

Authors:
Andong Chen、Lianzhang Lou、Kehai Chen、Xuefeng Bai、Yang Xiang、Muyun Yang、Tiejun Zhao、Min Zhang
Paper:
https://arxiv.org/abs/2408.09945
Introduction
The translation of classical Chinese poetry presents unique challenges due to its rich cultural and historical context, strict linguistic structure, and inherent aesthetic value. While large language models (LLMs) like ChatGPT have shown impressive performance in general translation tasks, the demand for translations that are not only adequate but also fluent and elegant has increased. This study introduces a benchmark specifically designed to evaluate the performance of LLMs in translating classical Chinese poetry into English, focusing on adequacy, fluency, and elegance. The study reveals that existing LLMs fall short in this task and proposes a Retrieval-Augmented Translation (RAT) method to enhance translation quality. Additionally, a new evaluation metric based on GPT-4 is introduced to better assess translation quality.
Related Work
Poetry Machine Translation
Initial attempts at poetry machine translation utilized phrase-based systems to translate French poetry into metrical English poetry, demonstrating the ability to adhere to rhythmic and rhyming rules (Genzel et al., 2010). However, advanced machine translation systems trained on non-poetry data struggle to preserve the original style of poetry (Chakrabarty et al., 2021). To address this, some studies have generated diverse styles by embedding specific styles into the decoder (Zhang et al., 2018; Liu and Wang, 2012). For classical Chinese poetry, a Hybrid Machine Translation (HBMT) model was proposed to improve semantic and syntactic accuracy (Chakrawarti and Bansal, 2022). Recently, ChatGPT has been used to translate modern poems from English to Chinese (Wang et al., 2024).
Chinese Classical Poetry Dataset
Several open datasets for Chinese classical poetry exist. Chen et al. (2019) published a fine-grained emotional poetry corpus containing 5,000 Chinese quatrains. Yutong et al. (2020) released a dataset with 3,940 quatrains annotated with themes and emotions. Liu et al. (2020) collected a parallel bilingual dataset of ancient and modern Chinese, aligning lines using a string matching algorithm. This study introduces the first dataset for English translation of Chinese classical poetry, aimed at evaluating translation performance in terms of adequacy, fluency, and elegance.
Research Methodology
Classical Chinese Poetry Dataset Construction
The dataset construction involved collecting classical Chinese poetry data and corresponding English translations from online resources. The database contains 1,200 poems from Tang, Song, and Yuan dynasties. After manual screening, 608 poems were selected as gold standards for translation source and target alignment. The dataset statistics are shown in Table 1.

Adequacy in Sentence-Level Translation
To construct the test set, sentences containing historical knowledge and commonsense were selected from the collected data. The test set consists of 500 sentences, each represented as a triplet (s, tc, te), where s is the source sentence, tc is the correct translation, and te is the incorrect translation. This setup ensures diversity and requires disambiguation based on context, historical background, and commonsense.

Classical Chinese Poetry Knowledge Base
A knowledge base consisting of 30,000 entries was collected, including classical Chinese poems, historical background, dynasty names, modern Chinese translations, author introductions, modern Chinese analysis, and poetry type information. This knowledge base enhances translation quality by providing rich historical and cultural nuances.
Human Annotation
Human annotators assessed the quality of translation parallel sentence pairs to eliminate any problematic instances, ensuring high data quality.
Experimental Design
Proposed Method: RAT
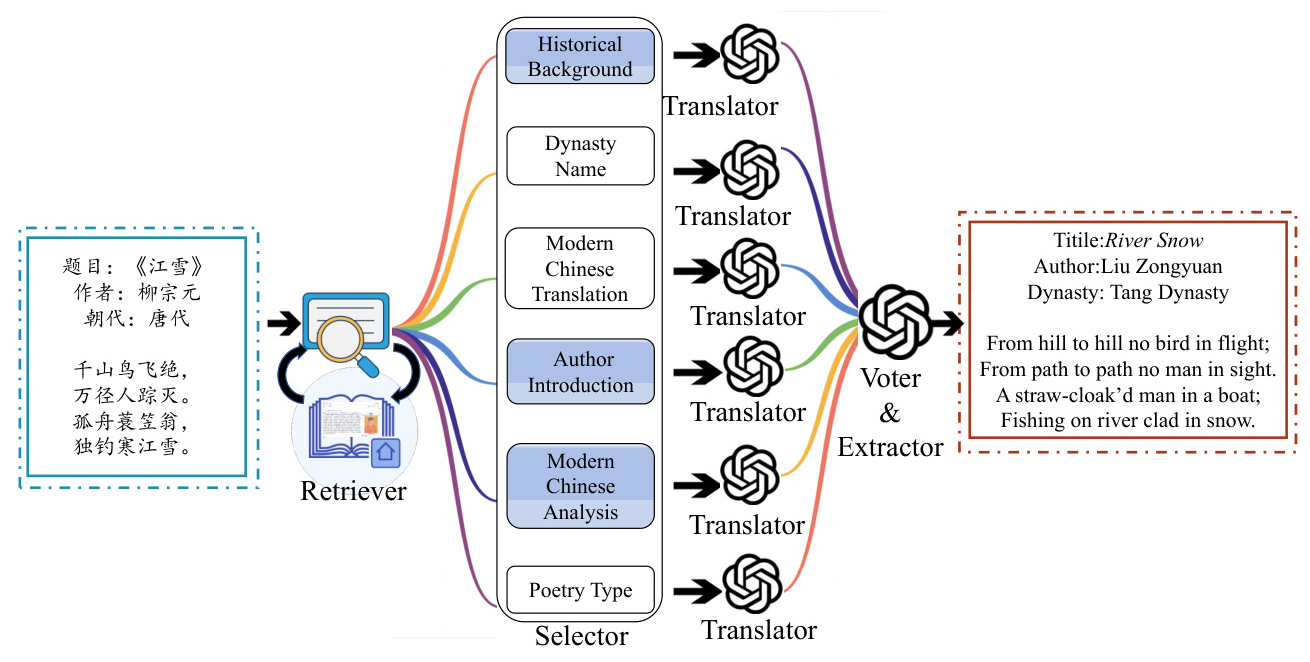
The RAT method enhances translation outcomes by leveraging contextual information from the Classical Chinese Poetry Knowledge Base. It involves two workflows:
- First Workflow: The Retriever module retrieves relevant knowledge from diverse perspectives, and the Selector module filters the retrieved knowledge to enhance its relevance to the poetry.
- Second Workflow: The Translator module translates different English verses based on the retrieved knowledge. The Voter module votes on each translated sentence to determine the optimal translation, and the Extractor module extracts the final translation results.
Evaluation Methods
Evaluation Criteria
The translation quality is evaluated based on three aspects: adequacy, fluency, and elegance. Specific evaluation methods include:
- Adequate: Accuracy (Acc) focuses on the precision of each element in the translation, maintaining correct semantic and logical relationships.
- Fluent: Beauty of Sound (BS) examines harmonious sound, precise wording, adherence to metrical rules, and smooth rhythm. Beauty of Form (BF) evaluates consistency with the source poem’s structure.
- Elegant: Beauty of Meaning (BM) assesses the depth and richness of the translation, focusing on themes, emotions, and messages.

LLM-based Classical Poetry Metric
An LLM-based evaluation method was developed to assess translation quality. A 1-5 scoring prompt helps LLM focus on translation quality in terms of Beauty of Sound (LLM-BS). The average scores of BF, BM, and BS (LLM-Avg) are calculated to evaluate overall translation performance.
Traditional Automatic Evaluation
Traditional metrics like COMET, BLEURT, and BLEU are used to evaluate translation methodology.
Results and Analysis
Can LLM Evaluate Chinese Classical Poetry?
The evaluation results indicate that LLMs can effectively evaluate the translation quality of idioms across different language pairs. LLM-based metrics show higher consistency with human evaluations compared to traditional metrics like BLEU, COMET, and BLEURT.
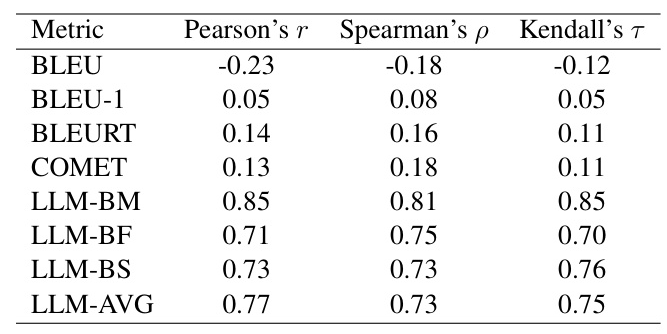
Main Results
The RAT method consistently outperforms other comparative methods across all evaluation metrics, demonstrating its effectiveness. Closed-source models perform better than open-source models, suggesting that richer pre-training data enables higher-quality translations. The retrieval-based knowledge in RAT provides more accurate information, further improving translation quality.
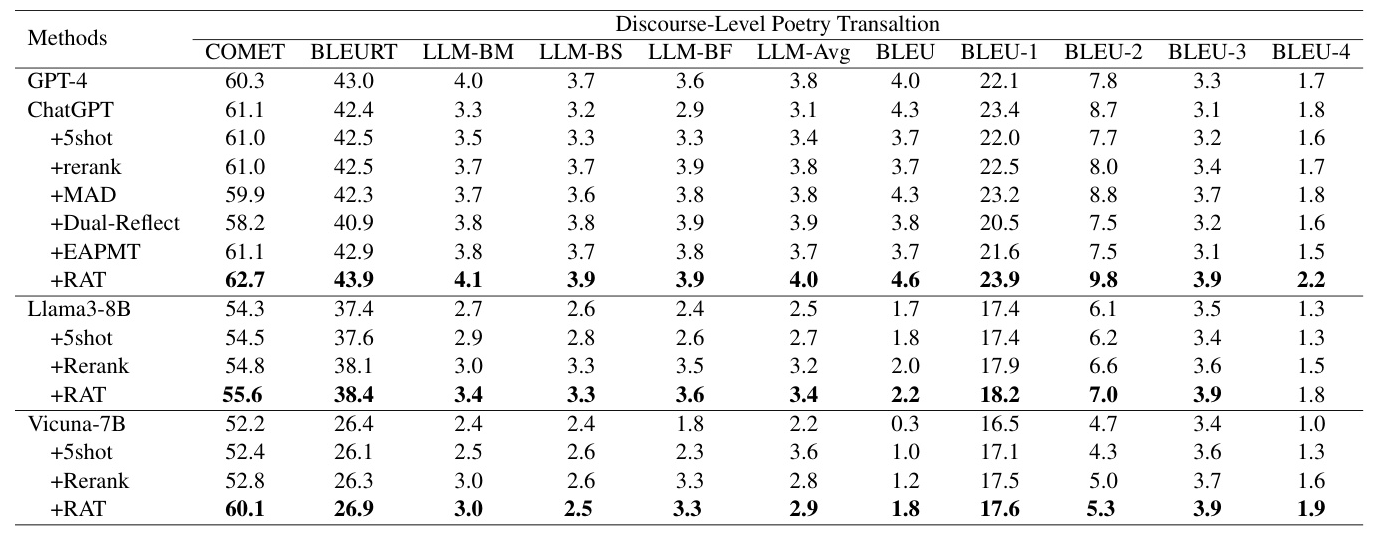
Evaluation of Adequacy
RAT performed the best in ambiguity resolution accuracy and received the highest score in human evaluation, indicating excellent translation quality.
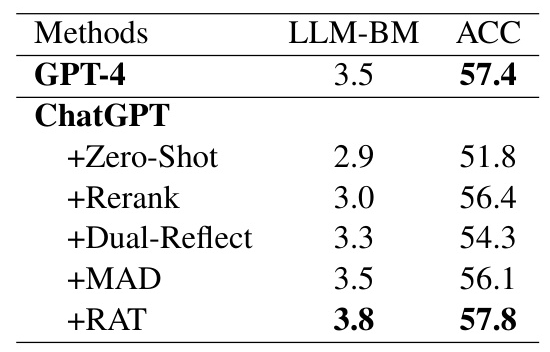
LLM-based Metric Consistency
Pairwise correlation tests between human evaluation results and LLM-based results show high consistency, demonstrating the rationality of the evaluation settings for LLM-BS, LLM-B, LLM-BM, and LLM-AVG.
Impact of Different Knowledge on Translation Performance
Knowledge of modern Chinese translation contributed the most to performance enhancement, indicating significant challenges in directly translating classical Chinese poetry.
Translation Challenges Across Different Types of Classical Chinese Poetry
Tang poetry is relatively easier to translate compared to Song and Yuan poetry, likely due to its stricter format and fewer words. The translation of poetic structure and rhythm remains a significant challenge for LLMs.
Overall Conclusion
This study reveals the challenges LLMs face in translating classical Chinese poetry, particularly in cultural knowledge, fluency, and elegance. The proposed RAT method and GPT-4-based evaluation metric improve translation quality. This comprehensive evaluation exposes the limitations of LLMs and suggests areas for improvement, aiming to inspire better culturally informed translations.