

Authors:
Ravi Raju、Swayambhoo Jain、Bo Li、Jonathan Li、Urmish Thakkar
Paper:
https://arxiv.org/abs/2408.08808
Introduction
Large Language Models (LLMs) have significantly transformed the machine learning landscape, becoming integral to various applications. However, existing benchmarks often fail to capture the diverse behaviors of these models in real-world scenarios. Human evaluations, while considered the gold standard, are time-consuming and expensive. To address these limitations, the concept of LLM-as-a-judge has been introduced, where one LLM evaluates the outputs of another. This paper presents a novel data pipeline to create diverse, domain-specific evaluation sets tailored for LLM-as-a-judge frameworks.
Methodology
Data Sources
The evaluation set is constructed from a variety of open-source datasets to ensure coverage across multiple domains and languages. The targeted domains include medical, law, finance, mathematics, and coding, while the languages span from common ones like Japanese and Arabic to more esoteric ones like Hungarian and Slovenian. A complete list of the datasets used can be found in the appendix.
Data Pipeline
The data pipeline consists of three main steps:
- Embedding Generation: Using an embedding model, embeddings are generated for the data corpus. These embeddings encapsulate semantic information about the prompts.
- Semi-Supervised Learning: A seed set of prompts is manually curated and labeled into specific categories. These labeled prompts are then used to train a k-NN classifier, which labels the larger unlabeled corpus.
- Stratified Sampling and Manual Curation: Stratified sampling ensures balanced representation across all categories. The final set of prompts is manually curated to ensure high quality and diversity.
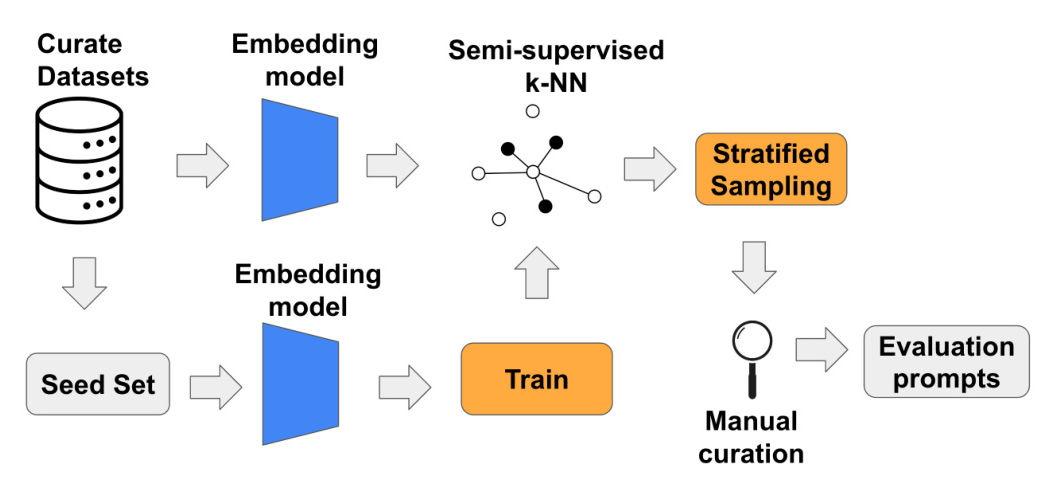
Experimental Setup
Data Pipeline Details
The k-NN classifier is trained with 13 categories, including various domains and languages. The embeddings are generated using the e5-mistral-7b-instruct embedding model, chosen for its strong performance and multilingual capability. An entropy threshold is set to classify uncertain samples into a general category.
LLM-as-a-Judge Details
The evaluation follows a similar setup to Arena-Hard and Alpaca-Eval, using GPT-4o as both the judge and reference model. To mitigate positional bias, completions are swapped on a coin flip. The judge prompt is modified to penalize responses in the incorrect language and to focus on the correctness of coding responses.
Obtaining Confidence Intervals
The Bradley-Terry model is used to model preference distributions between models. Bootstrapping is performed to obtain 95% confidence intervals for each model ranking.
Metrics
Four metrics are used to judge the efficacy of the benchmark:
1. Spearman’s Correlation Coefficient: Measures the ranking order between two benchmarks.
2. Separability: Indicates how well the benchmark can differentiate between models.
3. Agreement with Confidence Interval (CI): Measures how well benchmarks distinguish between models with the same ordering.
4. Brier Score: Evaluates the benchmark’s ability to predict the ranking of competing models.
Results
Separability, Agreement with CI (95%), Pair Brier Score
The benchmark demonstrates higher separability (84.4%) compared to Arena-Hard v0.1 (80%) and Alpaca-Eval 2.0 LC (73.33%). It also shows higher agreement with CI (84.44%) and a strong Spearman’s correlation coefficient (0.915). The Brier score is lower (0.0417), indicating better confidence in accurate predictions.

Diversity
The evaluation set covers more domains and languages compared to Arena-Hard v0.1 and Alpaca-Eval 2.0 LC. The distribution of categories is more balanced, thanks to stratified sampling.
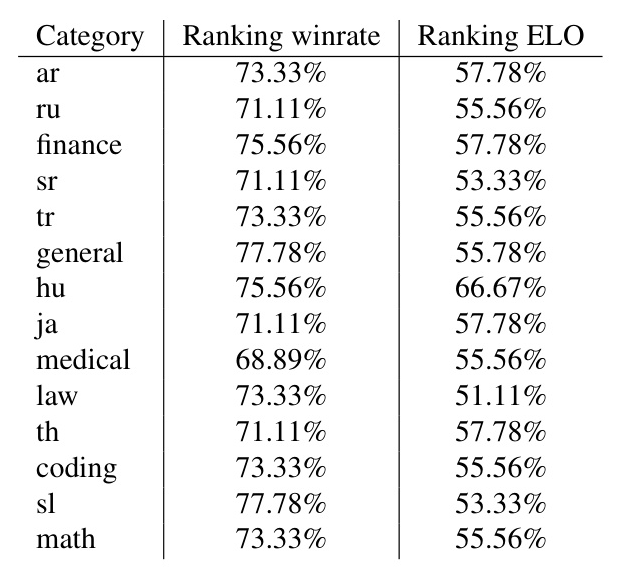
Category Separability
Category-wise separability indicates which categories are better at testing model performance. Hungarian has the best separability, while the medical category has the lowest.
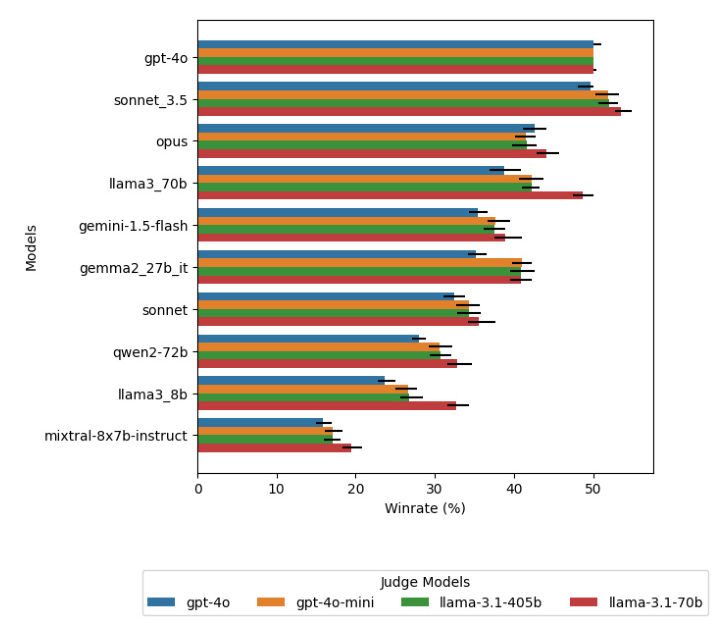
Using Different Judges
An ablation study with different judge models shows that while weaker models can separate other models based on capability, they lack the precision of GPT-4o in aligning with Chatbot Arena rankings.
Limitations and Future Work
The current methodology involves significant manual curation. Future work aims to automate this process using LLMs for category generation and quality checks. Additionally, expanding the leaderboard to include more models and improving category separability are areas for future exploration.
Conclusion
This paper introduces a data pipeline that leverages semi-supervised learning to create diverse, domain-specific evaluation sets for LLM-as-a-judge frameworks. The benchmark achieves higher separability and agreement with Chatbot Arena, covering a wide variety of topics and languages. This approach provides practitioners with a tool to evaluate models for their specific use cases.

Datasets: