

Authors:
Jianhao Guo、Zixuan Ni、Yun Zhu、Siliang Tang
Paper:
https://arxiv.org/abs/2408.09350
Continual learning has become an essential paradigm for learning from sequential data while preserving previously acquired knowledge. In the context of graph learning, where graphs continuously evolve based on streaming data, continual graph learning presents unique challenges. This blog post delves into the paper “E-CGL: An Efficient Continual Graph Learner,” which addresses these challenges by proposing an efficient continual graph learner (E-CGL).
Introduction
Background
Graphs are a ubiquitous data form, representing various real-world applications such as social networks, recommendation systems, and citation networks. These graphs tend to expand over time, introducing new patterns and requiring models to adapt continuously. Traditional training strategies often suffer from catastrophic forgetting, where the model’s performance on previous tasks deteriorates as it learns new tasks.
Problem Statement
Continual graph learning faces two primary challenges:
1. Interdependencies between graph data: New data distributions are influenced by previous graphs, making it difficult to adapt without forgetting past knowledge.
2. Efficiency concerns: As graphs grow larger, the computational cost of updating models increases exponentially.
To address these challenges, the paper proposes E-CGL, which leverages replay strategies and a combined sampling strategy to manage interdependencies and employs a simple yet effective MLP model to enhance efficiency.
Related Work
Continual Learning Approaches
Continual learning (CL) aims to learn from new data while preserving previous knowledge. Existing approaches can be categorized into:
– Regularization-based methods: Penalize changes in model parameters to preserve past task performance.
– Replay-based methods: Select exemplary data from prior tasks to retrain the model along with new data.
– Architecture-based methods: Introduce different parameter subsets for different tasks to avoid drastic changes.
Continual Graph Learning
Several methods have extended classical continual learning to graphs, such as TWP, which adopts parameter regularization, and ER-GNN, which proposes node selection strategies for replaying. However, these methods often overlook the unique challenges posed by graph dependencies and efficiency concerns.
Research Methodology
Preliminaries
A growing graph can be decomposed into a series of dynamic graphs according to timestamps. Each subgraph constitutes a distinct task with different types of nodes and edges. The goal is to learn new information while preventing catastrophic forgetting of previous knowledge.
Graph Dependent Replay
To address catastrophic forgetting, E-CGL employs a replay-based strategy that maintains a memory buffer to store historical data. The model learns from new data and replays old data using a novel sampling strategy that considers both node importance and diversity.
Importance Sampling
Inspired by the PageRank algorithm, the importance sampling strategy evaluates the importance of each node by considering both topological structures and node attributes. This approach ensures that important nodes are replayed to counteract forgetting.
Diversity Sampling
To capture novel patterns, the diversity sampling strategy selects nodes that significantly differ from their neighbors at the feature level. This enhances the diversity of the memory buffer, ensuring that vulnerable nodes are replayed.
Efficient Graph Learner
To improve efficiency, E-CGL incorporates a Multi-Layer Perceptron (MLP) for training and utilizes its weights to initialize the GNN for inference tasks. This approach eliminates the time-consuming message passing process during training, significantly speeding up the training process.
Experimental Design
Datasets
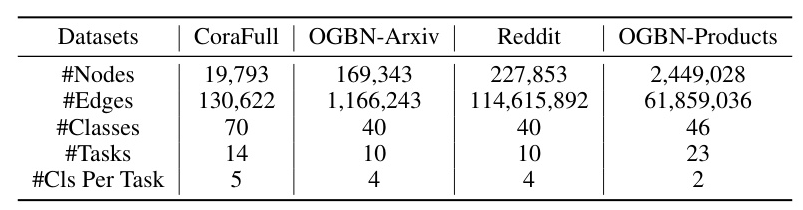
Experiments were conducted on four node classification datasets: CoraFull, Reddit, OGBN-Arxiv, and OGBN-Products. The label space of the original datasets was partitioned into non-intersecting segments to simulate the task/class incremental setting.
Baselines
E-CGL was compared against nine state-of-the-art continual learning techniques, including both conventional methods (e.g., LwF, EWC) and graph-specific methods (e.g., TWP, ER-GNN).
Metrics
The performance matrix was used to depict the dynamics of overall performance, with average accuracy (AA) and average forgetting (AF) as key metrics.
Results and Analysis
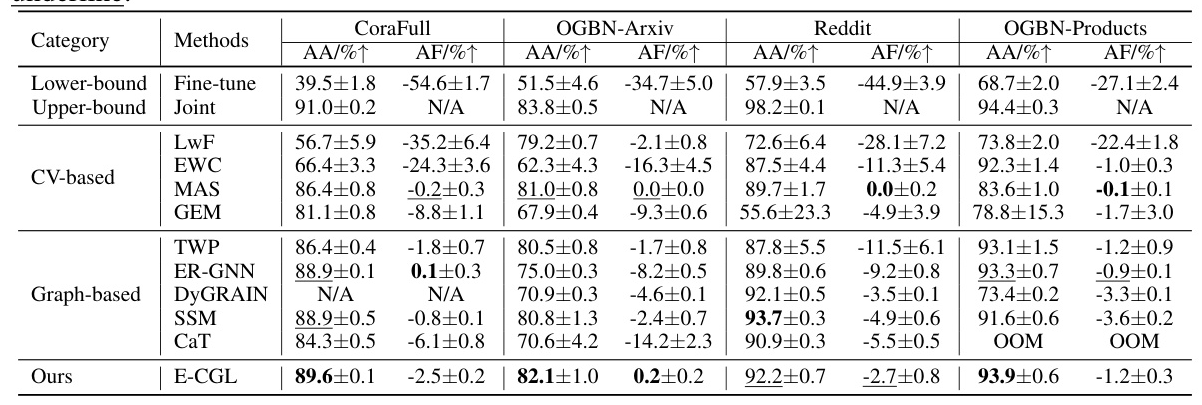
Task-IL Results
E-CGL demonstrated notable performance, achieving the highest average accuracy on three datasets and the second-highest on Reddit. It also exhibited an average forgetting of -1.1%, indicating its effectiveness in mitigating catastrophic forgetting.
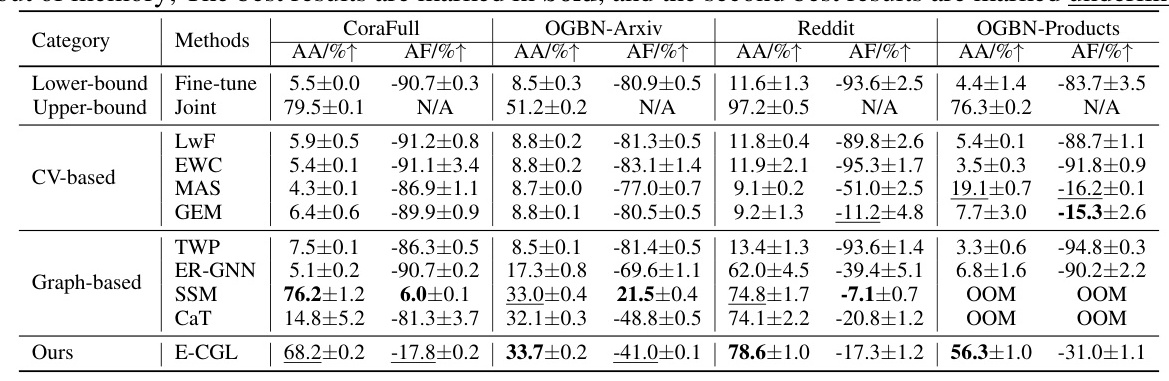
Class-IL Results
Under the class-IL setting, E-CGL showed stable performance across all datasets, outperforming other methods in terms of both accuracy and forgetting.
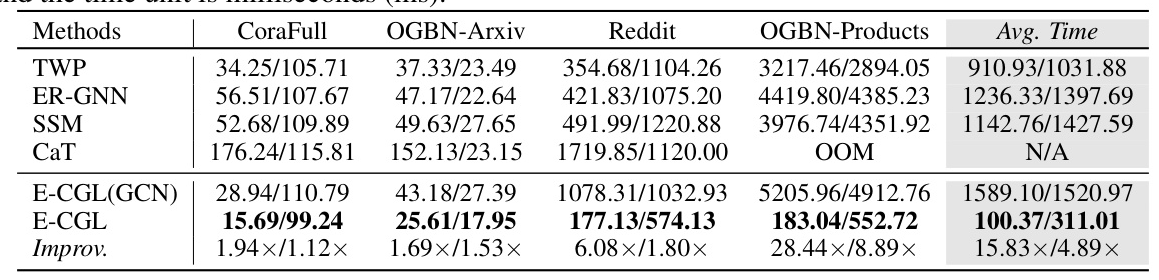
Running Time Analysis
E-CGL significantly reduced both training and inference time compared to its GCN version, achieving an average speedup of 15.83 times during training and 4.89 times during inference.
Ablation Study
Ablation studies highlighted the importance of both the importance and diversity samplers in the replay-based strategy. Replacing the MLP encoder with GCN resulted in minor performance degradation but significantly increased training time.

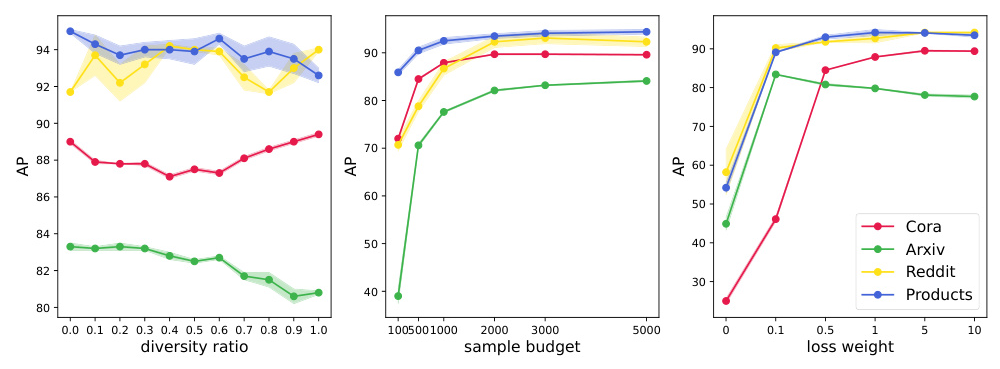
Parameter Sensitivity
Parameter sensitivity analysis showed that the diversity sampling ratio had minimal impact on results, while increasing the sampling budget consistently improved performance.
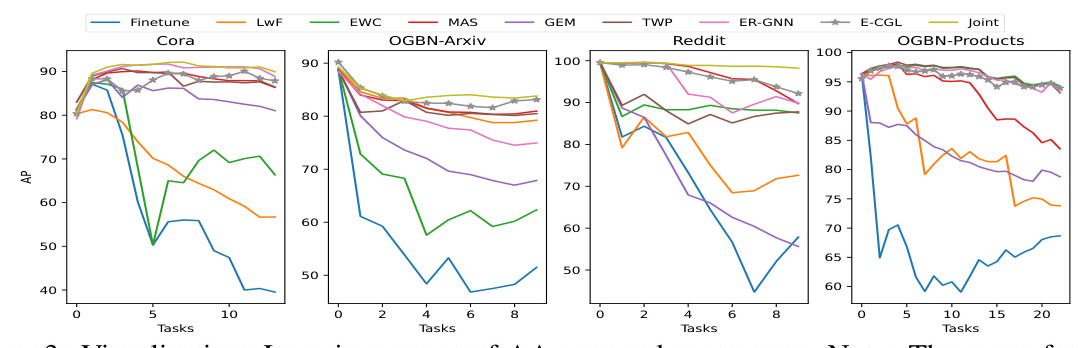
Learning Curve and Performance Matrix
The learning curves and performance matrices demonstrated that replay-based approaches, including E-CGL, consistently outperformed other methods, highlighting the importance of maintaining interdependencies in graph data.

Overall Conclusion
E-CGL addresses the challenges of interdependencies and efficiency in continual graph learning by employing a graph-specific sampling strategy for replay and an MLP encoder for efficient training. The empirical results demonstrate its effectiveness in terms of both performance and efficiency.
Future research should explore methods for protecting historical data privacy during replay, actively forgetting unneeded knowledge, and handling heterogeneous graphs. E-CGL represents a significant step forward in continual graph learning, inspiring further advancements in this domain.