

Authors:
Narayanan PP、Anantharaman Palacode Narayana Iyer
Paper:
https://arxiv.org/abs/2408.09434
HySem: A Context Length Optimized LLM Pipeline for Unstructured Tabular Extraction
Introduction
In the pharmaceutical industry, regulatory compliance reporting often involves detailed tables that are under-utilized beyond their initial compliance purposes due to their unstructured format. Extracting and semantically representing this tabular data is challenging due to the diverse presentations of tables. Large Language Models (LLMs) have shown potential for semantic representation but face challenges related to accuracy and context size limitations. This study introduces HySem, a pipeline that employs a novel context length optimization technique to generate accurate semantic JSON representations from HTML tables. This approach is particularly designed for small and medium pharmaceutical enterprises, focusing on cost and privacy considerations.
Related Work
Challenges in Tabular Data Extraction
Tables are a fundamental method for presenting structured information across various industries, including regulatory information in the pharmaceutical industry and financial reports for businesses. Some inherent challenges in tables include heterogeneity, sparsity, context-based interconnection, and lack of prior knowledge. Recent advancements in LLMs have shown promise in addressing these challenges for various table-related tasks such as entity matching, data imputation, tabular Q&A, schema augmentation, serialization, table manipulation, table understanding, prompt engineering, and table RAG.
Existing Solutions
Several works have investigated the performance of LLMs for different input tabular formats such as JSON, HTML tables, and Markdown. However, extracting complex tabular data from semi-structured sources and providing a semantic representation remains a hard problem due to the lack of standards in tabular data representations. The language understanding ability of LLMs presents an immense opportunity to develop semantics-driven representations, but LLMs are prone to hallucinations, accuracy challenges, and syntax errors.
Research Methodology
Key Goals
The research goals for HySem were formulated in accordance with industry needs, particularly for small and medium pharmaceutical enterprises:
1. On-Premise Model Deployment: Models should be run on-premise due to data security considerations.
2. Commodity Hardware Compatibility: Models should operate on commodity hardware with widely available GPUs.
3. Model Size Limitation: The model size should be less than 10 billion parameters to ensure compatibility with GPUs supporting 16 GB RAM.
4. Open-Source Software Stack: The software stack should leverage open-source tools and models.
5. Maximized Extraction Accuracy: Extraction accuracy should be maximized to reduce costly human correction efforts.
Contributions
- Context Optimizer: A novel context optimizer that rewrites input text to significantly reduce the token count.
- Semantic Synthesizer: A custom fine-tuned model that generates accurate semantic representations of HTML tables.
- Automated Syntax Correction: An automated correction system to address syntax errors.
- Evaluation Methodology: A novel evaluation methodology that measures the performance of the pipeline using both intrinsic and extrinsic metrics.
Experimental Design
HySem Pipeline Components
HySem is composed of three main components: Context Optimizer Subsystem (ACO), Semantic Synthesizer (ASS), and Syntax Validator (ASV).
Context Optimizer Subsystem
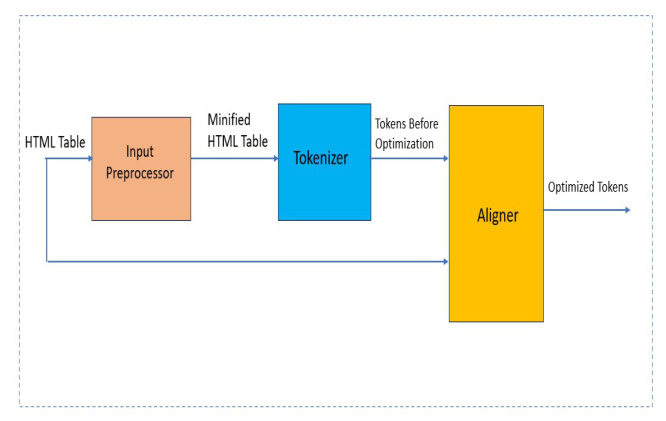
The limited context size of LLMs constrains their ability to effectively process extensive tables. The Context Optimizer employs a novel pre-processing methodology for optimizing the context window utilized by HTML tables, enabling the processing of large tables. It includes an encoding phase that minimizes token sequences and a decoding phase that restores the original lexicon used in the table.
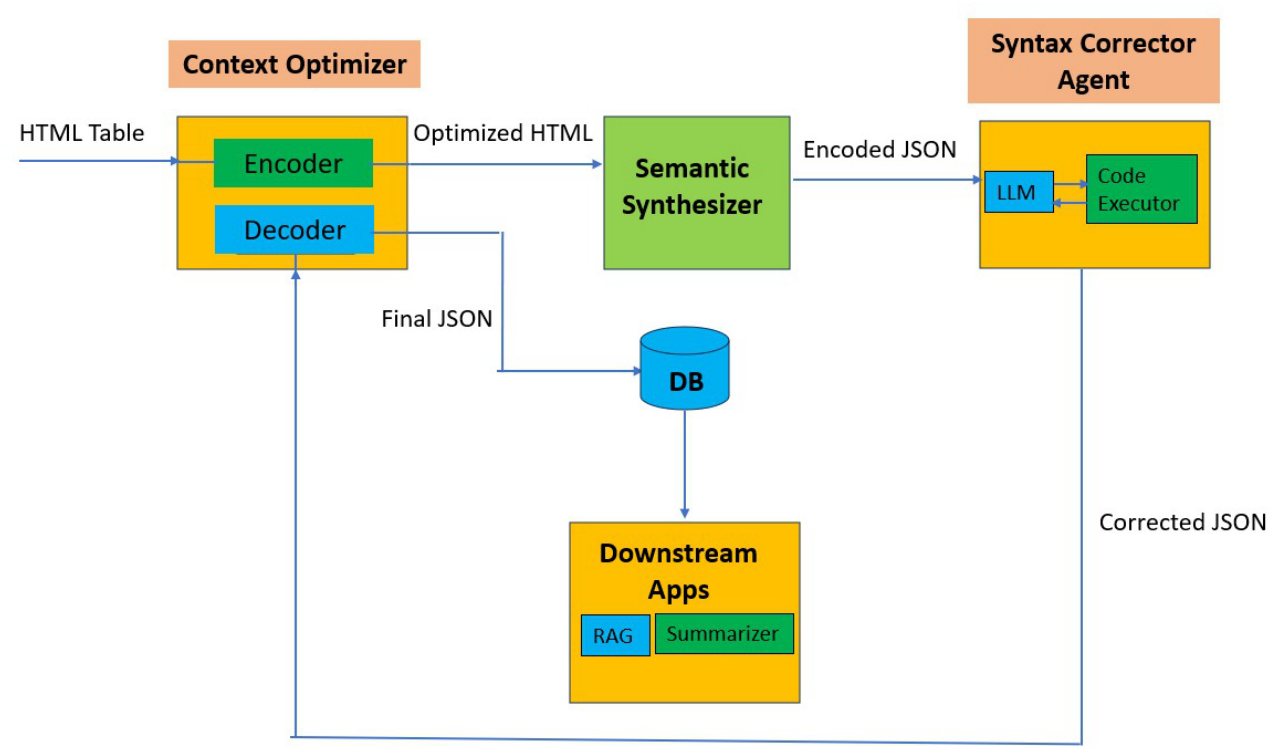
Semantic Synthesizer
HTML tables are highly varied and arbitrary, featuring elements such as row spans, column spans, multi-level headers, nested tables, and diverse data types. The Semantic Synthesizer uses an LLM fine-tuned with a manually labeled dataset to transform HTML tables into semantic JSON.
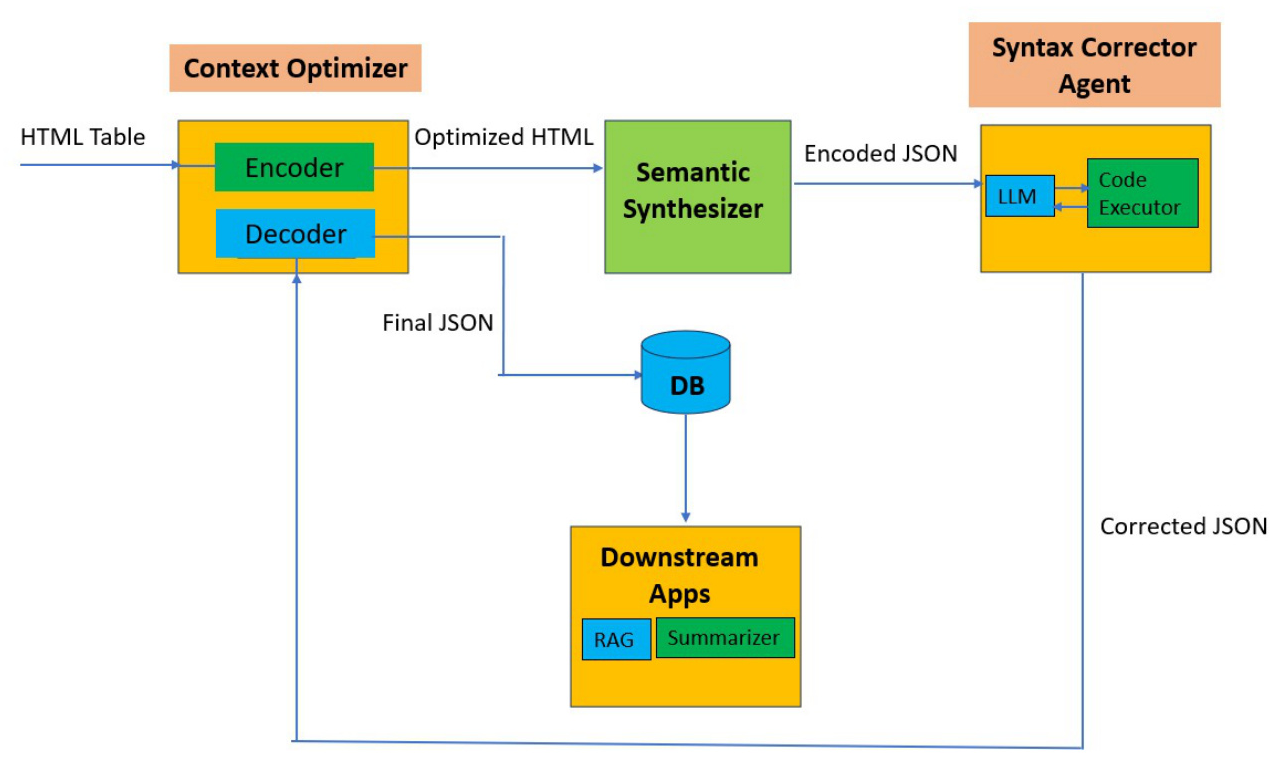
Syntax Validator
Syntax errors in the LLM-generated JSON output render the table unusable for further processing. The Syntax Validator uses a reflective agentic framework to iteratively refine the JSON output until a syntactically valid result is achieved.
Dataset and Fine-Tuning
The dataset for fine-tuning the Semantic Synthesizer includes HTML tables and their corresponding semantic JSON annotations. Open-sourced datasets such as PubTabNet and FinTabNet were used, along with manually curated annotations for proprietary customer-supplied data.
Results and Analysis
Evaluation Methodology
The evaluation of HySem involves intrinsic and extrinsic methods to measure content and semantic accuracy.
Intrinsic Evaluation
Intrinsic evaluation assesses the representation of content from HTML cells in the generated JSON. The Intrinsic Score (ISC) is computed based on the presence of HTML cell contents in the JSON output.
Extrinsic Evaluation
Extrinsic evaluation assesses the semantic structure of the JSON by evaluating its ability to answer targeted questions. The Extrinsic Score (ESC) is computed based on the accuracy of answers generated from the JSON output.
Performance Comparison
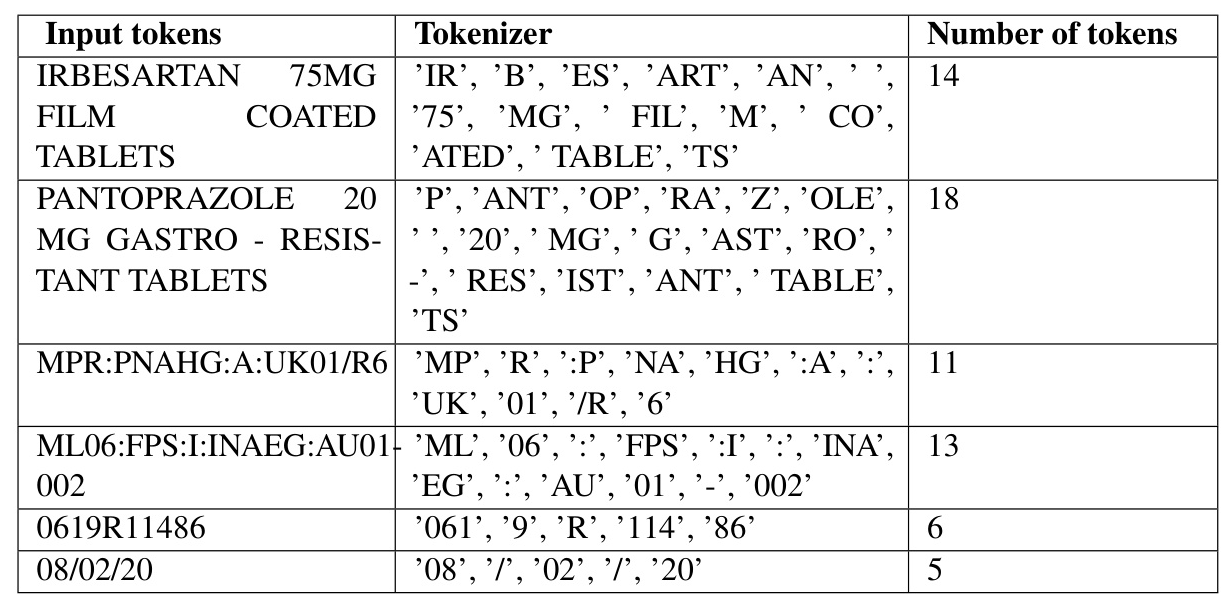
HySem was benchmarked against popular open-source models and GPT-4o. HySem achieved over 25% higher accuracy on the intrinsic score and 3.97% higher on the extrinsic score compared to Meta-Llama-3-8B-Instruct. The Context Optimizer showed impressive reductions in token count, resulting in a reduced LLM inference throughput.
Overall Conclusion
HySem successfully implements a context length optimized LLM pipeline for generating semantic JSON output from HTML tables. The Context Optimizer significantly improves context utilization, enabling the processing of larger tables. HySem offers substantial advantages such as on-premise deployment on commodity hardware, cost-effectiveness, and enhanced data privacy. Future work includes supporting even larger tables, improving processing speed, and building custom models for other verticals.