

Authors:
Duo Su、Junjie Hou、Guang Li、Ren Togo、Rui Song、Takahiro Ogawa、Miki Haseyama
Paper:
https://arxiv.org/abs/2408.08610
Introduction
In this blog post, we delve into the paper titled “Generative Dataset Distillation Based on Diffusion Model,” which presents a novel approach to dataset distillation using the SDXL-Turbo diffusion model. This method was developed for the generative track of The First Dataset Distillation Challenge at ECCV 2024. The authors, Duo Su, Junjie Hou, Guang Li, Ren Togo, Rui Song, Takahiro Ogawa, and Miki Haseyama, propose a technique that leverages the high-speed and high-quality image generation capabilities of the SDXL-Turbo model to achieve impressive results in dataset distillation.
Background
Deep learning has seen significant advancements, particularly with the rise of Transformers, leading to an increase in the scale of models and the amount of data required for training. However, this growth has created a bottleneck where the volume of data outpaces available computational resources. Dataset distillation (DD) has emerged as a promising solution, synthesizing a small, highly informative dataset from a large amount of real data. Models trained on distilled datasets can achieve generalization performance comparable to those trained on full datasets, offering an efficient solution for managing and training large datasets.
Generative models have introduced new approaches in dataset distillation, encoding critical information from datasets to create synthetic datasets. This flexibility allows for various manipulations of the synthetic dataset, making generative dataset distillation a promising direction. One critical factor affecting the test accuracy of distilled datasets is the distillation budget, defined by images per class (IPC). Generative dataset distillation offers superior flexibility in manipulating IPC for distilled image generation.
Related Work
Dataset Distillation
Dataset distillation aims to synthesize a smaller dataset based on the original dataset while ensuring that models trained on the synthetic data achieve similar results to those trained on the original dataset. Existing algorithms include kernel-based and matching-based methods. Kernel-based methods, such as those utilizing the Neural Tangent Kernel (NTK) and Empirical Neural Network Gaussian Process (NNGP) kernel, generate synthetic datasets through ridge regression optimization. Matching-based methods encompass parameter matching, performance matching, and distribution matching, with gradient matching being a widely used technique.
Diffusion Models
Diffusion models have demonstrated stable and versatile generative capabilities compared to other approaches like GANs or VAEs. These models gradually add random noise to real data and learn to reverse this process, recovering the original data distribution. Diffusion models have been successfully applied to various tasks, including image resolution enhancement, image restoration, future frame prediction, and anomaly detection.
Generative Dataset Distillation
Recent studies have explored the integration of generative models in dataset distillation. Examples include KFS, IT-GAN, and DiM, which leverage the inherent ability of generative models to create new data. These approaches improve training efficiency and effectiveness by generating additional informative training samples. The proposed method in this paper integrates an effective variant of the Stable Diffusion model into the dataset distillation framework, resulting in a more efficient method for distilled image synthesis.
Methods
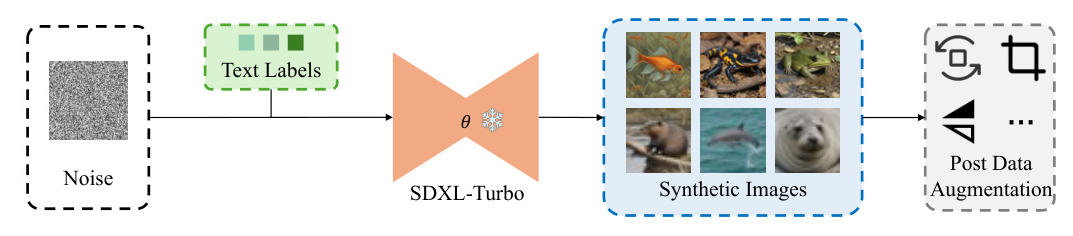
The goal of the proposed method is to distill datasets with limited time and resources, leveraging the prior knowledge and controllability of generative models. The core of the approach lies in the use of SDXL-Turbo, a diffusion model trained with an adversarial diffusion distillation (ADD) strategy. SDXL-Turbo synthesizes high-fidelity images with only 1-4 steps during inference time.
Overall Procedure
The method employs the Text2Image (T2I) pipeline within SDXL-Turbo, where category labels from the original dataset are formatted as prompts. All distilled images are obtained after one-step sampling.
Fast and High-Fidelity Dataset Distillation
The real-time sampling of SDXL-Turbo benefits from its ADD training strategy, which includes adversarial loss and distillation loss. Adversarial training ensures the generated images align with the original manifolds, while distillation training leverages the substantial prior knowledge embedded in the pretrained diffusion model. Unlike other one-step synthesis methods, SDXL-Turbo retains the iterative optimization capability of diffusion models.
T2I Dataset Distillation
Category labels provide crucial information that can be embedded as conditions in diffusion models to guide the image generation process. The trained diffusion model leverages text labels as prompt information during training.
Post Data Augmentation
To enhance the information richness of distilled images without increasing computational complexity, post data augmentation (PDA) is applied. This involves methods such as image cropping, rotation, and flipping. PDA significantly improves the distilled performance by increasing the number of IPC.
Experiments
Implementation Details
The proposed method is based on SDXL-Turbo, with pretrained checkpoints from the official Huggingface repository. The model utilizes half-precision tensors, and prompts consist of corresponding category labels. Post Data Augmentation is applied after the sampling process to maximize the diversity of distilled images. The environmental requirements include Python ≥ 3.9, Pytorch ≥ 1.12.1, Torchvision ≥ 0.13.1, and Diffusers == 0.29.2.

Experimental Results
The experimental results demonstrate that PDA directly increases the number of IPC and significantly improves the distilled performance. The accuracy increased on both Tiny-ImageNet and CIFAR-100 datasets. The top-10 category visualization results show high-fidelity and realistic images generated by the diffusion model, with data augmentation further enhancing their diversity and quality.

Discussion
Distribution Discrepancy
Traditional dataset distillation methods ensure that the distribution of the distilled dataset aligns with the original dataset. However, generative models may introduce significant discrepancies between their distributions. The effectiveness of dataset distillation declines with lower resolution datasets like Tiny-ImageNet and CIFAR-100 due to substantial distribution discrepancies and information loss.
Conclusion
The proposed generative dataset distillation method based on the SDXL-Turbo diffusion model demonstrates high-speed and high-quality image generation capabilities. The method achieves impressive results in dataset distillation, particularly with large IPC. Future work aims to develop more effective distillation techniques with generative models across different datasets.
This blog post provides an in-depth overview of the paper “Generative Dataset Distillation Based on Diffusion Model,” highlighting the innovative approach and experimental results. The proposed method showcases the potential of diffusion models in enhancing dataset distillation, paving the way for future advancements in this field.