Authors:
Nicholas Pipitone、Ghita Houir Alami
Paper:
https://arxiv.org/abs/2408.10343
Introduction
In the rapidly evolving landscape of AI in the legal sector, Retrieval-Augmented Generation (RAG) systems have emerged as a crucial technology. These systems combine retrieval mechanisms with generative large language models (LLMs) to provide contextualized generation. However, a critical gap in the ecosystem remains unaddressed: the lack of a dedicated benchmark for evaluating the retrieval component in legal-specific RAG systems. Existing benchmarks, such as LegalBench, assess the reasoning capabilities of LLMs on complex legal questions but do not evaluate the retrieval quality over a large corpus, which is crucial for RAG-based systems.
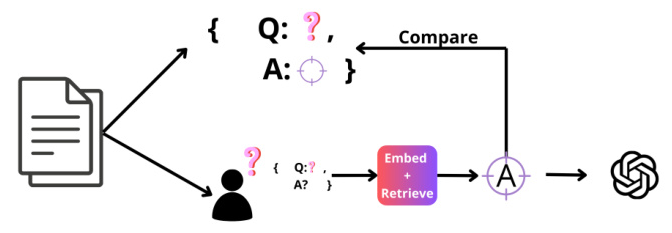
LegalBench-RAG aims to fill this gap by providing a benchmark specifically designed to evaluate the retrieval step of RAG pipelines within the legal space. This benchmark emphasizes precise retrieval by focusing on extracting minimal, highly relevant text segments from legal documents. The LegalBench-RAG dataset is constructed by retracing the context used in LegalBench queries back to their original locations within the legal corpus, resulting in a dataset of 6,858 query-answer pairs over a corpus of over 79 million characters, entirely human-annotated by legal experts.
Related Work
Retrieval-Augmented Generation (RAG)
A Retrieval-Augmented Generation (RAG) system utilizes a knowledge base containing a set of documents. Each document is segmented into chunks, which are then transformed into vector embeddings using a specialized embedding model. A user can submit a query, which is vectorized using the same embedding model. The system retrieves the top-k chunks most relevant to the query using similarity metrics such as cosine similarity. The retrieved chunks, together with the query and a system prompt, are processed by an LLM to generate the final response.
RAG Benchmarks
Several benchmarks have been created to assess the quality of RAG systems. Retrieval Augmented Generation Benchmark (RGB) and RECALL are two major contributions that assess the performance of RAG models. However, these benchmarks evaluate a simple case where the answer to a query can be retrieved and solved in a general context. More complex datasets such as MultiHop-RAG were introduced to assess the retrieval and reasoning capability of LLMs for complex multi-hop queries.
LegalBench
LegalBench was introduced to enable greater study of legal reasoning capabilities of LLMs. It is a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench focuses solely on evaluating the generation phase of the RAG pipeline, assessing how well the LLM can generate accurate responses given a certain context, task, and prompt.
Other Legal-Focused Benchmarks
Considerable research has been aimed at evaluating AI models’ abilities to undertake tasks traditionally handled by legal professionals. Initial studies focused on complex legal tasks, such as document review and case summarization. Subsequent research efforts have been directed towards the challenges posed by legal texts, such as extensive document lengths and specialized jargon.
Research Methodology
LegalBench-RAG Construction
LegalBench-RAG is constructed by transforming LegalBench into a retrieval benchmark. This involves tracing each text segment used in LegalBench back to its original location within the source corpus. The benchmark development is based on four datasets: Privacy Question Answering (PrivacyQA), Contract Understanding Atticus Dataset (CUAD), Mergers and Acquisitions Understanding Dataset (MAUD), and Contract Natural Language Inference (ContractNLI).
Starting Point: LegalBench
LegalBench focuses on evaluating the generation phase of the RAG pipeline. However, it does not benchmark the ability to extract the correct context from within a larger corpus. This limitation inspired the creation of LegalBench-RAG.
Tracing Back to Original Sources
To transform LegalBench into a retrieval benchmark, a comprehensive process was undertaken to trace each text segment used in LegalBench back to its original location within the source corpus. This involved searching in the original corpus for the context clauses and transforming annotations into queries.
Construction Process
Each of the four source datasets is converted into LegalBench-RAG queries through a slightly different process but follows a similar formula. A full LegalBench-RAG query is constructed using the format: “Consider (document description); (interrogative)”. Each individual query in LegalBench-RAG originates from an individual annotation in the source dataset.
Example Annotations
For instance, consider the Contract Understanding Atticus Dataset (CUAD) “Affiliate License-Licensee” task from LegalBench. The goal of this task is to classify if a clause describes a license grant to a licensee and the affiliates of such licensee. In LegalBench, a query appears as follows:
- Query: Does the clause describe a license grant to a licensee and the affiliates of such licensee?
- Clause: Supplier hereby grants Bank of America a nonexclusive, (…) restrictions of this Section.
- Label: Yes
In the original CUAD dataset, annotations appear as follows:
- Clause: Supplier hereby grants Bank of America a nonexclusive, (…) restrictions of this Section.
- File: CardlyticsInc 20180112 S-1 EX-10.16 11002987 EX-10.16 Maintenance Agreement1.pdf
- Label: Irrevocable Or Perpetual License
In LegalBench-RAG, queries appear as follows:
- Query: Consider the Software License, Customization, and Maintenance Agreement between Cardlytics, Inc. and Bank of America; Are the licenses granted under this contract non-transferable?
- Label (File): CardlyticsInc 20180112 S-1 EX-10.16 11002987 EX-10.16 Maintenance Agreement1.txt
- Label (Span): [44579, 45211]
Quality Control
Quality control is crucial for any RAG benchmark to ensure trust in recall and precision scores. All annotations were created by domain experts via the methods described by the four source datasets. The team conducted a thorough manual inspection of every data point in the dataset, employing a rigorous quality control process at three critical decision points: mapping annotation categories to interrogatives, mapping document IDs to descriptions, and selecting annotation categories.
Dataset Structure
The LegalBench-RAG benchmark is structured around two primary components: the original corpus and the QA pairs. The corpus includes the documents from the four source datasets, and the QA pairs are directly linked to the documents within the corpus. Each query is associated with a list of relevant snippets extracted from the different documents in the corpus that directly answer the query.
Descriptive Statistics
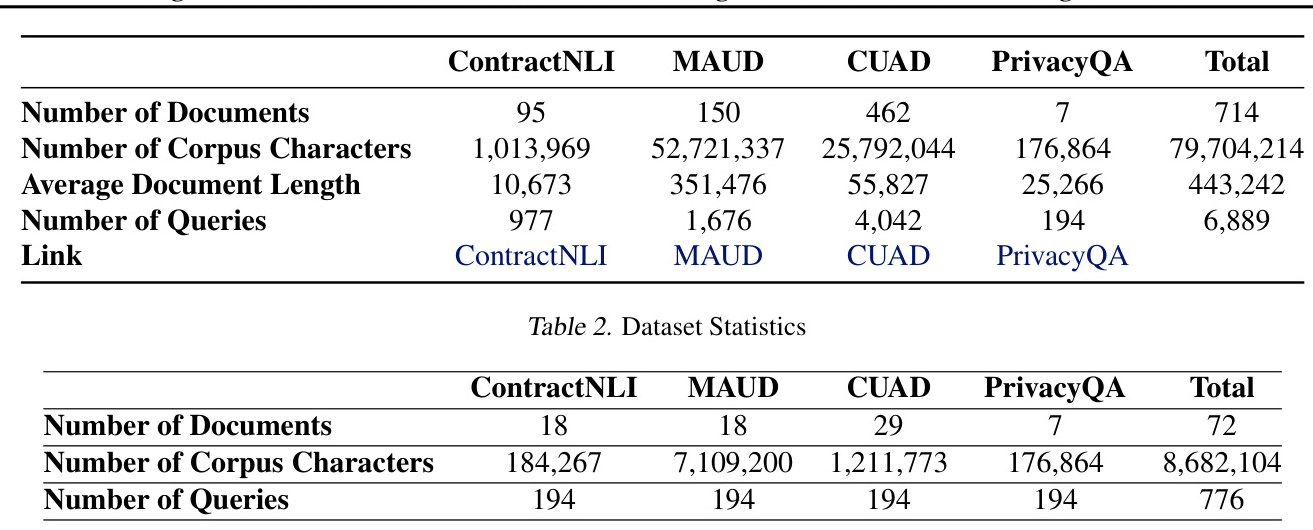
LegalBench-RAG is composed of four datasets and totals almost 80 million characters in its corpus across 714 documents. Each pair is annotated by legal experts, ensuring the highest accuracy and relevance for this benchmark. The dataset includes 6,889 question-answer pairs.
LegalBench-RAG and LegalBench-RAG-Mini
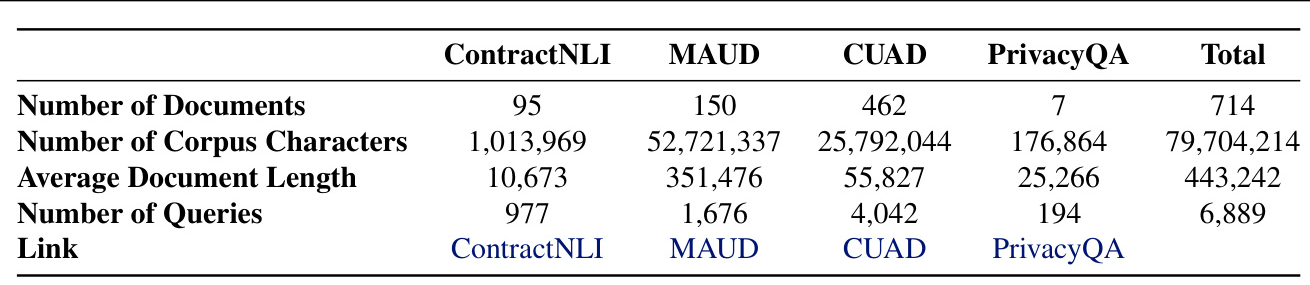
Given the size of LegalBench-RAG, a more lightweight version called LegalBench-RAG-mini was created. LegalBench-RAG-mini was created by selecting exactly 194 queries from each of the four datasets PrivacyQA, CUAD, MAUD, and ContractNLI, resulting in a dataset of 776 queries.
Significance of This Work
Creating datasets in the legal space is a difficult, time-consuming, and costly task. LegalBench-RAG is the first publicly available retrieval-focused legal benchmark and can be used for both commercial and academic purposes to assess the quality of the retrieval step of RAG pipelines on legal tasks. The introduction of this dataset allows the industry to more easily compare and iterate upon the plethora of RAG techniques available today by providing a standardized evaluation framework.
Limitations
The dataset includes NDAs, M&A agreements, various commercial contracts, and the privacy policies of consumer-facing online companies. However, it does not assess structured numerical data parsing or the parsing and analyzing of medical records. The queries in this benchmark are always answered by exactly one document, so it does not assess the ability of a retrieval system to reason across information found in multiple documents.
Experimental Design
Hyperparameters in RAG Pipelines
Implementing a RAG pipeline involves selecting various hyperparameters and making critical design decisions. These decisions can be adjusted to optimize performance. Key design decisions include pre-processing strategies, post-processing strategies, and the choice of embedding model.
Pre-Processing Strategies
Standard RAG pipelines typically generate embeddings from document chunks using an embedding model. The method by which documents are divided into these chunks is a crucial design consideration. Different strategies can be employed, ranging from simple fixed-size chunks to more sophisticated semantic chunking methods.
Post-Processing Strategies
Following retrieval, several critical design decisions must be made in the post-processing phase. One key parameter is the number of retrieved chunks that are subsequently input to the LLM. The decision to employ a reranker model on the retrieved chunks is another crucial consideration.
Other Design Decisions
The choice of the embedding model is a common critical decision. Embedding models can vary significantly in how well they represent textual content. A well-chosen embedding model can enhance retrieval accuracy by producing more meaningful and contextually relevant embeddings.
Experimental Setup
In this evaluation experiment, multiple RAG pipelines were implemented and benchmarked using LegalBench-RAG. Several experiments were conducted to study the impact of the chunking strategy and the effect of reranking the retrieved chunks using a specialized model. The embedding model used was OpenAI’s “text-embedding-3-large”, SQLite Vec was used as a vector database, and Cohere’s “rerank-english-v3.0” was used as the reranker model.
Variation of Preprocessing Splitting Strategies
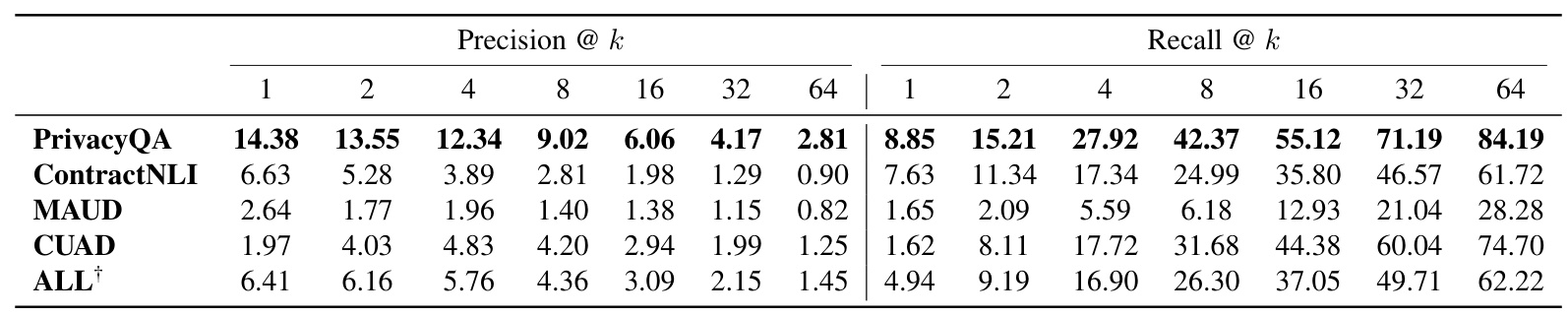
In the initial experiment, all hyperparameters were fixed, and the impact of transitioning from a naive chunking strategy to a Recursive Text Character Splitter (RTCS) was compared. The performance results for each dataset and varying values of k were presented.
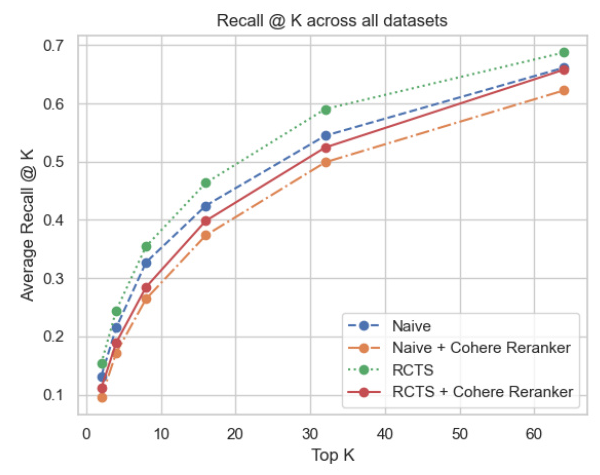
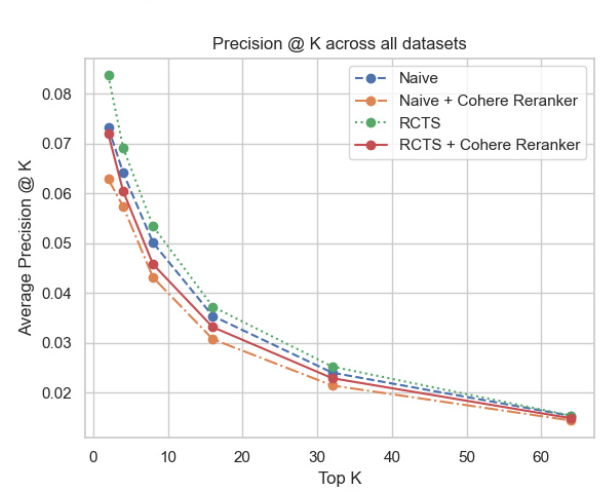
Variation of Postprocessing Method
A second experiment was conducted where all other hyperparameters were frozen, and only the post-processing method was changed. The results of this comparison were shown for using no reranking strategy and using Cohere’s Reranker model.
Results and Analysis
Results of the Experimentation
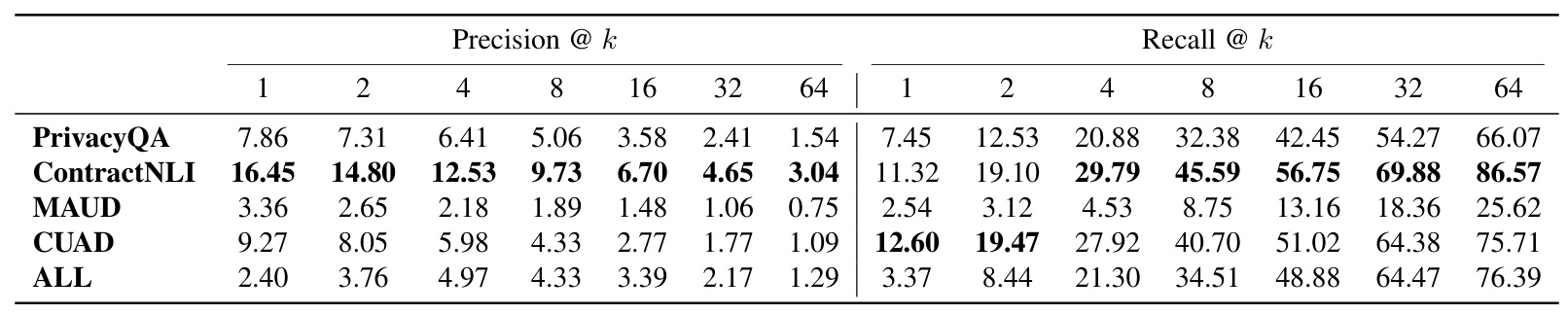
The overall evaluation results were computed for varying values of k between 1 and 64 for each of the four datasets and aggregated across all datasets. The experiment demonstrated that the most effective strategy was the Recursive Text Character Splitter (RTCS) without a reranker. Surprisingly, the performance of the Cohere Reranker was inferior compared to not using a reranker. Both precision and recall were highest with the RTCS + No reranker configuration.
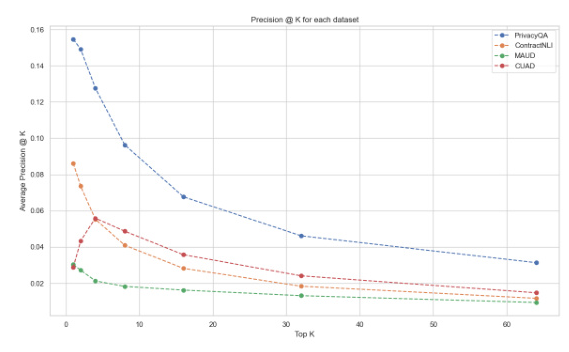
Comparison of the Four Datasets
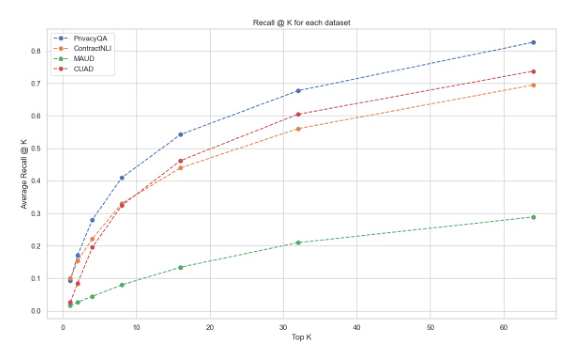
The performance of all methods across the four datasets was analyzed. The PrivacyQA dataset consistently yielded the highest scores across all methods, indicating that this dataset was easier for the models to interpret. In contrast, the MAUD dataset proved to be the most challenging, with the lowest precision and recall scores. The ContractNLI and CUAD datasets also presented unique challenges but were not as difficult as MAUD.
Future Work
The results highlight the need for more specialized and challenging legal benchmarks to effectively assess the quality of retrieval systems. Future research could explore fine-tuning or developing new rerankers specifically designed for legal text, potentially incorporating more legal-specific features or training on larger, more diverse legal corpora.
Overall Conclusion
LegalBench-RAG is the first benchmark specifically designed to evaluate the retrieval component of Retrieval-Augmented Generation (RAG) systems in the legal domain. By leveraging existing expert-annotated legal datasets and meticulously mapping question-answer pairs back to their original contexts, LegalBench-RAG provides a robust framework for assessing retrieval precision and recall. The creation of both LegalBench-RAG and its lightweight counterpart, LegalBench-RAG-mini, addresses a critical gap in the evaluation of RAG systems, particularly in contexts where legal accuracy is paramount.
Through a series of experiments, the effectiveness of different chunking strategies and post-processing methods was demonstrated, revealing that advanced chunking techniques like the Recursive Text Character Splitter (RTCS) significantly enhance retrieval performance. The results underscore the importance of specialized benchmarks that can accurately capture the nuances of legal text retrieval. LegalBench-RAG not only facilitates a more granular evaluation of retrieval mechanisms but also provides a foundation for further advancements in the development of RAG systems tailored to the legal field.
As legal AI continues to evolve, the availability of such targeted benchmarks will be crucial for driving innovation and ensuring the reliability of AI-driven legal tools.