

Authors:
Jerry Huang、Prasanna Parthasarathi、Mehdi Rezagholizadeh、Sarath Chandar
Paper:
https://arxiv.org/abs/2408.08470
Introduction
The advent of large language models (LLMs) has revolutionized natural language processing, enabling models to perform tasks with human-like proficiency. However, the computational demands of these models pose significant challenges, particularly in resource-constrained environments. One major bottleneck is the high latency associated with auto-regressive generation, where each token generation requires a full inference pass through the model. This paper explores a novel approach to mitigate this issue through context-aware assistant selection, leveraging multiple draft models to accelerate inference without compromising performance.
Methodology
Motivation
The primary goal is to reduce the latency of large target models (Me) by using smaller draft models to approximate the target model’s output. However, a single draft model may not be sufficient if the target model has multiple areas of expertise. By dynamically selecting the most appropriate draft model based on the context, the system can achieve significant speedups across various domains.
Problem Formulation
The problem is framed as a contextual bandit scenario, where a policy must select a draft model based on a given query (context). Each draft model (arm) provides a reward, which is the time it takes to generate the output sequence through speculative decoding. The objective is to learn a policy π(·|q) that selects the draft model yielding the highest reward for any given context.
Offline Data Collection
An offline dataset is created by generating outputs for a set of queries using both the target model and multiple draft models. A similarity metric is used to score the alignment between the target and draft model outputs. These scores, along with cost penalties, form the basis for training the policy.
Decision Making
The policy is trained using the offline dataset, where each state-action-reward tuple represents a query, a draft model, and the corresponding reward. The policy aims to maximize the expected reward by selecting the most suitable draft model for each query. The REINFORCE policy gradients method is used for training.
Experimental Results
Experimental Setup
The experiments involve publicly available LLMs, with various draft models differing in alignment with the target model, sizes, and architectures. The tasks include translation (IWSLT2017 EN-DE) and text summarization (XSUM).
Learning to Choose the Draft Model
The first experiment uses T5 encoder-decoder models, with Flan-T5-XXL as the target and T5-Small models as draft candidates. The results show that the policy can effectively select the appropriate draft model for each domain, achieving significant speedups without explicit information about the draft models.
Balancing Quality and Speed
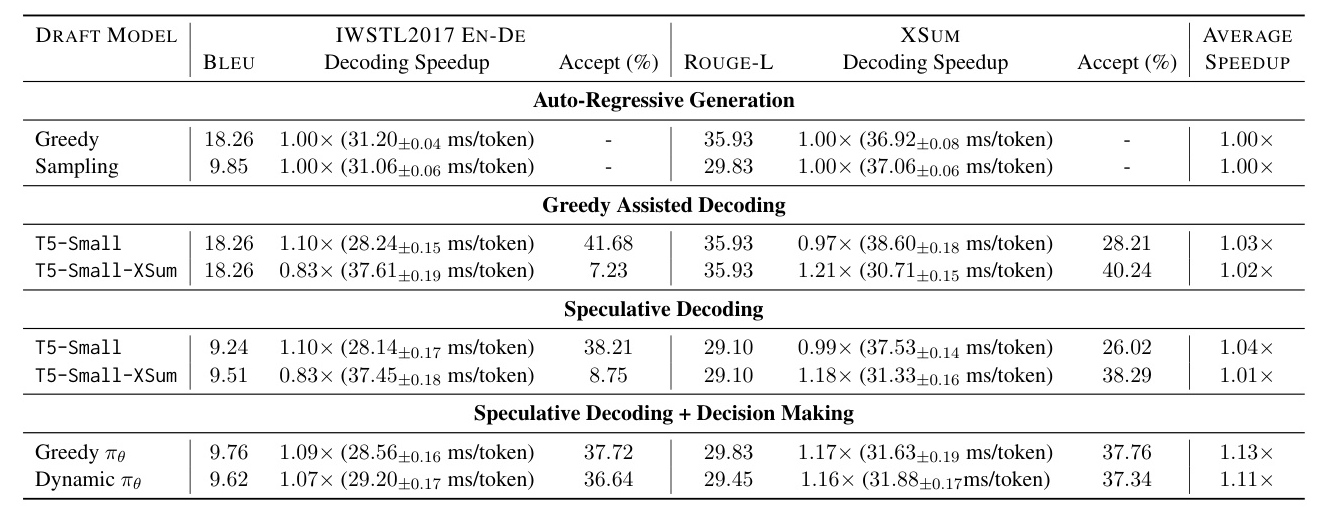
The second experiment evaluates draft models of different sizes and alignments on the XSUM task. The results demonstrate that the policy can balance the tradeoff between output alignment and draft model size, adapting to preferences set by a weighting parameter (α).
Number of Examples Needed
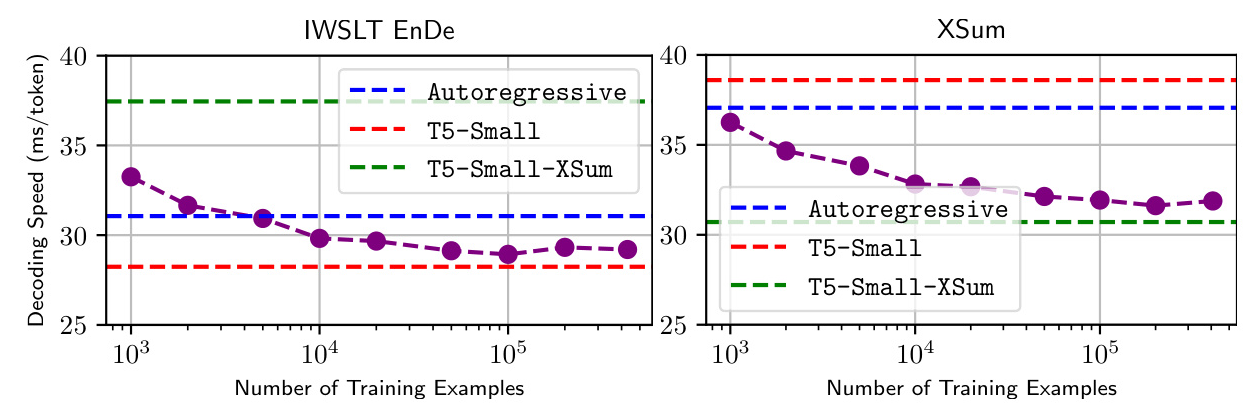
The policy’s ability to learn from a minimal number of examples is tested. The results indicate that training on fewer than 10,000 examples is sufficient to achieve performance comparable to training on the entire dataset.
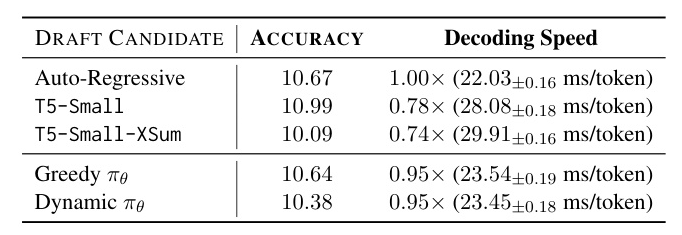
Auto-Regressive Generation as an Option
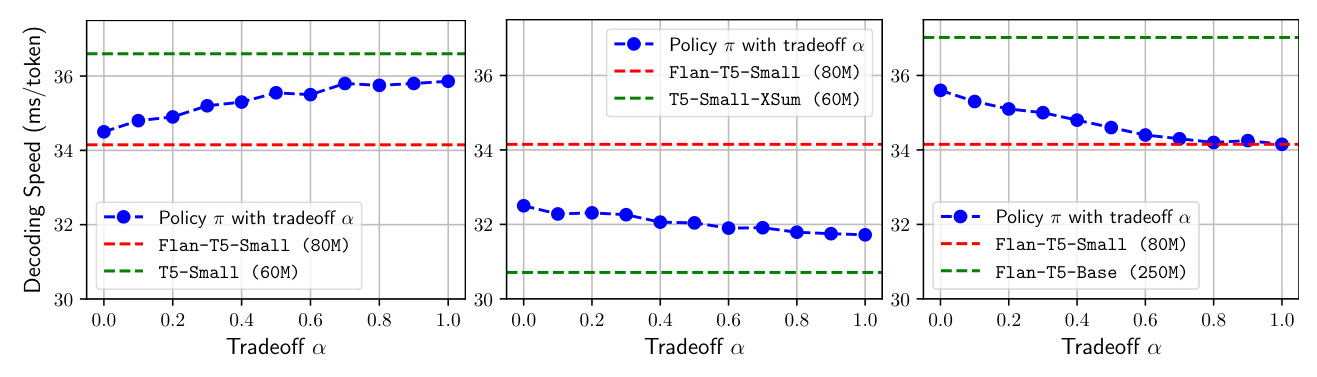
The policy is tested with the option to choose auto-regressive generation. The results show that the policy can effectively ignore draft models when they are not useful, maintaining or even improving decoding speed.

Generalization to Multi-Task Drafters
The policy is further tested on SpecBench using a Vicuna-33B target with smaller draft models. The results confirm that the policy-based selection method is robust and generalizable to different settings.
Ablation with Self-Drafting
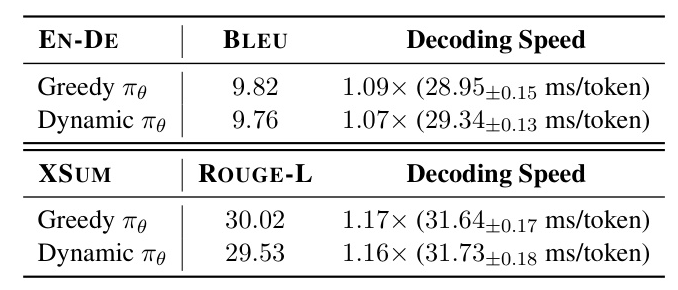
An additional ablation study explores self-drafting, where the draft model exists within the target model. The results show that the policy can minimize performance loss and maintain efficiency even in this setting.
Discussion
LLM Routing
The concept of model routing, where queries are directed to the most suitable model, shares similarities with the proposed method. The policy acts as a router, selecting the best draft model based on the query.
Adaptive Speculative Decoding
The method introduces a level of adaptivity to speculative decoding by dynamically selecting draft models. Future work could explore more complex adaptivity, such as adjusting hyperparameters during the decoding process.
Decision Making for Assisted Decoding
The proposed method adds a decision-making step at the beginning of the decoding process, selecting the best draft model. Future work could integrate this with other decision-making aspects of assisted decoding.
Measuring Alignment Between Outputs
Token-level similarity scores are effective for training the policy, but future work could explore better metrics for draft/target alignment, capturing more semantic meaning and structural elements.
Speculative Decoding as Approximate Inference
Speculative decoding can be viewed as a form of approximate inference. Future work could explore multiple draft models to better generalize to unseen settings.
Conclusion
This work presents a novel approach to integrate assisted generation with multiple black-box draft models. The problem is modeled as a contextual bandit scenario, and an offline reinforcement learning approach is used to train a policy for selecting the best draft model. The results demonstrate significant speedups and robustness, highlighting the potential of this method for various applications.
Limitations
Choice of Draft Models and Data Domains
The results may vary in settings where domain boundaries are not well-defined. The absence of sufficient pre-trained models for comparison limits immediate exploration.
Additional Storage and Memory
Using multiple draft models requires additional memory, which can be challenging in resource-constrained environments. Collecting an offline dataset can also be difficult in scenarios with long input/output sequences.
Self-Drafting
The study does not involve additional training of parameters linked to the language model. Future work could explore applying the method to settings involving additional training.
Ethics Statement
The paper discusses a method for dynamically selecting draft models for speculative decoding, focusing on decoding speed. The results are unlikely to lead to ethical concerns or problematic interpretations.
Acknowledgements
Jerry Huang received financial support from NSERC, FRQNT, and Hydro-Québec. Sarath Chandar is supported by a Canada CIFAR AI Chair, the Canada Research Chair in Lifelong Machine Learning, and an NSERC Discovery Grant.