Authors:
Shiqi Wang、Zhengze Zhang、Rui Zhao、Fei Tan、Cam Tu Nguyen
Paper:
https://arxiv.org/abs/2408.09385
Introduction
Large Language Models (LLMs) have revolutionized natural language processing (NLP) by providing unprecedented capabilities in understanding, generating, and translating human language. However, aligning these models with human preferences, such as truthfulness, harmlessness, and helpfulness, remains a significant challenge. Traditional methods like Reinforcement Learning with Human Feedback (RLHF) have proven effective but are resource-intensive and complex. This study introduces a novel approach called Reward Difference Optimization (RDO) to enhance offline RLHF methods by providing more accurate supervision signals.
Related Work
Reinforcement Learning with Human Feedback (RLHF)
RLHF is a method used to align LLMs with human preferences. It involves training a reward model on a dataset containing pairwise comparisons of responses from LLMs. This reward model is then used to fine-tune the LLMs via reinforcement learning techniques like Proximal Policy Optimization (PPO). However, RLHF is highly resource-demanding and complicated to implement.
Offline RLHF
Offline RLHF has been proposed as a simpler alternative to RLHF. It involves directly training LLMs on a preference dataset using ranking losses. However, current offline RLHF methods only capture the ordinal relationship between responses, ignoring the degree of preference between them. This limitation can lead to suboptimal performance.
Research Methodology
Reward Difference Optimization (RDO)
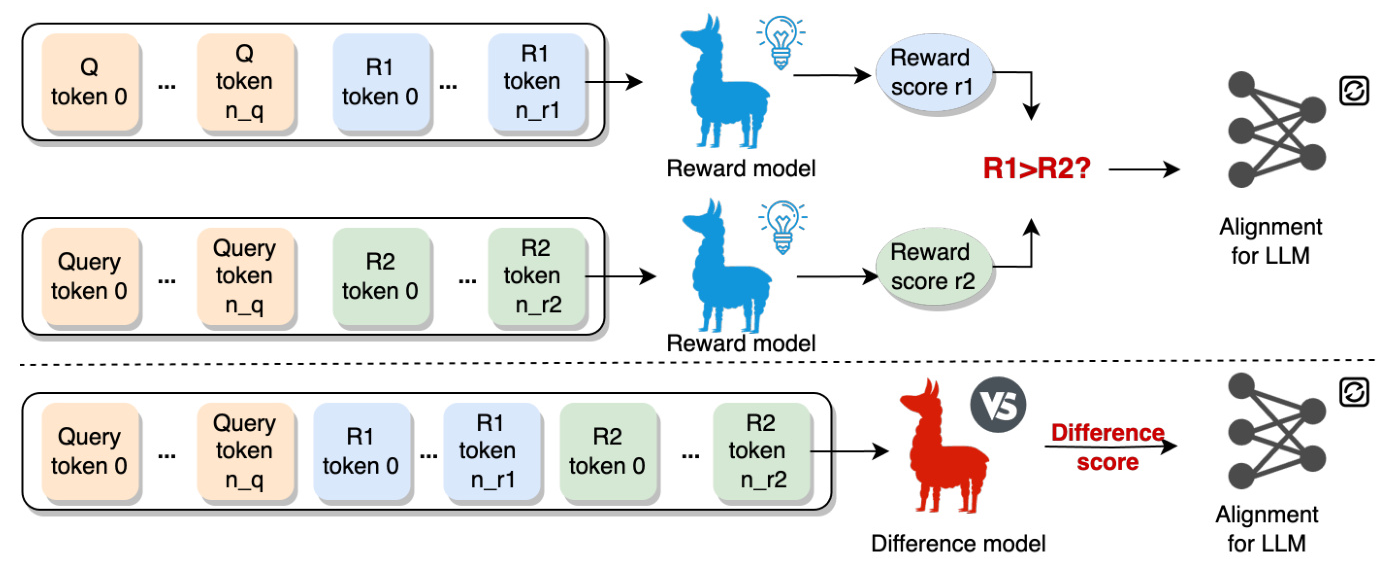
To address the limitations of existing offline RLHF methods, the authors propose Reward Difference Optimization (RDO). This method introduces reward difference coefficients to reweigh sample pairs in offline RLHF. These coefficients quantify the degree to which one response is preferred over another, providing more accurate supervision signals for training.
Difference Model
The difference model is designed to predict the reward difference between two responses directly. Unlike traditional reward models that independently assign scores to responses, the difference model leverages attention-based interactions between response pairs for prediction. This approach provides a more informative representation for predicting reward differences.
Experimental Design
Datasets
The experiments were conducted on two datasets:
1. HH Dataset: Contains dialogues with preferred and dispreferred responses labeled by humans.
2. TL;DR Dataset: A summarization dataset with human preference labels.
Evaluation Metrics
The performance of the proposed methods was evaluated using three metrics:
1. Reward Model Evaluation: Average reward given by the reward model on the test set.
2. LLM Auto Evaluation: Responses were scored by LLMs like GPT-4, GPT-3.5, and moonshot-v1.
3. Human Evaluation: Responses were evaluated by human judges based on helpfulness and general quality.
Training Settings
The initial model for alignment was Alpaca-7B. The experiments compared three offline RLHF methods: RRHF, DPO, and KTO. Each method was evaluated in three cases: vanilla offline RLHF, RLHF with reward difference coefficients from a pointwise reward model, and RLHF with reward difference coefficients from the difference model.
Results and Analysis
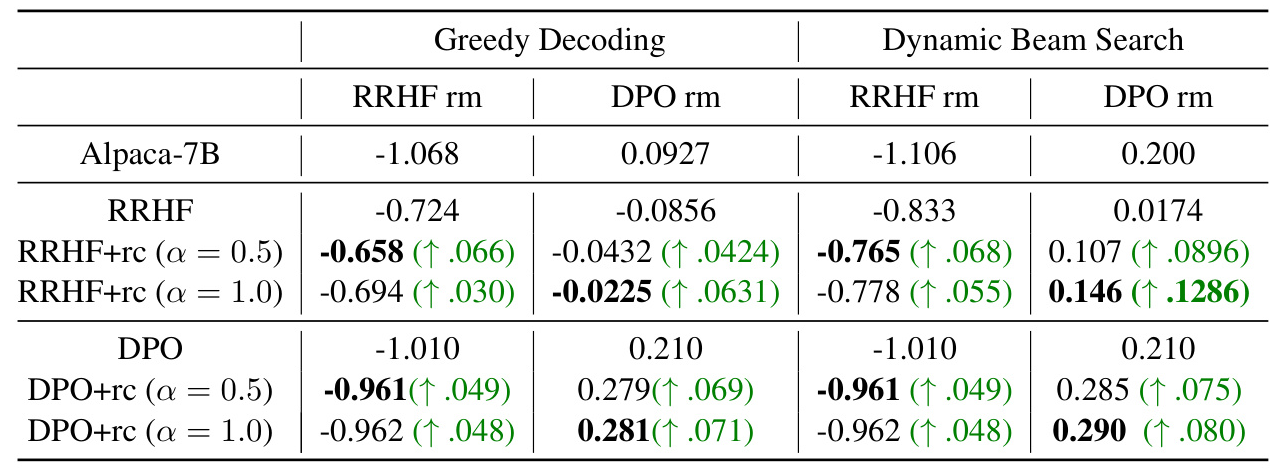
Effect of Reward Difference Coefficients
The inclusion of reward difference coefficients consistently enhanced the performance of offline RLHF methods. The results showed improvements in both reward model evaluation and LLM auto evaluation metrics.
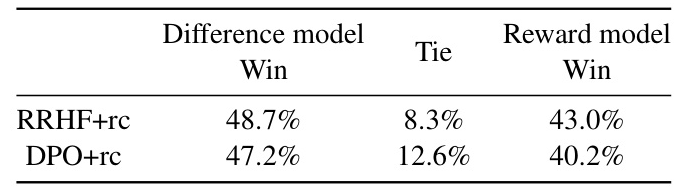
Comparison of Difference Model and Reward Model
The difference model outperformed the traditional reward model in predicting reward differences. The accuracy of the difference model was higher than that of the baseline reward models.

Effect on Offline RLHF Methods
The difference model provided more accurate supervision signals, leading to better alignment of LLMs with human preferences. Both LLM-based and human evaluations confirmed the advantages of the difference model over the reward model.
Overall Conclusion
This study introduces Reward Difference Optimization (RDO) to address the limitations of existing offline RLHF methods. By incorporating reward difference coefficients and leveraging a difference model, the proposed approach provides more accurate supervision signals for training LLMs. The experimental results demonstrate the effectiveness of RDO in enhancing offline RLHF methods, making it a promising solution for aligning LLMs with human preferences.
Future work will focus on scaling the approach to larger models and exploring techniques to maintain the generalization ability of LLMs after alignment.