

Authors:
Federico Simonetta、Rishav Mondal、Luca Andrea Ludovico、Stavros Ntalampiras
Paper:
https://arxiv.org/abs/2408.10260
Introduction
The Ricordi Archive, known as Archivio Storico Ricordi, is a treasure trove of historical documents amassed by the Italian publisher Ricordi. This archive is particularly renowned for its digitized manuscripts of distinguished opera composers such as Donizetti, Verdi, and Puccini. The digitization of these manuscripts has opened new avenues for musicological and historical research, making it easier to access and analyze these priceless documents.
In this study, the primary aim is to annotate the entire Ricordi Archive database with pertinent musical symbols, thereby improving the accessibility and discoverability of these manuscripts. To achieve this, an Optical Music Recognition (OMR) methodology was developed. OMR is a subfield of computer science dedicated to converting music notation from visual formats, such as scanned images or printed music sheets, into a digital form that can be manipulated by software. This study focuses on the challenges and solutions in automating the recognition of handwritten music scores from the Ricordi Archive.
Related Work
Evolution of Optical Music Recognition
OMR has evolved significantly over the years, particularly for printed music, thanks to advancements in image processing and machine learning. Early efforts in OMR relied heavily on rule-based systems, but contemporary strategies now use modern neural architectures. These architectures excel in feature extraction and help accurately identify and classify musical symbols across various datasets and notation styles.
Handwritten Music Recognition
Handwritten Music Recognition (HMR) adds an extra layer of complexity due to the unique styles and nuances inherent in individual handwriting. Recent methodologies suggest various strategies, including data augmentation and transfer learning, to enhance system performance and address the challenges specific to HMR. Convolutional Recurrent Neural Networks have been particularly effective in capturing both the spatial characteristics of the image and the sequential nature of music notation.
Datasets in OMR Research
The development of large-scale datasets has been fundamental to the advancement of OMR technology. Key resources include the MUSCIMA++ dataset, which comprises 140 pages of handwritten music scores meticulously annotated with over 91,000 symbols across 107 classes, and the DeepScores dataset, consisting of high-quality images of printed music divided into approximately 300,000 sheets of musical scores with nearly a hundred million small objects.
Research Methodology
Preprocessing
The creation of the dataset necessitated preliminary processing to identify pertinent objects and reduce the annotation effort in its initial phase. This process entailed the following steps:
- Staff Line Removal: A neural autoencoder-based algorithm was employed to identify staff lines. Given the distinct clarity of the staff lines in the 19th-century documents from the archive, this method proved highly effective.
- Blob Detection: The Difference of Gaussians (DoG) method was utilized to identify the musical symbols in the images. This step was tuned to be particularly sensitive to the ink regions, resulting in a large number of false positives to minimize the occurrence of false negatives.
- Rescale and Save: The grayscale images of the detected blobs were stored after rescaling their intensity values to [0, 255].
Annotation
A subset of the images was meticulously grouped and labeled by multiple individuals into several classes to distinguish between digitization noise and actual music elements. After assessing the consistency of the annotations, multiple neural network-based classifiers were trained to differentiate between the identified music elements.
Experimental Design
Dataset
The original core of the digitization campaign of the Ricordi Archive consisted of about 3,000 digitized images, mainly handwritten scores by Donizetti, Puccini, Verdi, and Respighi. The dataset was complemented by manual annotations, models, and source code used in these experiments, which are publicly accessible for replication purposes.
Classifiers
Several neural network-based classifiers were trained and evaluated to distinguish between the identified music elements. The primary objective was to evaluate the reliability of these classifiers, with the ultimate goal of using them for the automatic categorization of the remaining unannotated dataset.
Results and Analysis
Class Distribution
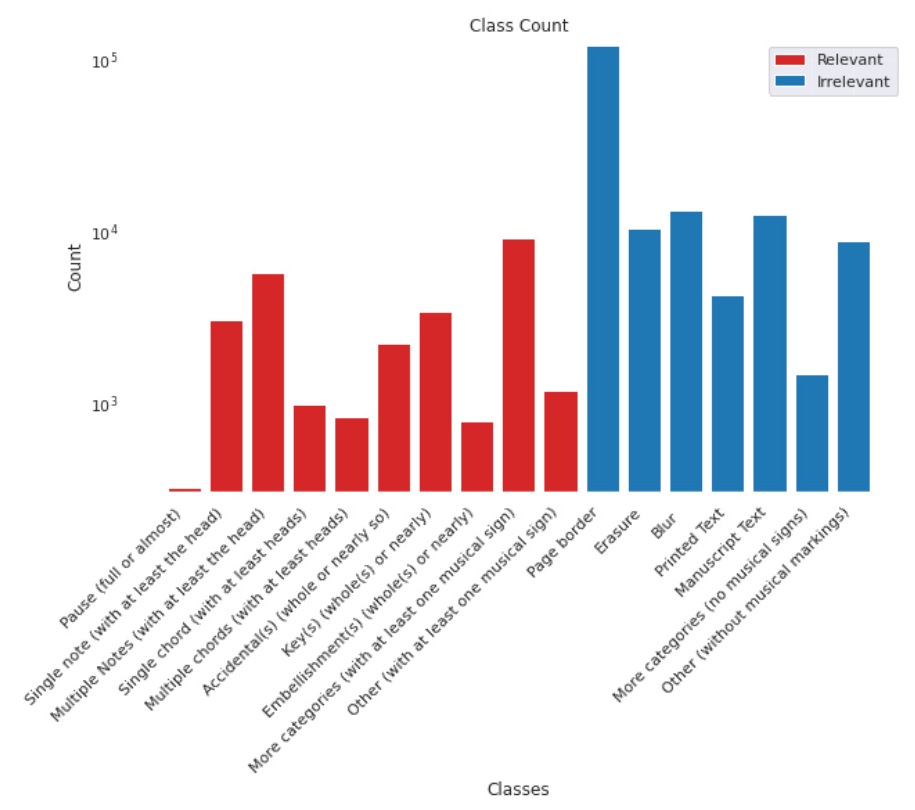
The class distribution of relevant and irrelevant elements in the dataset is shown in the following illustration:
Classifier Performance
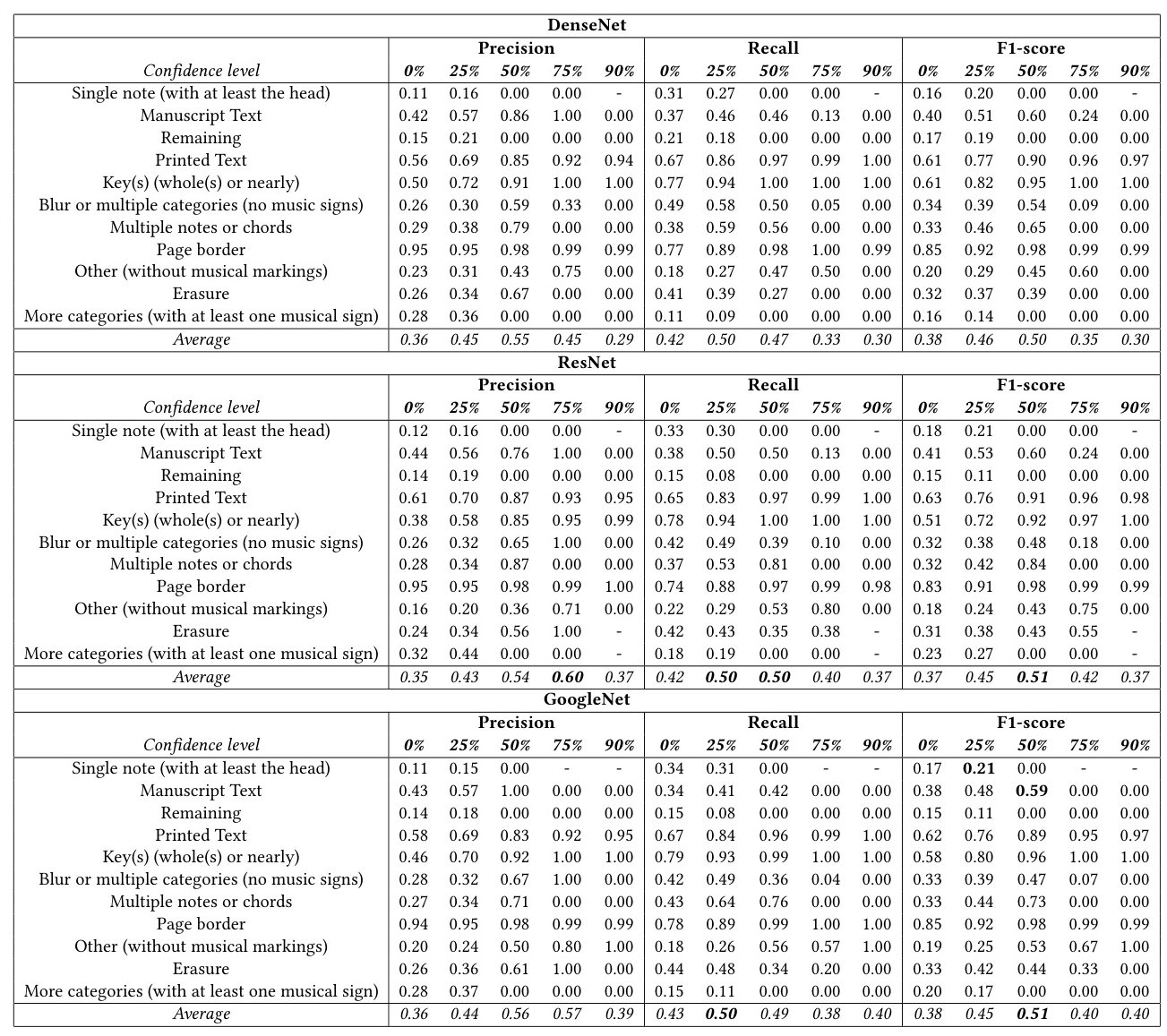
The performance of the classifiers was evaluated based on precision, recall, and F1-score at various confidence levels. The results for DenseNet, ResNet, and GoogleNet are summarized in the following tables:
Confidence Thresholds
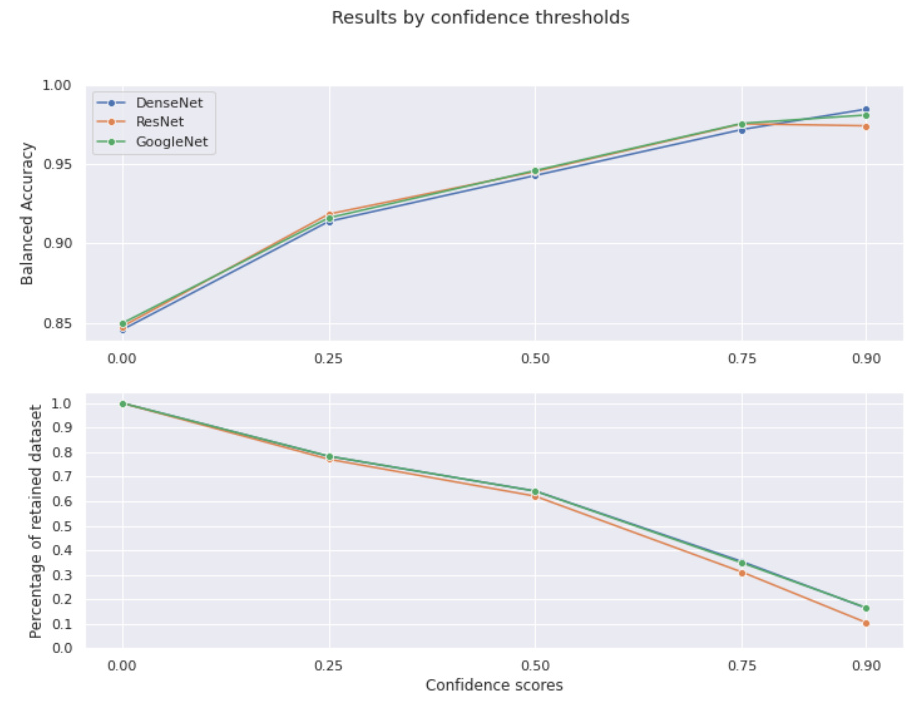
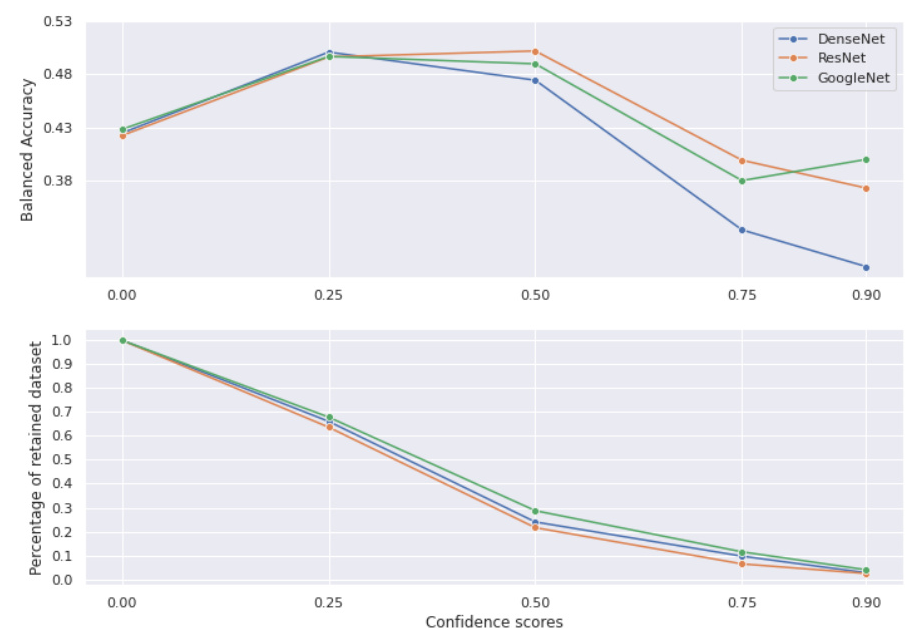
The balanced accuracy and the percentage of the retained dataset at different confidence thresholds are shown in the following graphs:

Overall Conclusion
This study addresses the challenges in Optical Music Recognition (OMR) by providing a new dataset of musical symbols from real-world annotated manuscripts and by training and evaluating several neural classifiers to distinguish between these symbols. The results demonstrate the effectiveness of modern neural architectures in accurately identifying and classifying musical symbols, paving the way for the automatic annotation of the entire Ricordi Archive. The publicly accessible dataset, models, and source code will facilitate further research and development in the field of OMR, contributing significantly to the accessibility and discoverability of historical musical manuscripts.