Authors:
Tongyoung Kim、Soojin Yoon、Seongku Kang、Jinyoung Yeo、Dongha Lee
Paper:
https://arxiv.org/abs/2408.08686
Introduction
Sequential recommendation aims to predict a user’s next interaction by capturing the context from their interaction history. With the advancement of language models (LMs), recent progress in sequential recommender systems has been driven by utilizing LMs for their text understanding and generation capabilities. Generative retrieval approaches decode item identifiers based on user interaction history, leveraging LMs to generate sequences of indices for the target item. However, the integration of collaborative and semantic information in these systems has remained unexplored.
In this paper, we propose SC-REC, a unified recommender system that learns diverse preference knowledge from two distinct item indices and multiple prompt templates. SC-REC adopts a novel reranking strategy that aggregates a set of ranking results inferred from different indices and prompts to achieve self-consistency. Our empirical evaluation on three real-world datasets demonstrates that SC-REC significantly outperforms state-of-the-art methods for sequential recommendation.
Related Work
Generative Retrieval
Generative retrieval leverages the generation capabilities of generative models to enhance information retrieval systems by directly generating relevant contents from the database. Examples include GENRE for entity retrieval and DSI for document retrieval. These methods assign structured semantic IDs to documents or entities and use text-to-text models to decode these identifiers.
Sequential Recommendation
Sequential recommendation predicts the next item users will interact with based on their past interactions. Traditional methods include Markov Chain techniques and models like GRU4Rec and SASRec, which use recurrent neural networks and self-attention mechanisms, respectively. Recent studies have explored pre-training techniques using self-supervised learning tasks, such as S3-Rec and VQ-Rec.
Generative sequential recommenders, like P5 and TIGER, leverage LMs to generate sequences of indices for the target item. These methods have shown effectiveness but lack systematic integration of heterogeneous information for indexing.
Preliminaries
Problem Formulation
Given a user-item interaction dataset, the goal of the sequential recommendation task is to predict the next item a user will be interested in based on their interaction history. The interaction history is represented as a sequence of item indices, and the task is to generate a ranked list of potential next items.
Complementarity from Diverse Prompts and Heterogeneous Item Indices
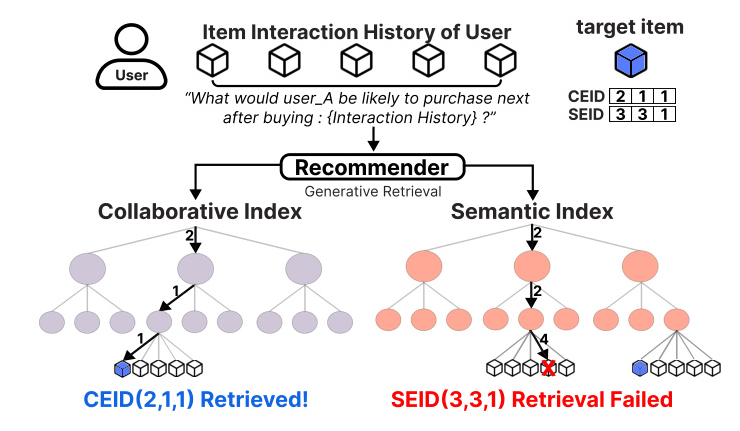
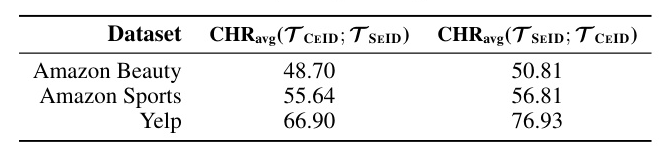
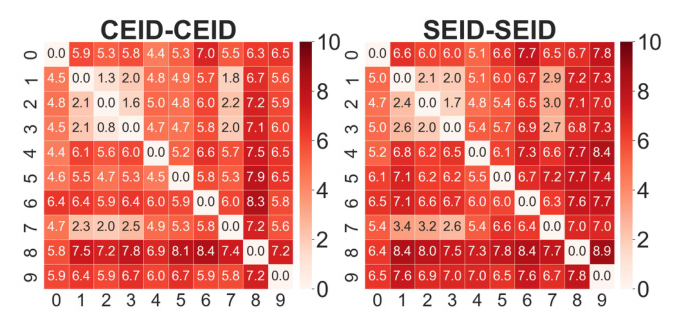
We conducted an analysis to explore the complementary knowledge encoded in the generated ranked lists when predicting the next item using different prompt contexts and index types. We used the P5 model to predict the next item using diverse prompt templates and heterogeneous item indices, capturing context from the input and generating ranked lists.
Our analysis showed that the model captures diverse contextualized representations, resulting in varied inference outcomes due to differences in prompts and item index types. This motivates the need to aggregate ranking results to achieve self-consistency.
Method
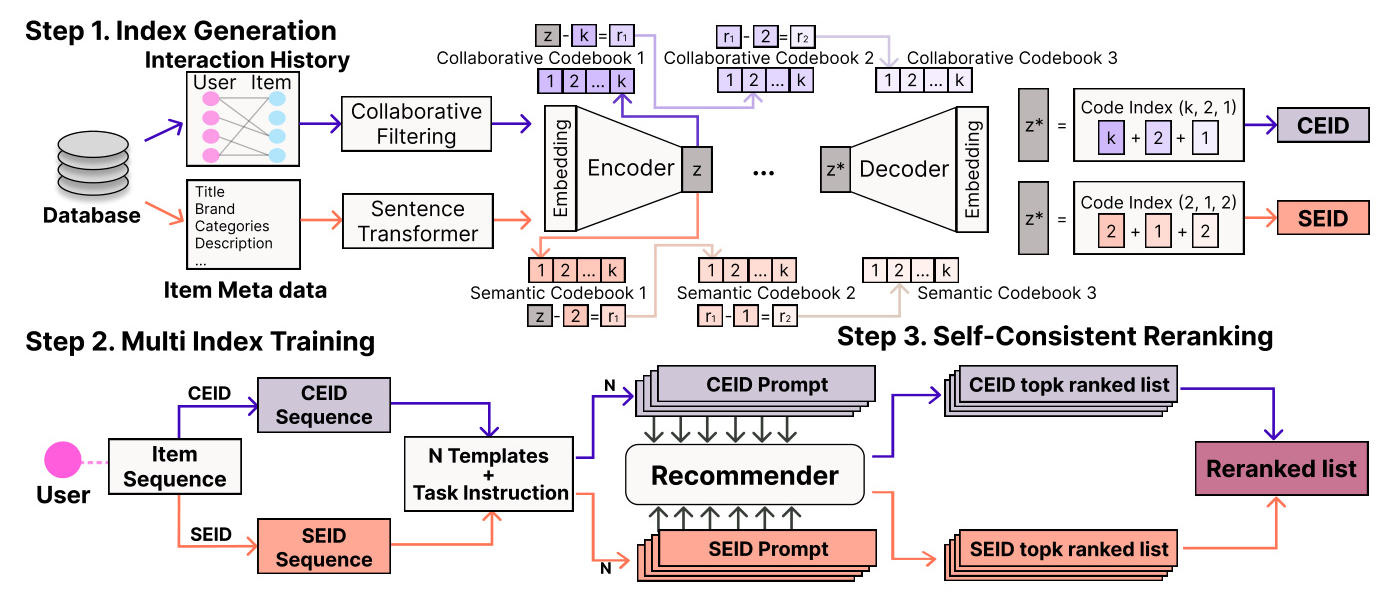
Item Multi-Index Generation
We generate two types of item indices: collaborative embedding-based item index (CEID) and semantic embedding-based item index (SEID).
- Item Embedding Generation: Collaborative embeddings are obtained using a collaborative filtering model like LightGCN, while semantic embeddings are generated using a text encoder like Sentence-T5.
- Index Tree Generation: We use tree-structured vector quantization (VQ) methods, specifically residual-quantized variational autoencoder (RQ-VAE), to generate hierarchical item representations.
- Handling Collisions: To mitigate ID collisions, we introduce an additional identifier at the final level of the codeword to ensure uniqueness.
Multi-Index Recommender Training
We use the P5 model as the backbone of our sequential recommender model. The model is trained using sequences of item indices generated from CEID and SEID, with input prompt templates describing the user’s interaction history.
- Model Training: The training tasks are formatted as conditional generation tasks in a sequence-to-sequence manner, optimizing the negative log-likelihood of the target item index to be generated.
Self-Consistency for Item Reranking
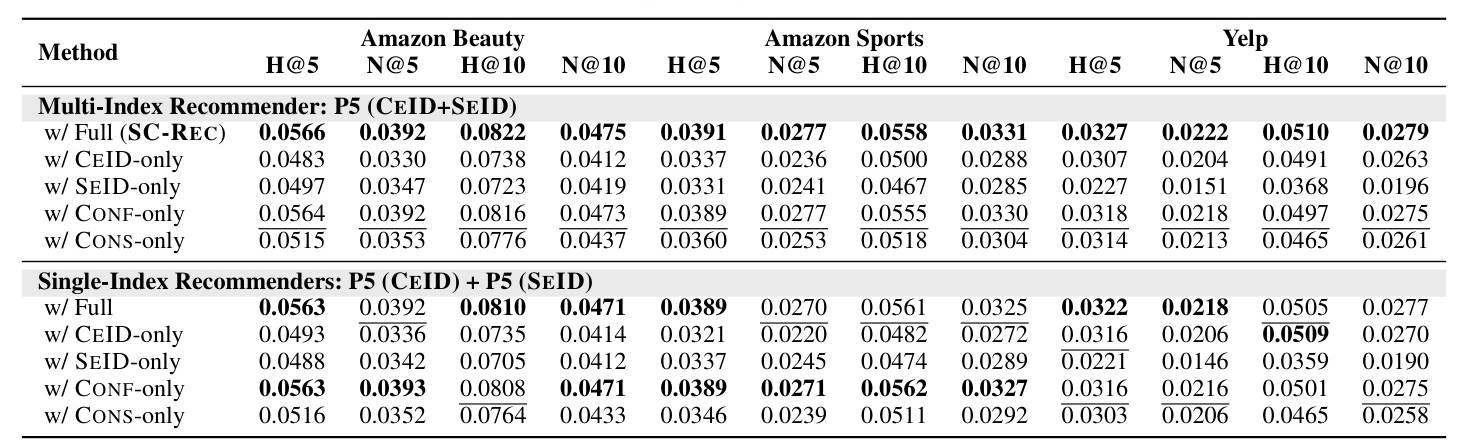
Our goal is to generate a final ranked list of top-K items that accurately reflects user preferences and maintains consistency across diverse prompts and heterogeneous indices. We propose a reranking strategy based on self-consistency, measured by two metrics: confidence and consistency.
- Confidence: Measures how confident the model is in predicting the rank of each item near the top.
- Consistency: Measures how consistent the model is in predicting the rank of each item across multiple ranked lists.
The final reranked item list is obtained by selecting top-K items based on their self-consistency scores, effectively incorporating complementary knowledge from diverse prompt templates and heterogeneous index types.
Experiments
Experimental Settings
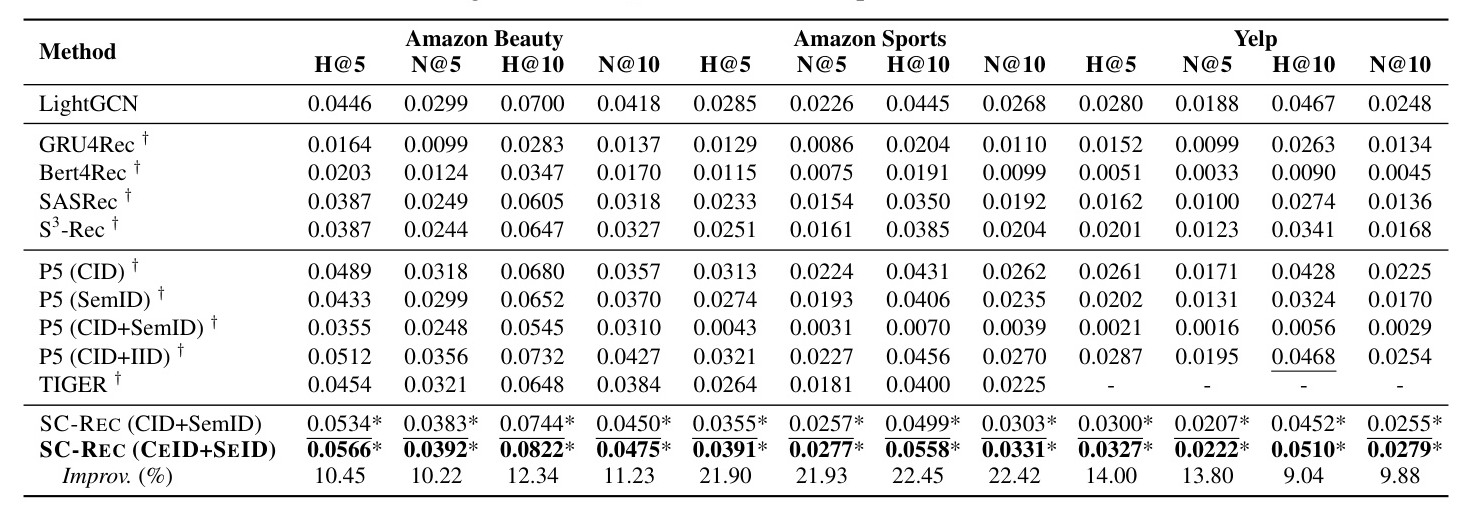
We utilized three datasets: Amazon Beauty, Amazon Sports, and Yelp. The evaluation setup included two top-N ranking metrics: hit ratio (H@K) and normalized discounted cumulative gain (N@K). We compared SC-REC with various baseline methods, including collaborative filtering methods, sequential recommendation with autoregressive modeling, and generative retrieval methods based on PLMs.
Experimental Results
SC-REC consistently achieved superior performance across all datasets, outperforming state-of-the-art methods. The self-consistent reranking strategy effectively integrated complementary knowledge from different index types and prompt templates, enhancing recommendation accuracy.
- Effectiveness of SC-REC: SC-REC outperformed baseline methods, demonstrating the importance of proper indexing and the effectiveness of self-consistency scoring.
- Analysis of Reranking Strategy: The reranking strategy effectively integrated complementary knowledge, consistently generating high-quality recommendations.
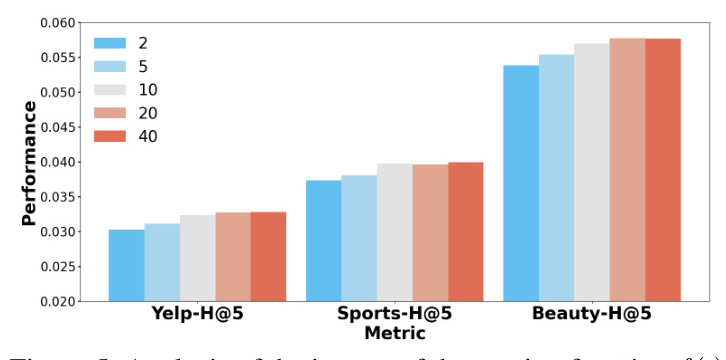
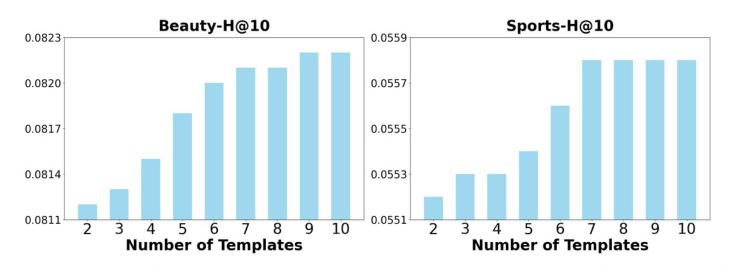
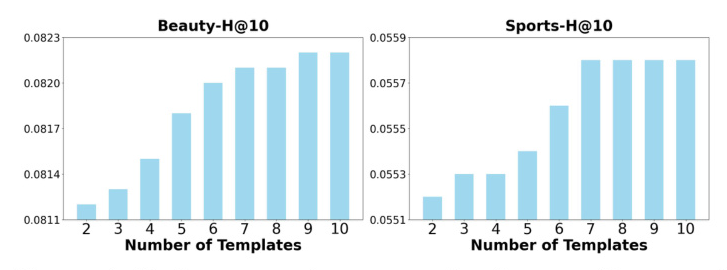
- Impacts of Template Numbers: Increasing the number of prompts used for aggregation improved recommendation performance, supporting the effectiveness of self-consistency reranking.
- Analysis of Scoring Function: The proposed scoring function was effective in considering both confidence and consistency of predictions, with stable performance across different hyperparameter values.
Conclusion
This paper presents SC-REC, a framework that leverages diverse prompt templates and heterogeneous item indices to enhance generative retrieval-based sequential recommendation. Our self-consistency score-based reranking strategy effectively integrates complementary knowledge from diverse sources, significantly improving recommendation performance. Future work will focus on enhancing computational efficiency while maintaining the effectiveness of the model.