Authors:
Boa Jang、Youngbin Ahn、Eun Kyung Choe、Chang Ki Yoon、Hyuk Jin Choi、Young-Gon Kim
Paper:
https://arxiv.org/abs/2408.08790
Introduction
Vision is a critical aspect of quality of life, especially as people age. Common eye diseases such as age-related macular degeneration (AMD), glaucoma, diabetic retinopathy (DR), retinal vein occlusion (RVO), pathologic myopia (PM), and epiretinal membrane (ERM) can lead to blindness if not diagnosed and treated early. With the increasing prevalence of these conditions and a projected shortage of ophthalmologists by 2035, there is a pressing need for efficient, accessible screening and diagnostic systems.
Advancements in fundus imaging and artificial intelligence (AI) have paved the way for user-friendly, resource-efficient screening systems suitable for primary healthcare settings. These systems can facilitate early detection of fundus abnormalities, providing critical treatment advice or referrals. However, developing highly accurate AI models for healthcare is challenging due to stringent personal data regulations and high data annotation costs.
Transfer learning, which leverages knowledge from pre-trained models, has emerged as a powerful strategy in this context. While ImageNet pre-trained models are commonly used in medical imaging tasks, their performance is often limited due to the mismatch in image resolution. Domain-specific pre-trained models have shown promise, as evidenced by their success in Chest X-ray imaging.
This study introduces two novel types of disease-specific foundation models for fundus images, developed using an extensive dataset. These models are intended to be freely available to the research community, addressing the gap in domain-specific tools for comprehensive disease detection and diagnosis in fundus imagery.
Materials and Methods
Dataset of Fundus Images
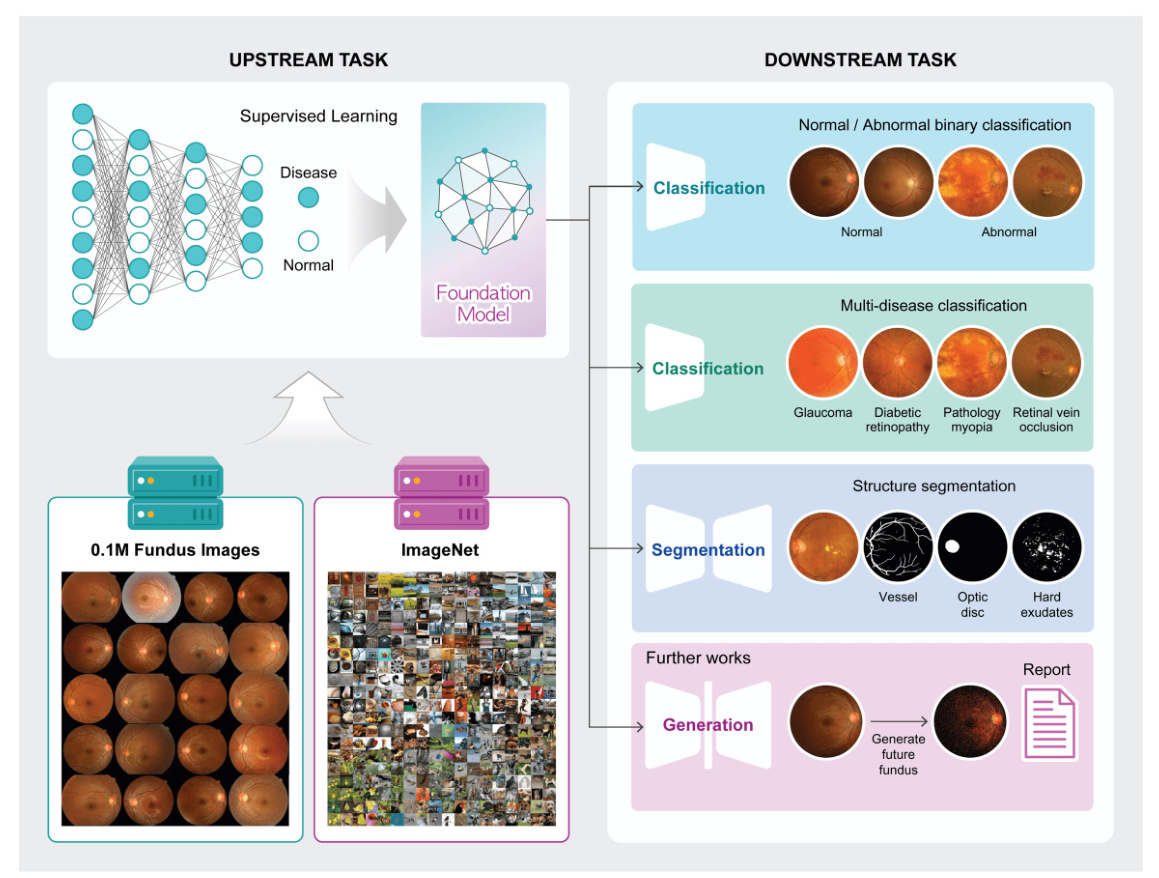
Transfer learning involves two main components: the upstream task and the downstream task. The upstream task focuses on training a model using a large dataset to generate pre-trained weights, which are then utilized in the downstream task to assess the efficiency and performance of the pre-trained weights.
For the upstream task, 113,645 fundus images of 57,803 patients were retrospectively acquired from Seoul National University Hospital Healthcare System Gangnam Center in South Korea. These images, collected between 2003 and 2010, were labeled as normal or abnormal, with a ratio of 8:2.
For the downstream tasks, 18,459 fundus images with confirmed abnormalities were collected independently from the same hospital. These images were further classified into seven distinct classes representing different eye diseases for multi-label classification: AMD, glaucoma, glaucoma suspect, DR feature, PM, ERM, and RVO. Three public datasets (RFMiD, JSIEC, and FIVES) were used for external validation and to generalize the tasks.
Training Visual Representation of Fundus as an Upstream Method
Two types of disease-specific foundation models were developed: one using a large fundus image dataset with derived labels (abnormal and normal), referred to as ‘Fundus’, and another using a two-step pre-training approach starting with ImageNet-1k and subsequently retrained using the large fundus image dataset, referred to as ‘ImageNet + Fundus’. The models were trained using supervised learning methods to classify normal and abnormal fundus images, with three different image resolutions tested: 256, 512, and 1024 pixels.
The models were trained using 4 NVIDIA A100 GPUs with a batch size of 32, implemented in PyTorch. A 50-layer residual network (ResNet) was used, with the Adam optimizer configured with a learning rate of 1e-5, momentum of 0.9, and weight decay of 1e-5. Data augmentation techniques included horizontal flip, grayscale, blur, and contrast limited adaptive histogram equalization (CLAHE). The training process spanned 100 epochs with early stopping to prevent overfitting, taking approximately five days.
Evaluation via Various Conditions of Downstream Task
Three different downstream tasks were utilized to evaluate the disease-specific foundation model: abnormality classification (binary classification of normal and abnormal), multi-disease classification (classification of various diseases from fundus images), and vessel segmentation (segmentation of vessels from fundus images). The quality of learned representations was assessed through linear probing (LP) and full fine-tuning (FT).
The abnormality classification task was evaluated under three scenarios: the effectiveness of different pre-trained models, the impact of image resolutions, and a stress test under data-limited conditions. Four models were compared: one with randomly initialized weights (‘Scratch’), one pre-trained with ImageNet weights (‘ImageNet’), and two pre-trained with fundus-specific weights (‘Fundus’ and ‘ImageNet + Fundus’).
Measurement and Visualization of the Embeddings
Model performance was assessed using five-fold cross-validation, with the area under the receiver operating characteristic curve (AUC) as the primary metric. Differences in AUC scores between models were tested using DeLong’s test, with a p-value of less than 0.05 considered statistically significant.
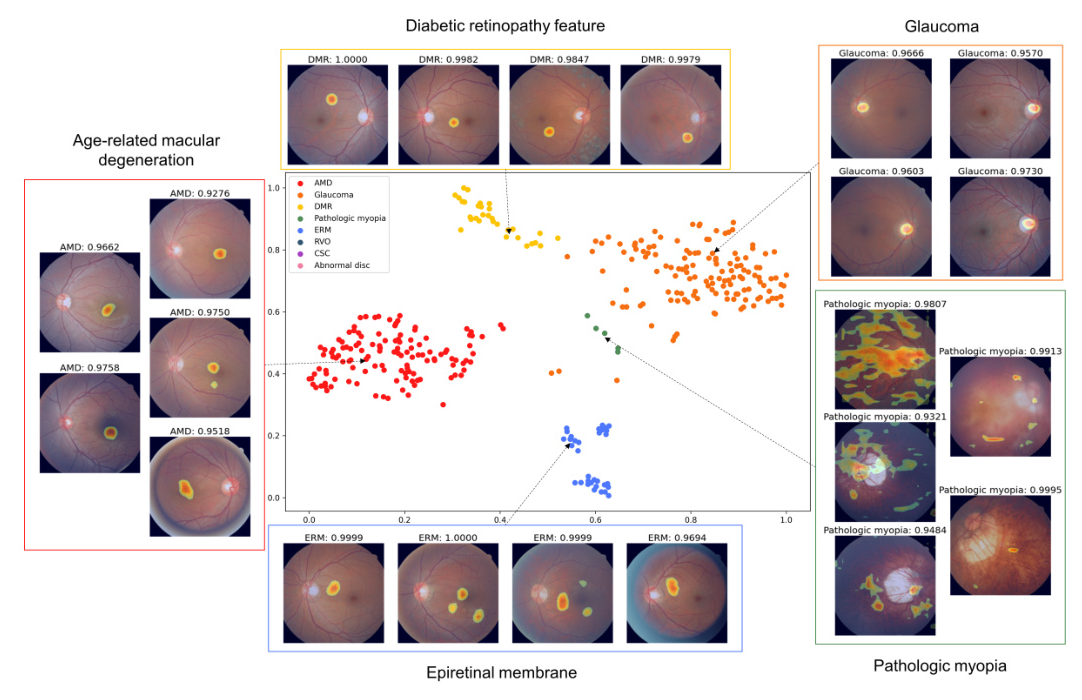
To visualize how embeddings differ between general models and fundus-specific pre-trained models, t-distributed stochastic neighbor embedding (t-SNE) was used. Gradient-weighted class activation mapping (Grad-CAM) was also employed to enhance the interpretability of the predicted results for each fundus image.
Code Availability
The source code and trained models are available at https://github.com/Research-Foundation-Retina. These resources aim to facilitate replication of the results and further research in the field.
Results
Abnormality Classification Task
Comparison of Pre-training Weights
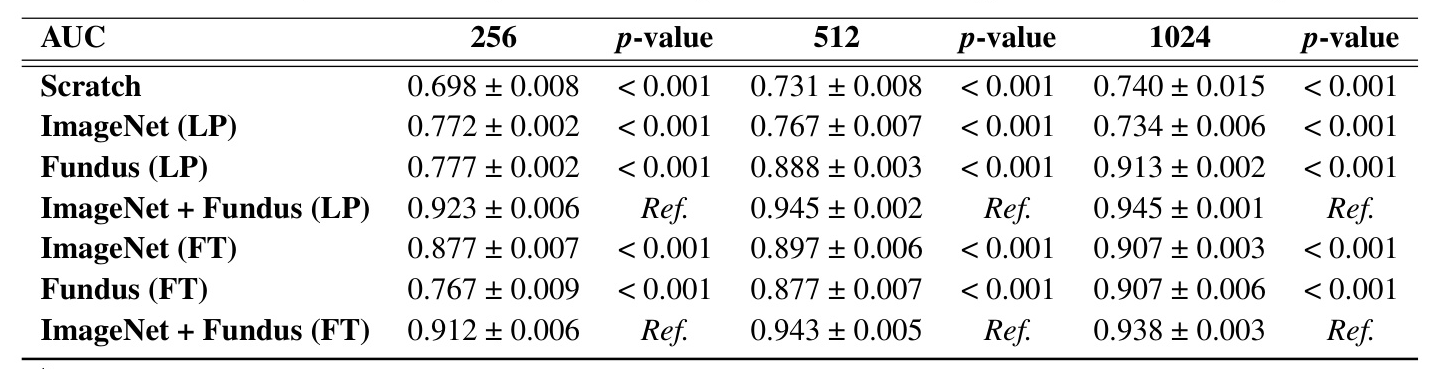
Table 1 summarizes the mean AUC scores obtained through different model configurations and image resolutions under both LP and FT methods. Models trained from Scratch generally showed lower AUC scores, with a peak at 1024 pixels resolution. Models pre-trained with ImageNet weights under LP demonstrated a decline in performance as resolution increased. Conversely, models pre-trained with Fundus weights under LP showed significant improvement with increasing resolution.
The combination of ImageNet + Fundus pre-training consistently yielded the highest AUC scores across all tested resolutions in the LP method. Similarly, under FT, the ImageNet + Fundus models demonstrated robust performance.
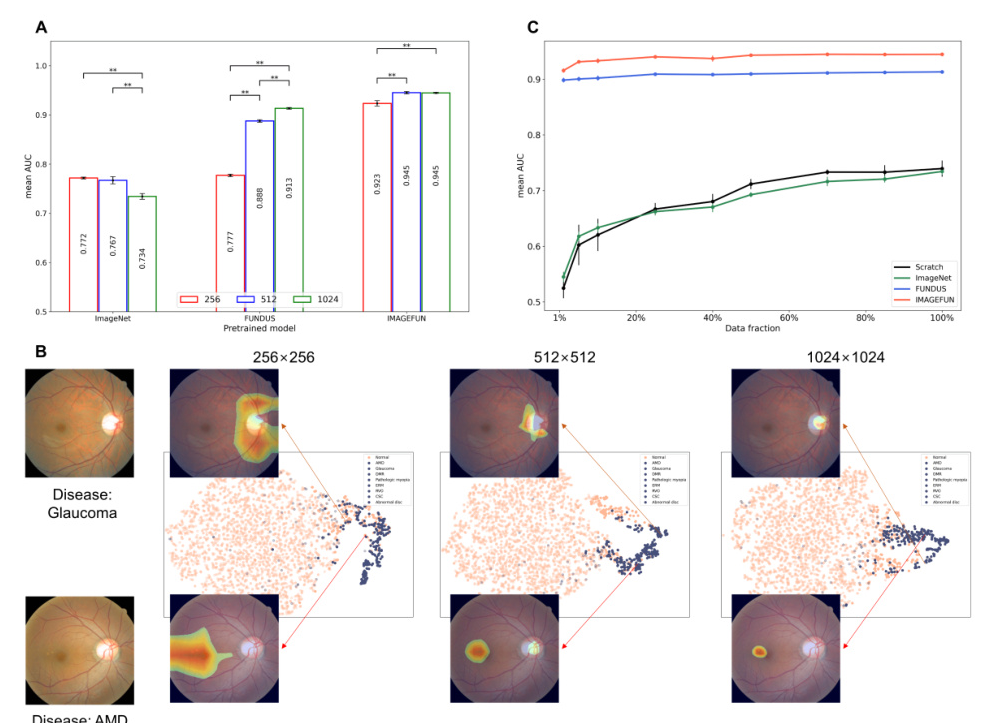
Impact of Image Resolution on Model Performance
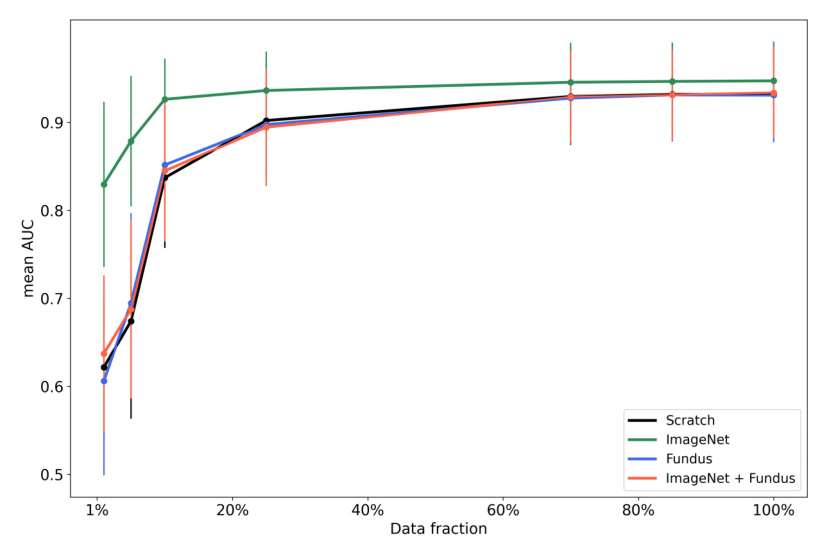
Figure 2A highlights the variation in mean AUC scores for different pre-trained models across increasing image resolutions within the LP method. The ImageNet pre-trained model demonstrated a decrease in performance as the resolution increased, while the Fundus pre-trained model showed significant improvement with increasing resolution. The ImageNet + Fundus pre-trained model consistently achieved the highest performance.
Figure 2B utilizes a t-SNE graph to compare the qualitative results of embeddings from the ImageNet + Fundus pre-trained model within the LP method. The activation map generated using Grad-CAM further reveals that as image resolution decreases, smaller and more specific regions are identified as critical for making clinical decisions.
Comparison of Stress Test
Figure 2C presents the outcomes of the stress tests using various data fractions. The ImageNet + Fundus model demonstrated superior performance, achieving the highest mean AUC across all tested conditions, even with severely limited data (1% fraction).
Task Generalization
External Validation for Abnormality Classification
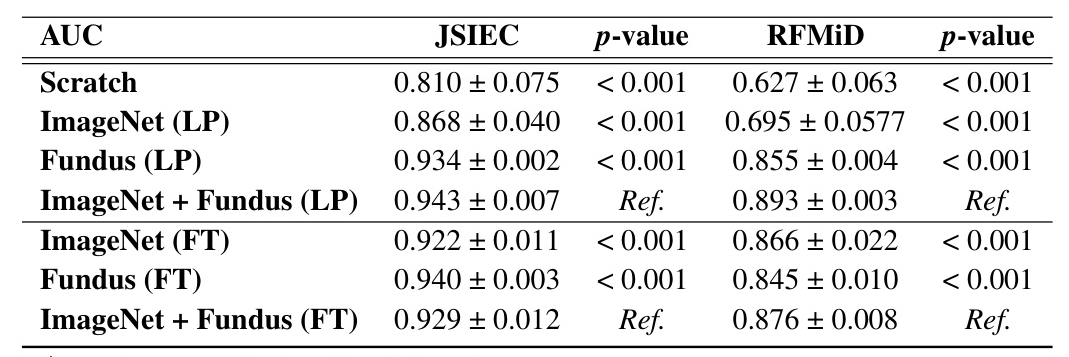
External validation was conducted using the JSIEC and RFMiD datasets. The ImageNet + Fundus model under LP achieved the highest AUC for the JSIEC dataset and strong performance for the RFMiD dataset, demonstrating the model’s capability to perform effectively across different external datasets.
Extending Model Capabilities: Multi-Disease Classification
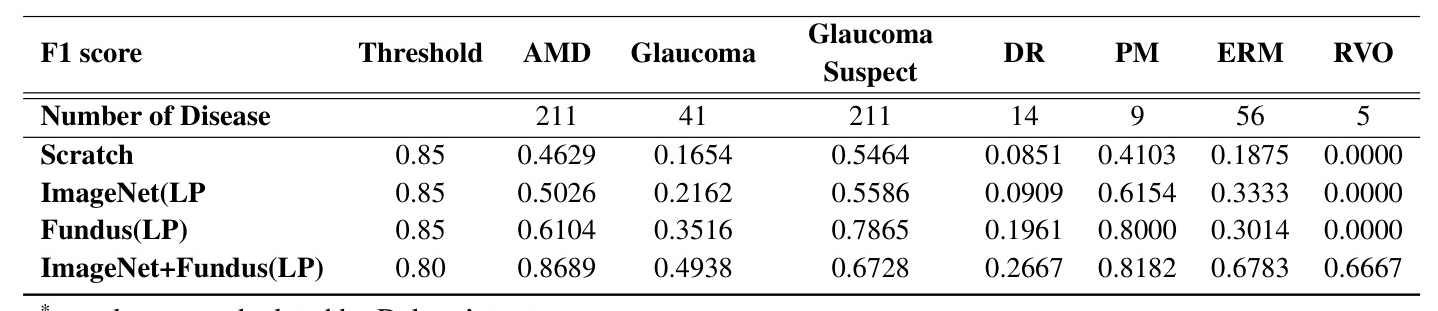
The model was extended to multi-disease classification by adapting it for multi-label classification tasks. Fine-tuning the model on a multi-label annotated dataset allowed it to learn specific disease patterns within the fundus images, enhancing its ability to accurately identify and categorize abnormal fundus images involving seven distinct disease types.
Extending Model Capabilities: Vessel Segmentation
The model’s functionality was further extended to include vessel segmentation using a U-Net based architecture and the Dice coefficient as the loss function. The performance analysis for the vessel segmentation task highlighted the robust and consistent efficacy of the ImageNet-based model across various data volumes.
Discussion
This study demonstrated the superior performance of the Fundus and ImageNet + Fundus models over Scratch and ImageNet pre-trained models across various downstream tasks. The two-step pre-training method, particularly the ImageNet + Fundus model, consistently outperformed other models, underscoring the benefits of disease-specific foundation models.
The image-scale based analysis revealed that transfer learning is most effective when the data closely resembles the pre-trained model’s original training set. However, models trained on ImageNet may not perform as effectively as those starting from scratch due to the mismatch between general and medical image characteristics.
In the multi-disease classification task, the disease-specific foundation models outperformed general pre-trained models. However, in the vessel segmentation task, the models pre-trained on Fundus data were less successful at structural tasks like vessel segmentation.
The study also highlighted the importance of selecting an appropriate pre-trained model tailored to the specific domain and task. The results of the stress tests emphasized the practical benefits of employing pre-trained models in real-world research environments where data availability may be constrained.
Despite its successes, the developed model faced certain limitations, such as less-than-optimal performance in tasks involving the extraction of structures from fundus images beyond the scope of learned normal and abnormal information. Future improvements and fine-tuning are expected to enhance model performance.
Conclusion
Our research focused on developing a disease-specific foundation model specifically tailored for fundus image analysis. Through extensive validation under diverse experimental conditions, we confirmed the superior performance of the disease-specific foundation models compared to models trained from scratch or pre-trained on ImageNet. This emphasizes the importance of domain-specific training and highlights the benefits in fundus image-based models.
The successful development of the disease-specific foundation model underscores its significance in medical imaging, where domain-specific features play a pivotal role. By enhancing diagnostic accuracy and facilitating early detection and management of various abnormal eye conditions, our research contributes to advancing fundus image analysis. Ultimately, this work has implications for improving patient care and healthcare practices in ophthalmology. The released model weights are anticipated to play a crucial role as an auxiliary means for swiftly distinguishing between normal and abnormal fundus diseases for ophthalmologists.