Authors:
Paper:
https://arxiv.org/abs/2408.08682
Introduction
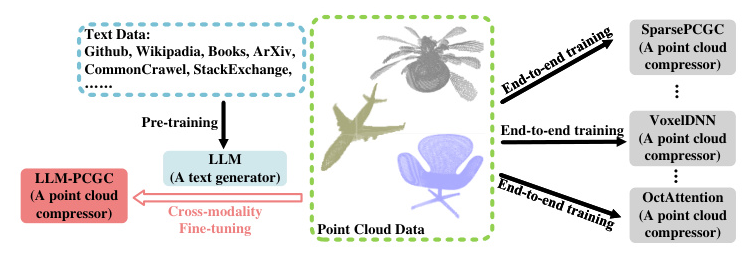
Point cloud data is essential for applications like autonomous driving and virtual reality. The challenge lies in compressing this data efficiently while preserving its intricate 3D structure. Traditional methods, both voxel-based and tree-based, have limitations in context modeling due to constraints in data volume and model size. This paper introduces a novel approach, leveraging the capabilities of large language models (LLMs) for point cloud geometry compression (PCGC).
Framework Overview
Encoding Pipeline
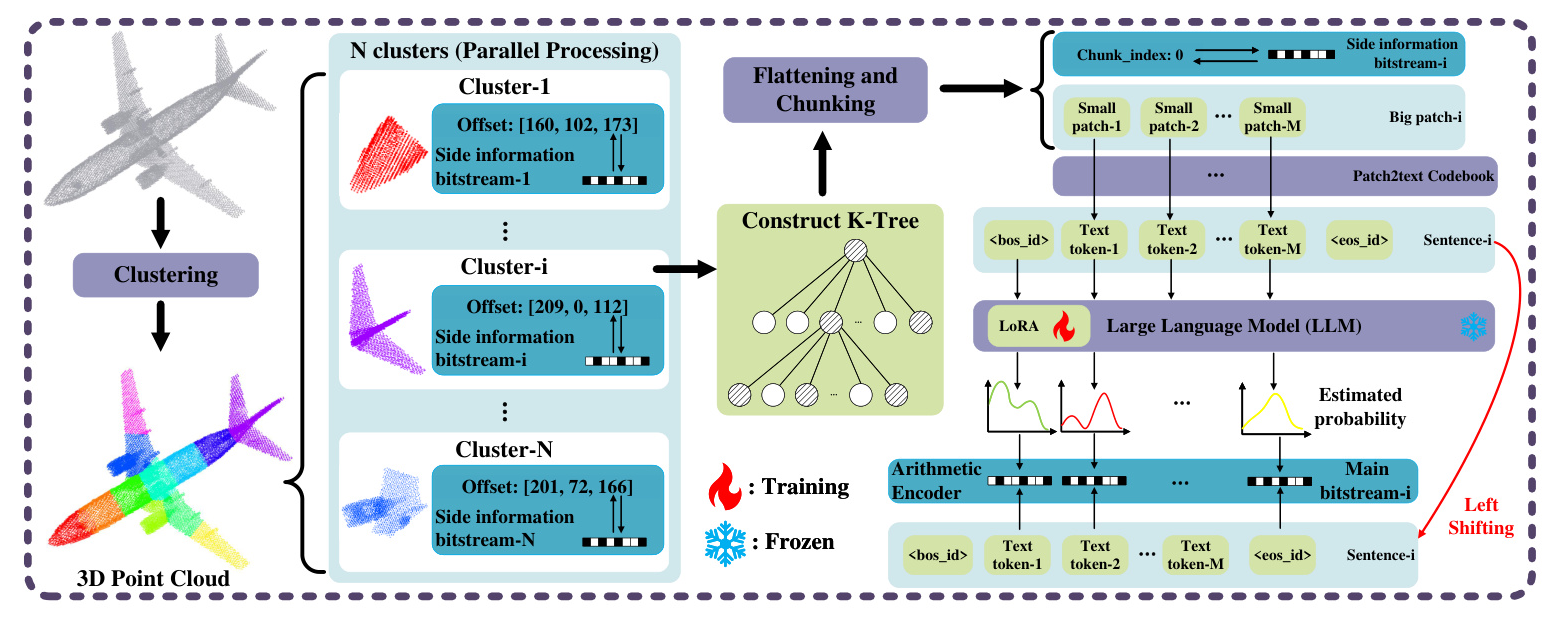
The encoding process begins with clustering the input 3D point clouds. Each cluster undergoes several steps:
- Normalization: Coordinates are normalized by subtracting an offset.
- K-Tree Structuring: The data is organized into a K-tree structure.
- Flattening and Chunking: The hierarchical tree structure is flattened and divided into segments.
- Token Conversion: Point cloud tokens are translated into text tokens using a codebook.
- Probability Distribution: A trained Low Rank Adaptation (LoRA) model with a frozen LLM predicts the probability distribution for the next token.
- Arithmetic Encoding: The probability distributions are fed into an arithmetic encoder, generating the encoded bitstream.
Decoding Pipeline
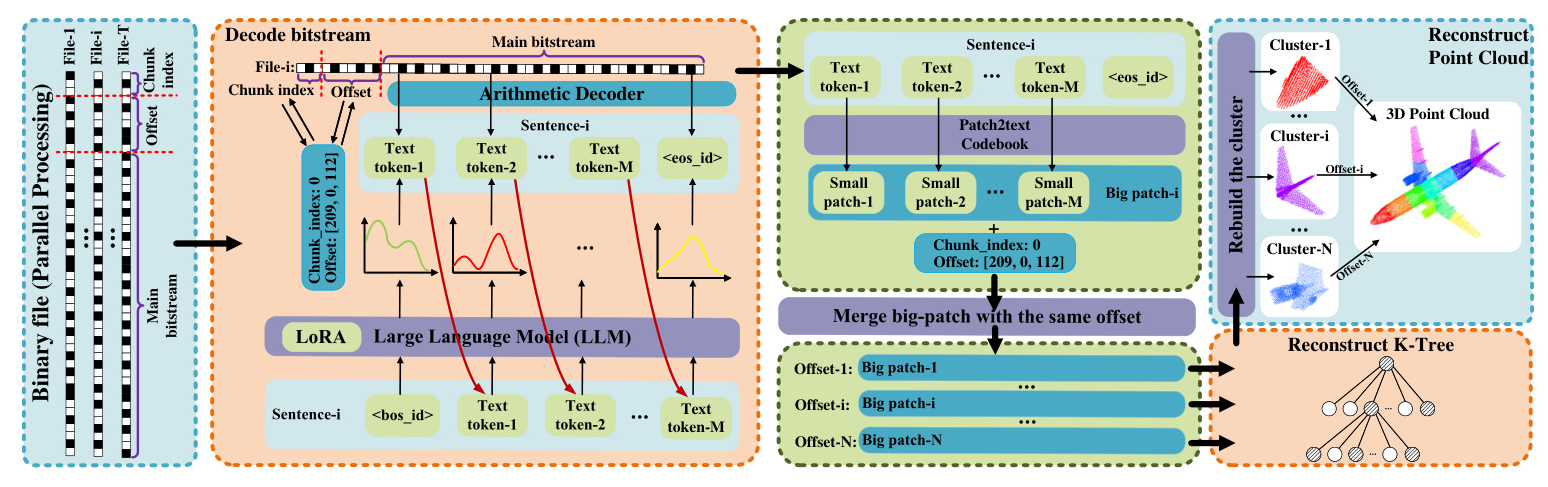
The decoding process mirrors the encoding steps in reverse:
- Binary File Processing: Binary bits are split and converted to decimals.
- Arithmetic Decoding: The main bitstream is decoded using probabilities from the LoRA and LLM.
- Token Mapping: Text tokens are translated back into point cloud patch tokens.
- Reconstruction: Patches are aligned and merged based on offsets and indices, and a K-tree structure is used for clustered point cloud reconstruction.
- Post-Reconstruction: Offsets are applied to rebuild the original point cloud.
Experiments
Training and Testing Setting
The experiments involved training two sets of LLM-PCGC parameters on different datasets to ensure fair comparison. The datasets used include Microsoft Voxelized Upper Bodies (MVUB), 8i Voxelized Full Bodies (MPEG 8i), ShapeNet, and ModelNet40. The testing followed the common test condition (CTC) recommendations, evaluating on MPEG 8i and Owlii datasets.
Base Model and LoRA Setting
The foundational model chosen for this experiment was LLaMA2-7B, an open-source LLM. The LoRA and Embedding modules of LLaMA2-7B were fine-tuned, with the total number of trainable parameters amounting to only 6.7% of the original model’s parameters.

Experiment Results
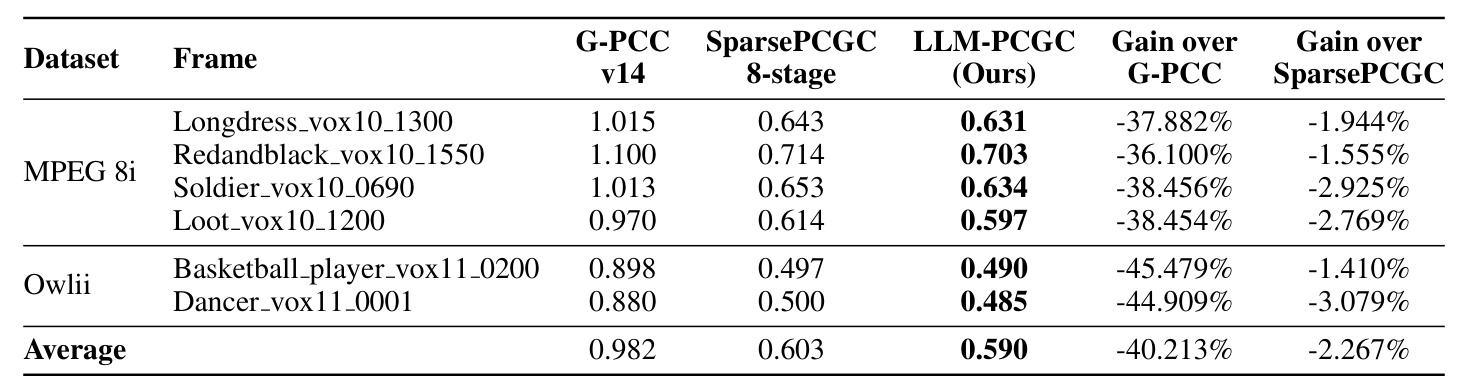
The LLM-PCGC method demonstrated significant performance improvements:
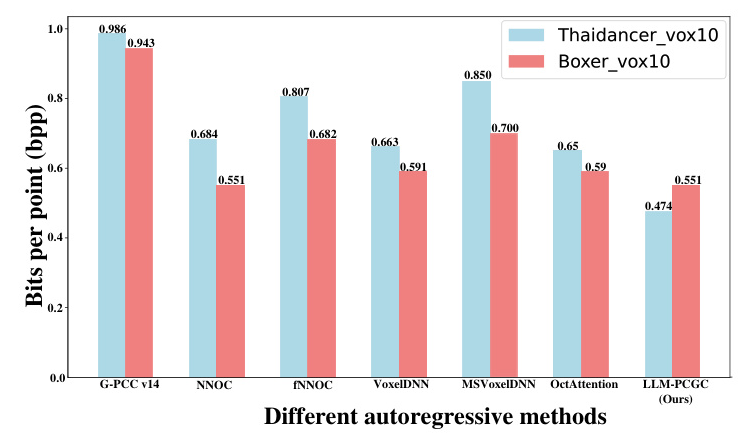
- Bit Rate Reduction: Achieved a -40.213% bit rate reduction compared to the G-PCC standard and a -2.267% reduction compared to the state-of-the-art learning-based method.
- Compression Efficiency: Recorded an average of 0.52 bits per point (bpp) for the MPEG 8i dataset, outperforming other autoregressive methods.
Conclusion
The LLM-PCGC method is the first to employ LLMs as compressors for point cloud data within the “Generator is compressor” framework. By utilizing adaptation techniques like clustering, K-tree, token mapping invariance, and LoRA, the method achieves efficient cross-modality representation alignment and semantic consistency. Experimental results show superior compression performance over existing methods, highlighting the potential of LLMs in data compression. Future research can focus on optimizing memory consumption and inference time.