Authors:
Dongyu Ru、Lin Qiu、Xiangkun Hu、Tianhang Zhang、Peng Shi、Shuaichen Chang、Jiayang Cheng、Cunxiang Wang、Shichao Sun、Huanyu Li、Zizhao Zhang、Binjie Wang、Jiarong Jiang、Tong He、Zhiguo Wang、Pengfei Liu、Yue Zhang、Zheng Zhang
Paper:
https://arxiv.org/abs/2408.08067
Introduction
Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by incorporating external knowledge bases, enabling more precise and contextually relevant responses. However, evaluating these systems presents several challenges due to their modular nature, the complexity of long-form responses, and the reliability of existing metrics. To address these challenges, the authors propose RAGChecker, a fine-grained evaluation framework designed to provide comprehensive diagnostics for both the retrieval and generation components of RAG systems.
Related Work
Retrieval Augmented Generation
RAG systems have shown impressive performance across various tasks, including open-domain question answering, code generation, and dialogue. These systems are particularly valuable in fields requiring high precision and reliability, such as legal, medical, and finance.
Evaluation of RAG
Existing evaluation practices for RAG systems can be categorized into two main approaches: evaluating essential capabilities of generators and assessing end-to-end performance. However, these approaches often fall short in providing a comprehensive evaluation, especially for long-form responses.
RAGChecker Framework
Formulation
A modular RAG system is defined as RAG = {R, G}, where R is the retriever and G is the generator. Given a query q and documents D, the system retrieves top-k relevant contexts and generates a model response. The overall RAG generation process can be represented as m = RAG(q, D).
Design Principle
RAGChecker is designed to cater to two major personas: users who care about overall performance and developers who focus on improving the system. The framework provides metrics that reveal error causes and overall performance, helping both personas to assess and refine RAG systems.
Inputs to RAGChecker
Each sample in the benchmark dataset is prepared in the format of a tuple ⟨q, D, gt⟩, representing the query, documents, and ground-truth answer. This setup allows for a detailed evaluation of the system’s performance.
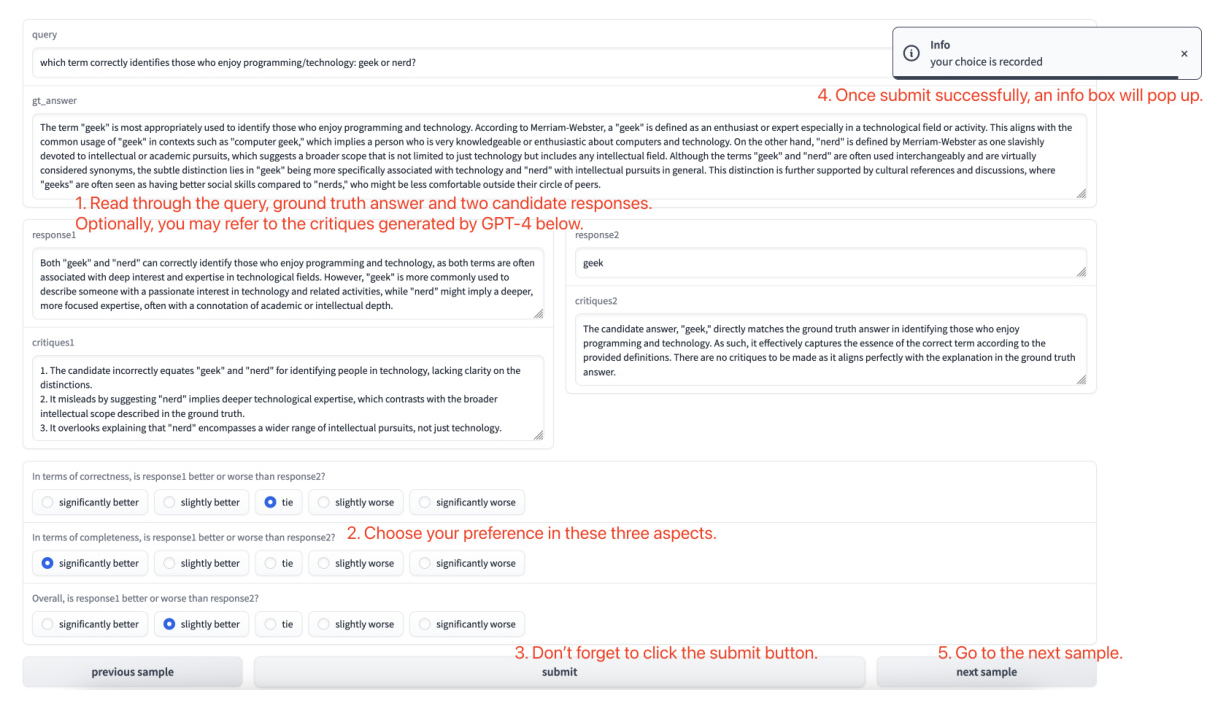
Fine-grained Evaluation with Claim Entailment
RAGChecker introduces a text-to-claim extractor and a claim-entailment checker to evaluate responses at a finer granularity. This approach helps in comprehensively assessing the quality of an answer by identifying correct, incorrect, and missing claims.
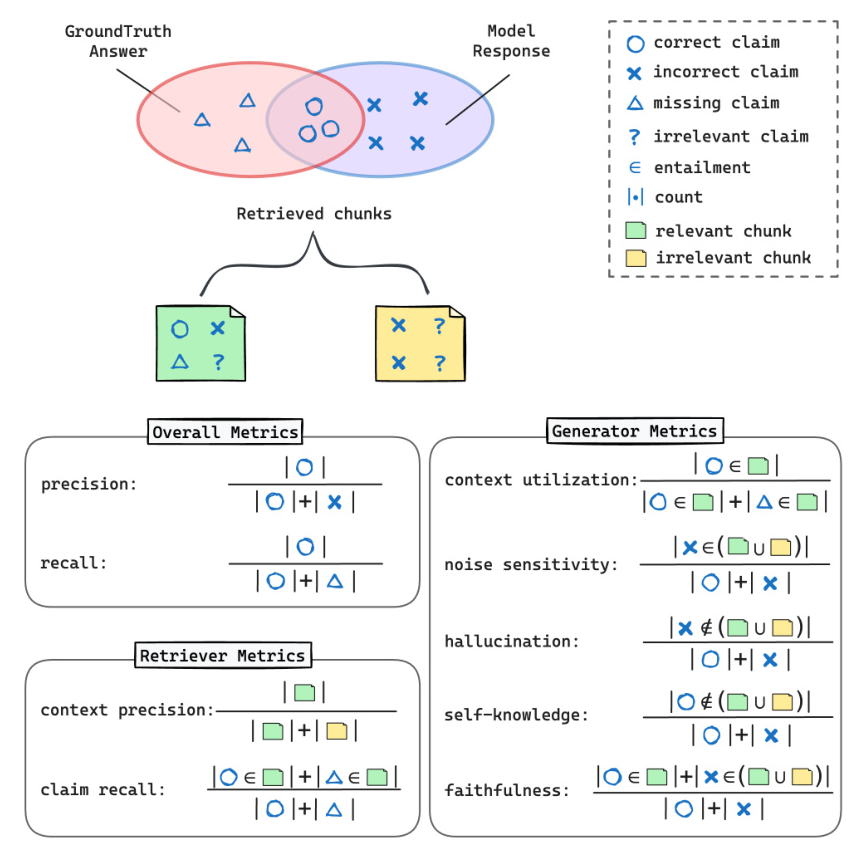
RAGChecker Metrics
Overall Metrics
Overall metrics assess the response quality from a user’s perspective, including precision, recall, and F1 score at the claim level.
Retriever Metrics
Retriever metrics evaluate the effectiveness of the retriever in finding relevant information. These metrics include claim recall and context precision.
Generator Metrics
Generator metrics assess the performance of the generator, focusing on aspects like faithfulness, noise sensitivity, hallucination, self-knowledge, and context utilization.
Experiments
Experimental Setup
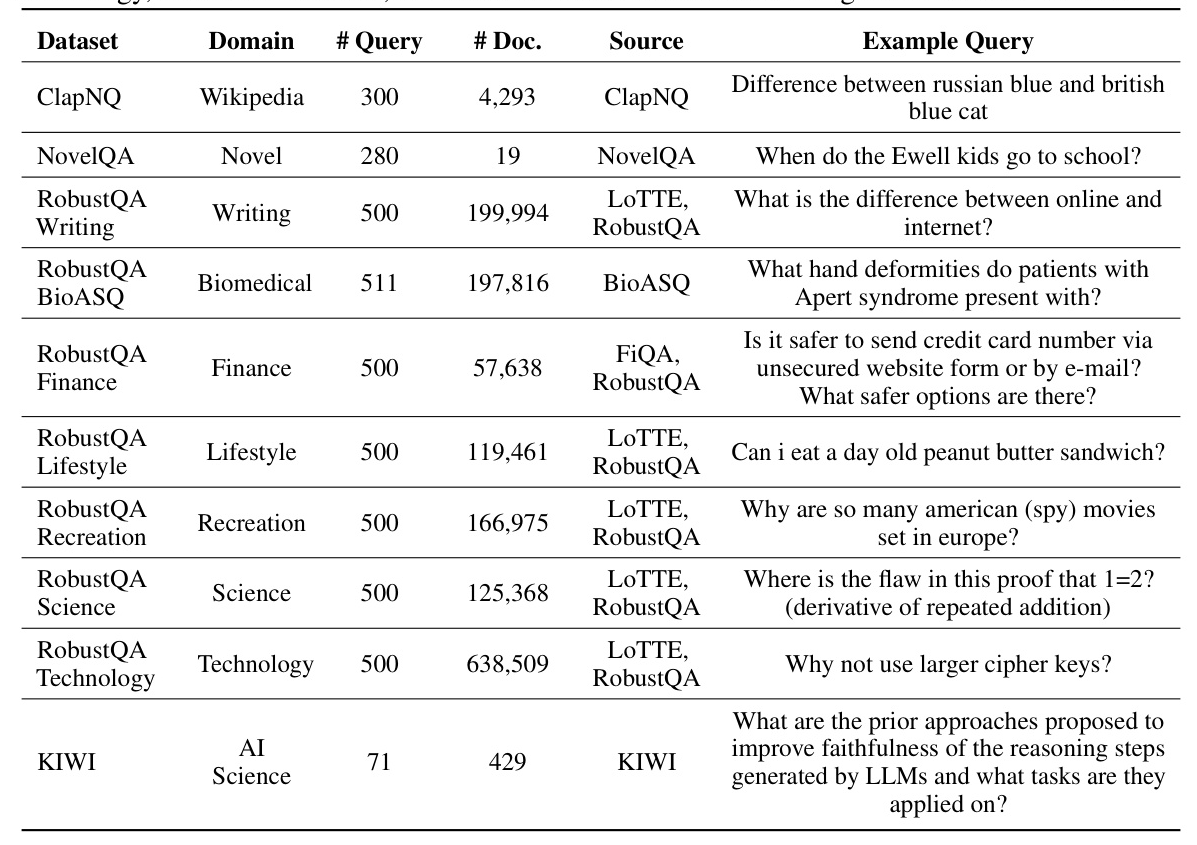
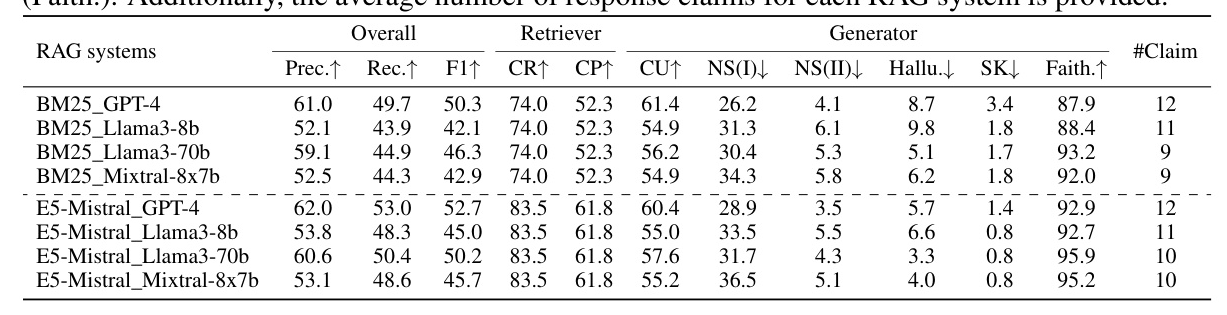
The authors apply RAGChecker to 8 customized RAG systems, combining 2 retrievers (BM25 and E5-Mistral) and 4 generators (GPT-4, Mixtral-8x7B, Llama3-8B, and Llama3-70B). The benchmark dataset contains 4,162 queries across 10 domains, repurposed from public datasets.
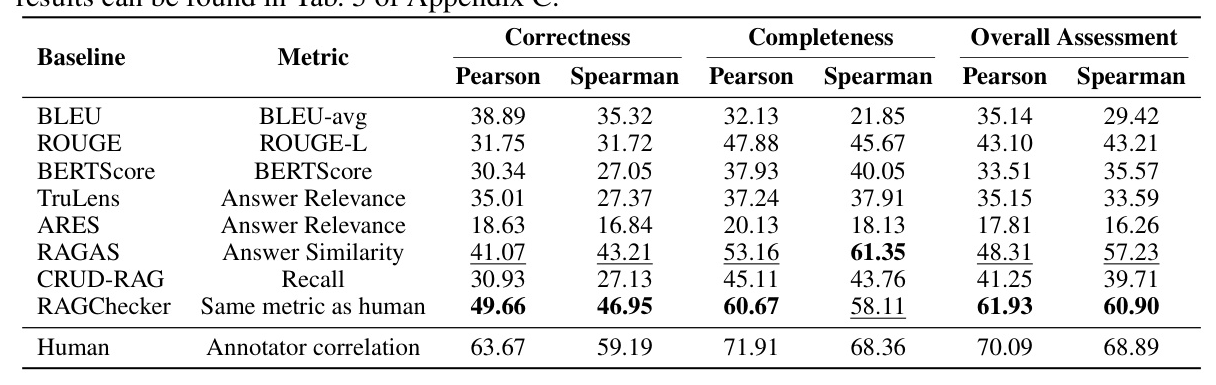
Meta Evaluation
The meta evaluation verifies the soundness of RAGChecker by comparing it with existing baseline RAG evaluation frameworks. The authors construct a meta evaluation dataset with sampled instances from the generated responses of 8 baseline RAG systems.
Main Results
The evaluation results for 8 RAG systems across 10 diverse domain datasets reveal several insights:
- Retriever Matters Consistently: The quality of retrieval significantly impacts overall performance.
- Generator Model Size Brings All-Round Improvement: Larger generator models consistently achieve better performance.
- Stable and Performant Context Utilization is Key: Context utilization strongly correlates with overall F1 score.
- Informative Context Improves Faithfulness and Reduces Hallucination: Better claim recall leads to improved faithfulness and reduced hallucination.
- Retriever Recall Trades-off with Generator Noise Sensitivity: Increased claim recall can introduce more noise, affecting generator performance.
- Relevant Noise Sensitivity is More Challenging: Generators are more sensitive to noise in relevant chunks.
- Open-Source Models are Worse at Distinguishing Accurate Information from Noise: Open-source models tend to trust the context blindly, especially with better retrieval.
Diagnosis on RAG Settings for Improvements
Guided by the observations, the authors experiment with different settings, such as the number of chunks, chunk sizes, chunk overlap ratios, and generation prompts. Key findings include:
- More Context Enhances Faithfulness: Increasing the number and size of chunks improves recall and faithfulness.
- Explicit Requirements in Prompts Affect Generation Preferences: Prompts with explicit requirements can improve faithfulness but may introduce noise sensitivity.
- Chunk Overlap Does Not Matter a Lot: Chunk overlap minimally affects generation performance.
Conclusion
RAGChecker is a novel evaluation framework designed for RAG systems, providing a comprehensive suite of metrics validated through rigorous human assessments. The framework offers valuable insights into the behaviors of retriever and generator components, guiding future advancements in RAG applications.