

Authors:
Jiandong Jin、Xiao Wang、Qian Zhu、Haiyang Wang、Chenglong Li
Paper:
https://arxiv.org/abs/2408.09720
Introduction
Pedestrian Attribute Recognition (PAR) is a critical task in the fields of Computer Vision (CV) and Artificial Intelligence (AI). It involves mapping pedestrian images to semantic labels such as gender, hairstyle, and clothing using deep neural networks. Despite significant advancements, current PAR models still face challenges in complex real-world scenarios due to factors like low illumination, motion blur, and complex backgrounds. Moreover, existing datasets have reached performance saturation, and there has been a lack of new large-scale datasets in recent years. To address these issues, this study introduces a new large-scale, cross-domain pedestrian attribute recognition dataset named MSP60K, along with an innovative Large Language Model (LLM) augmented PAR framework called LLM-PAR.
Related Work
Pedestrian Attribute Recognition
Pedestrian Attribute Recognition aims to classify pedestrian images based on predefined attributes. Current methods can be broadly categorized into prior-guidance, attention-based, and visual-language modeling approaches. Attention mechanisms have been used to localize attribute-relevant regions, while some researchers have incorporated prior enhancement techniques or supplementary neural networks to model relationships effectively. However, these methods often struggle to represent connections involving rare attributes.
Benchmark Datasets for PAR
The most commonly used PAR datasets include PETA, WIDER, RAP, and PA100K. These datasets have limitations such as random segmentation, limited background variation, and lack of significant style changes among pedestrians. The newly proposed MSP60K dataset aims to address these limitations by providing a large-scale, cross-domain dataset with diverse backgrounds and attribute distributions.
Vision-Language Models
With the rapid development of natural language processing, many large language models (LLMs) such as Flan-T5 and LLaMA have emerged. These models have shown significant improvements in vision understanding and text generation. However, challenges such as low-resolution image recognition and fine-grained image captioning still exist. The proposed LLM-PAR framework leverages LLMs to enhance pedestrian attribute recognition by generating textual descriptions of the image’s attributes.
Research Methodology
Overview
The proposed LLM-PAR framework consists of three main modules: a multi-label classification branch, a large language model branch, and model aggregation. The framework first extracts visual features of pedestrians using a visual encoder. Then, a Multi-Embedding Query Transformer (MEQ-Former) is designed to extract specific features for different attribute groups. These features are integrated into instruction embeddings and fed into the large language model to generate pedestrian captions. Finally, the classification results from the visual features and the language branch are aggregated to produce the final classification results.
Multi-Label Classification Branch
Given an input pedestrian image, the image is partitioned into patches and projected into visual tokens. These tokens are fed into a visual encoder to extract global visual representation. A newly designed MEQ-Former extracts specific features from different attribute groups. The attribute group features are integrated into instruction embeddings and fed into the large language model for pedestrian attribute description.
Large Language Model Branch
The LLM branch generates textual descriptions of the image’s attributes as an auxiliary task. This branch assists in the learning of visual features through the generation of accurate textual descriptions, thereby achieving high-performance attribute recognition. The text tokens are also fed into an attribute recognition head and ensemble with classification logits.
Model Aggregation for PAR
The algorithmic framework outputs pedestrian attribute results and complete text passages to describe the attributes of a given pedestrian. To leverage the strengths of these two branches, an algorithm integration module is designed to achieve enhanced prediction results. Various aggregation strategies, such as mean pooling and max pooling, are explored to fuse the results from the visual and language branches.
Experimental Design
MSP60K Benchmark Dataset
The MSP60K dataset consists of 60,122 images with 57 attribute annotations across eight scenarios. The dataset includes images from different environments, such as supermarkets, kitchens, construction sites, ski resorts, and various outdoor scenes. The images are split according to two protocols: random split and cross-domain split. Synthetic degradation is also conducted to simulate real-world challenging scenarios.

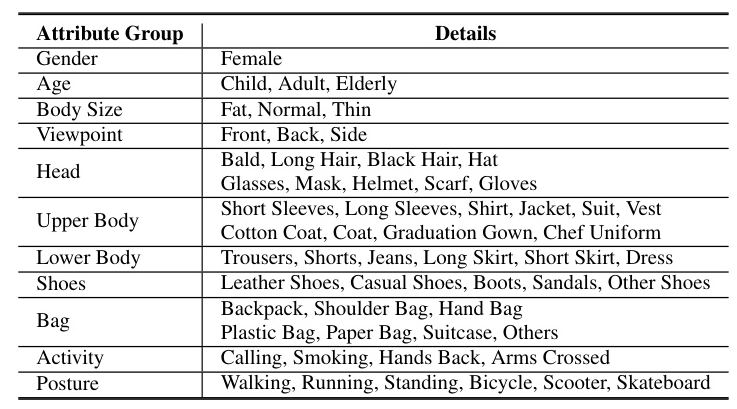
Attribute Groups and Details
The attributes in the MSP60K dataset are categorized into 11 groups: gender, age, body size, viewpoint, head, upper body, lower body, shoes, bag, body movement, and sports information.
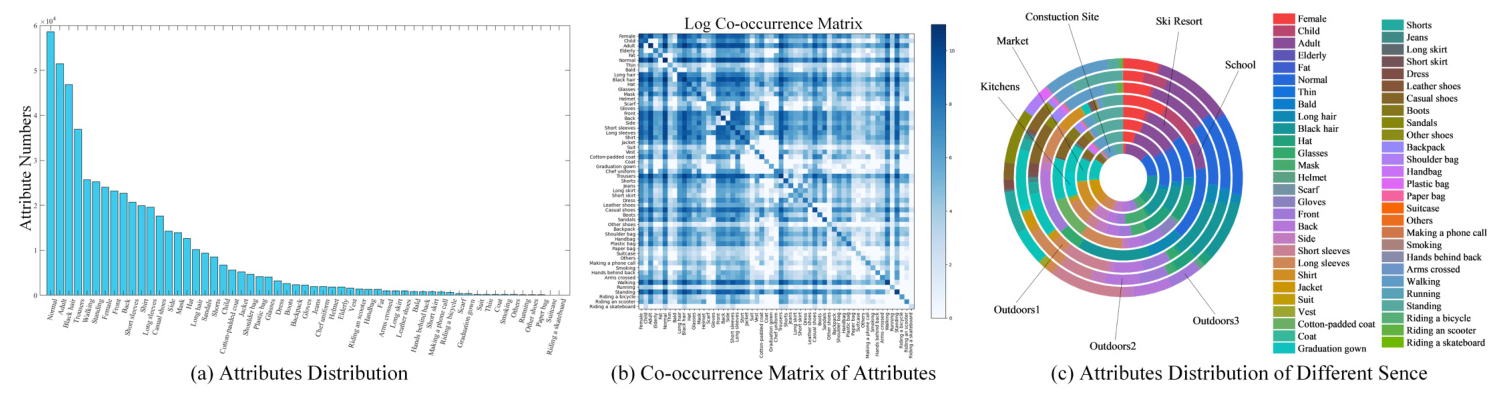
Statistical Analysis
The dataset offers a comprehensive platform for evaluating PAR methods with its extensive size and diverse conditions. The dataset exhibits a long-tail effect, similar to existing PAR datasets, and reflects real-world attribute distributions.
Benchmark Baselines
The evaluation covers a variety of methods, including CNN-based, Transformer-based, Mamba-based, human-centric pre-training models, and visual-language models for PAR.
Results and Analysis
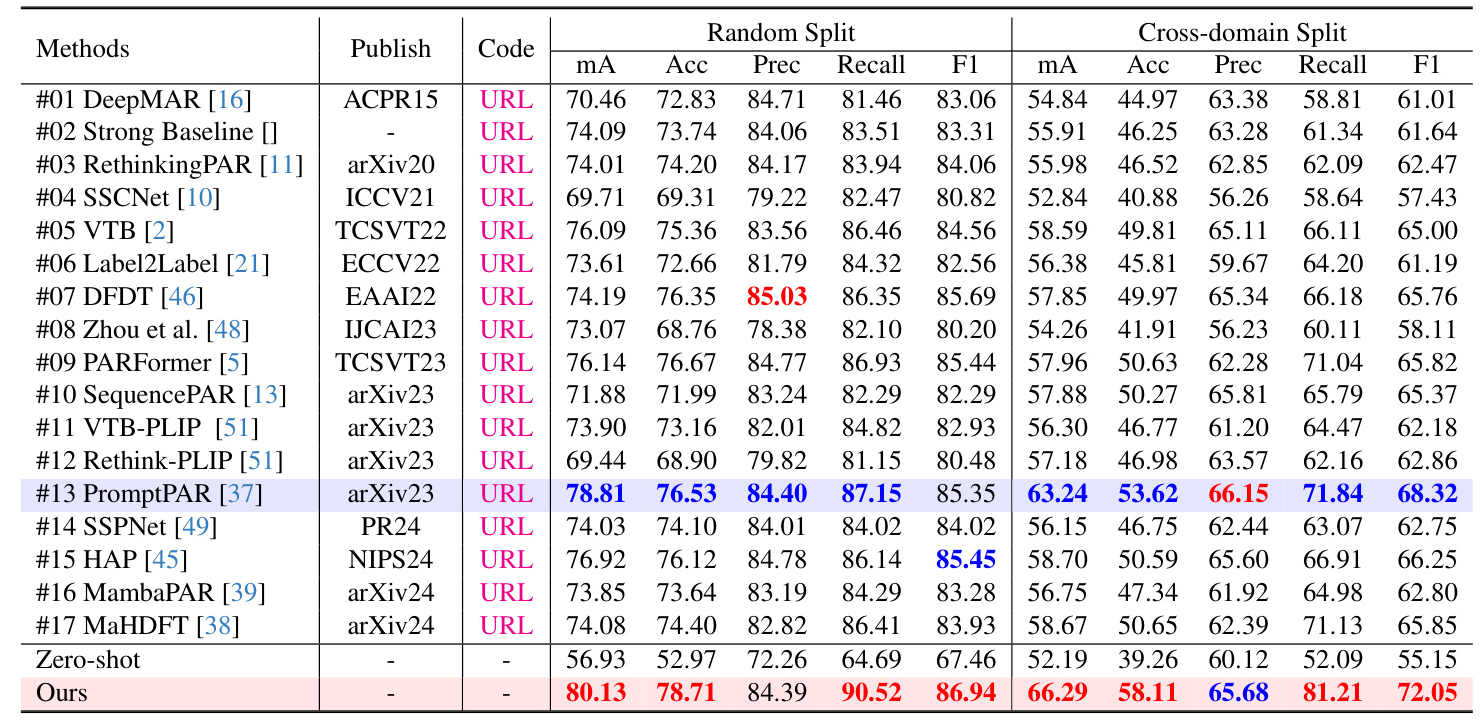
Comparison on Public PAR Benchmarks
The proposed LLM-PAR framework is evaluated on the MSP60K dataset and other publicly available datasets such as PETA, PA100K, and RAPv1. The results demonstrate that LLM-PAR achieves state-of-the-art performance on multiple PAR datasets.
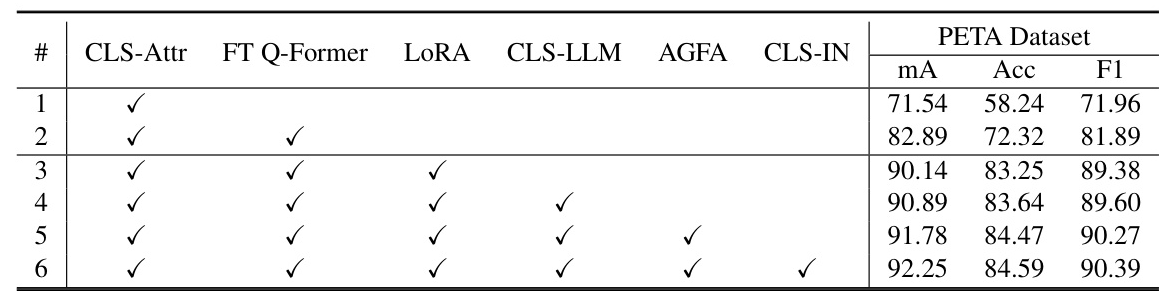
Component Analysis
Ablation experiments are conducted to analyze the contributions of different components in the LLM-PAR framework. The analysis reveals that the AGFA module, LLM branch, and CLS-IN module significantly improve the recognition performance.
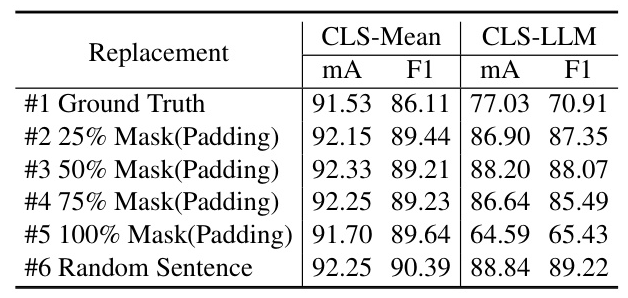
Ablation Study
Detailed analysis experiments are conducted on the main modules of LLM-PAR, including ground-truth mask strategies, the number of AGFA layers, the length of PartQ, the aggregation strategy of three branches, and different MLLMs.
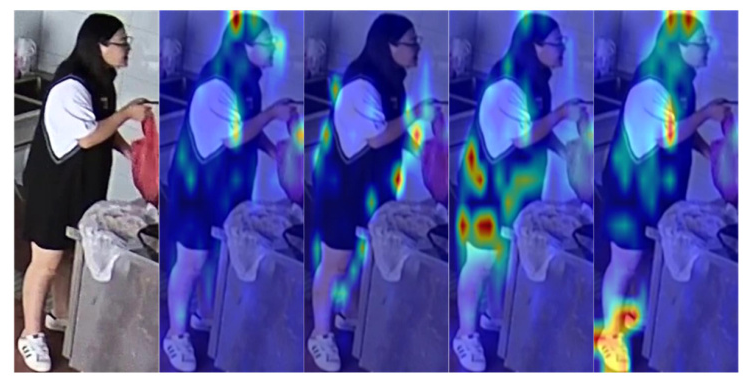
Visualization
The recognition results and feature maps demonstrate the effectiveness of the LLM-PAR framework in accurately recognizing specific attributes of pedestrians.
Overall Conclusion
This paper introduces the MSP60K dataset, a new large-scale, cross-domain dataset for pedestrian attribute recognition. The dataset addresses the limitations of existing PAR datasets by providing diverse backgrounds and attribute distributions. The proposed LLM-PAR framework leverages a pre-trained vision Transformer backbone, a multi-embedding query Transformer for partial-aware feature learning, and a large language model for ensemble learning and visual feature augmentation. The experimental results demonstrate the effectiveness of the proposed framework, achieving state-of-the-art performance on multiple PAR datasets. Future work will focus on expanding the dataset and designing lightweight models to achieve a better balance between accuracy and performance.
Code:
https://github.com/event-ahu/openpar