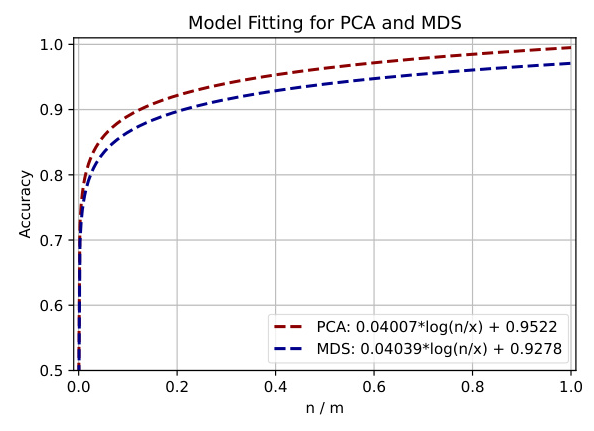
The study compares the performance of PCA and MDS on the same dataset. PCA is found to be more sensitive to changes in the ratio of the target dimension to the number of samples and achieves higher accuracy more quickly. The choice of dimension-reduction technique is crucial for achieving the desired level of accuracy.
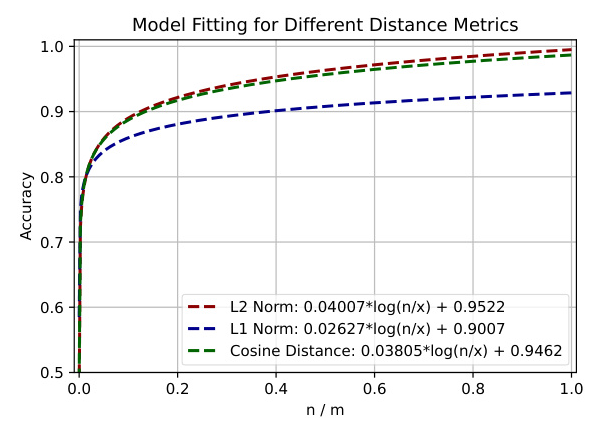
Influence of Distance Metrics
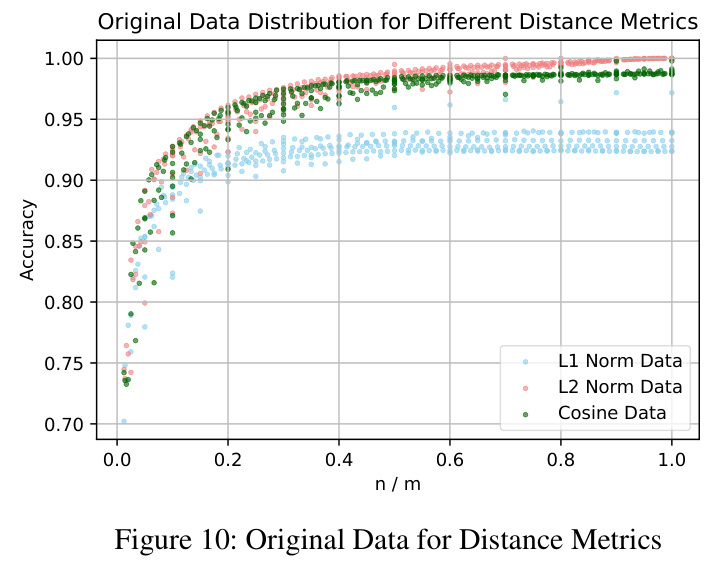
The study examines the impact of different distance metrics (L1 norm, L2 norm, and cosine distance) on the Observable dataset. The results show that while the overall data pattern remains constant, the choice of distance metric is crucial for specific scenarios.
Overall Conclusion
This paper addresses the challenge of high-dimensional embedding vectors in multimodal scientific data management by introducing the Order-Preserving Dimension Reduction (OPDR) method. Theoretical contributions include new measures to quantify the preservation of k-nearest neighbors and a closed-form function to reveal the relationship between space dimensionality, cardinality, and accuracy. The proposed method is implemented and evaluated on multiple datasets, demonstrating its effectiveness.
Future work will delve deeper into the theoretical foundation of the closed-form function and investigate the extensibility of the proposed method for production vector database systems.