Authors:
Jacob Kauffmann、Jonas Dippel、Lukas Ruff、Wojciech Samek、Klaus-Robert Müller、Grégoire Montavon
Paper:
https://arxiv.org/abs/2408.08041
The Clever Hans Effect in Unsupervised Learning: An Interpretive Blog
Introduction
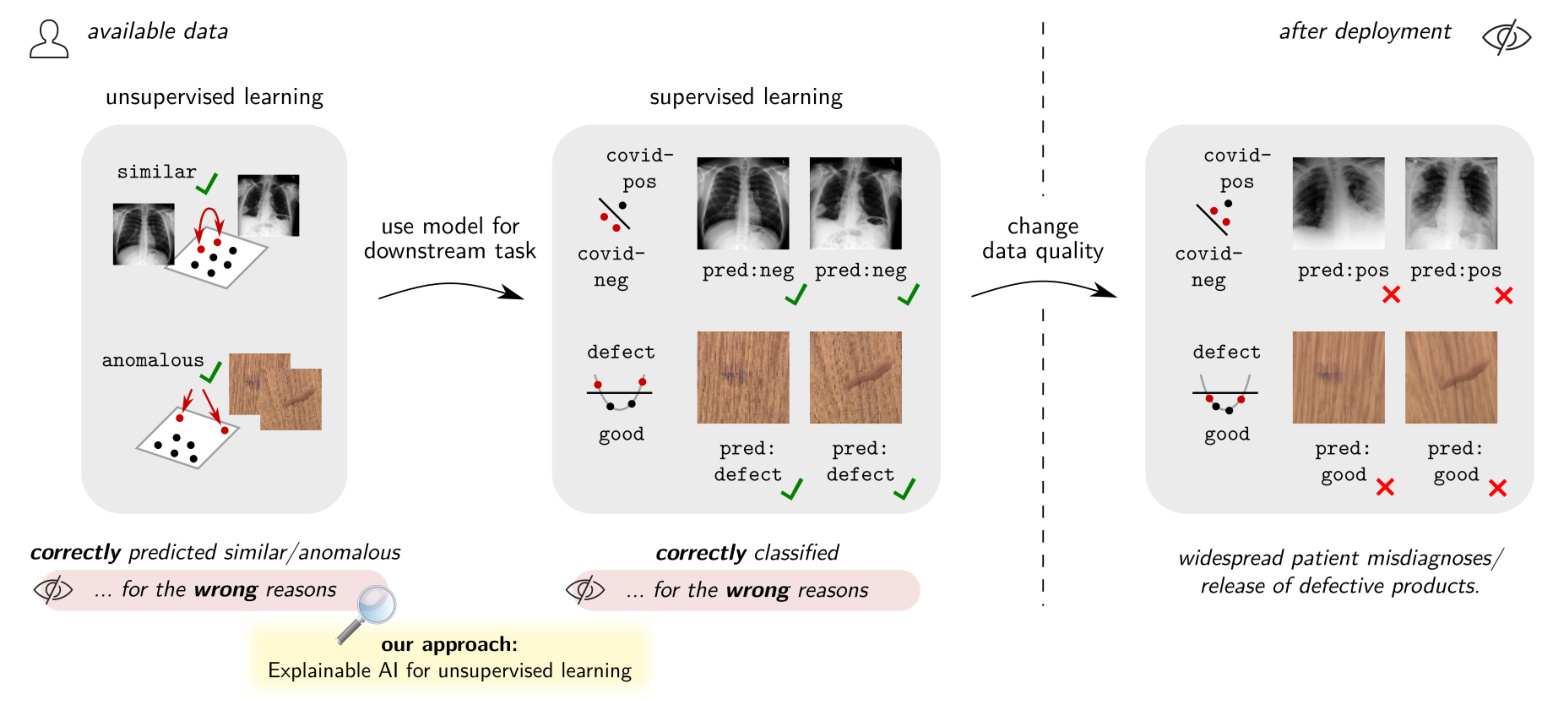
Unsupervised learning has become a cornerstone of modern AI systems, providing foundational models that support a wide array of downstream applications. However, the reliability of these models is crucial, as their predictions can significantly impact subsequent tasks. This paper investigates the prevalence of the Clever Hans (CH) effect in unsupervised learning models, where models make correct predictions for the wrong reasons. Using Explainable AI techniques, the authors reveal the widespread nature of CH effects in unsupervised learning and propose methods to mitigate these effects, enhancing model robustness.
Abstract
Unsupervised learning models are integral to AI systems, producing representations critical for various applications. This paper highlights the Clever Hans (CH) effect in unsupervised learning, where models make accurate predictions based on irrelevant features. The study uses Explainable AI techniques to uncover these effects, attributing them to inductive biases in the learning algorithms. The findings emphasize the need for robust unsupervised learning models to prevent flawed predictions from affecting downstream tasks.
Introduction
Unsupervised learning addresses limitations of supervised learning, such as the lack of labeled data. It has been successful in various domains, including anomaly detection and foundation models. However, the increasing reliance on unsupervised learning necessitates a thorough examination of how these models make predictions. The paper demonstrates that unsupervised learning models often suffer from CH effects, where predictions are based on data artifacts rather than meaningful features. This issue can lead to significant errors in downstream applications, especially when data conditions change post-deployment.
Results
Clever Hans Effects in Representation Learning
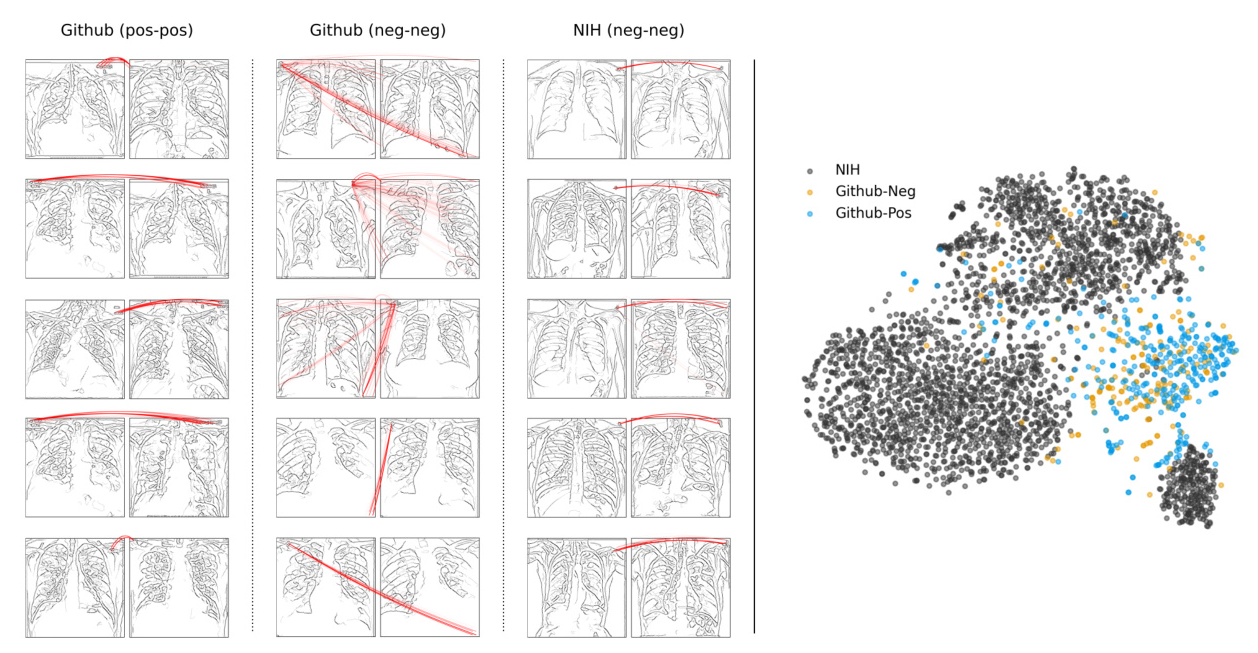
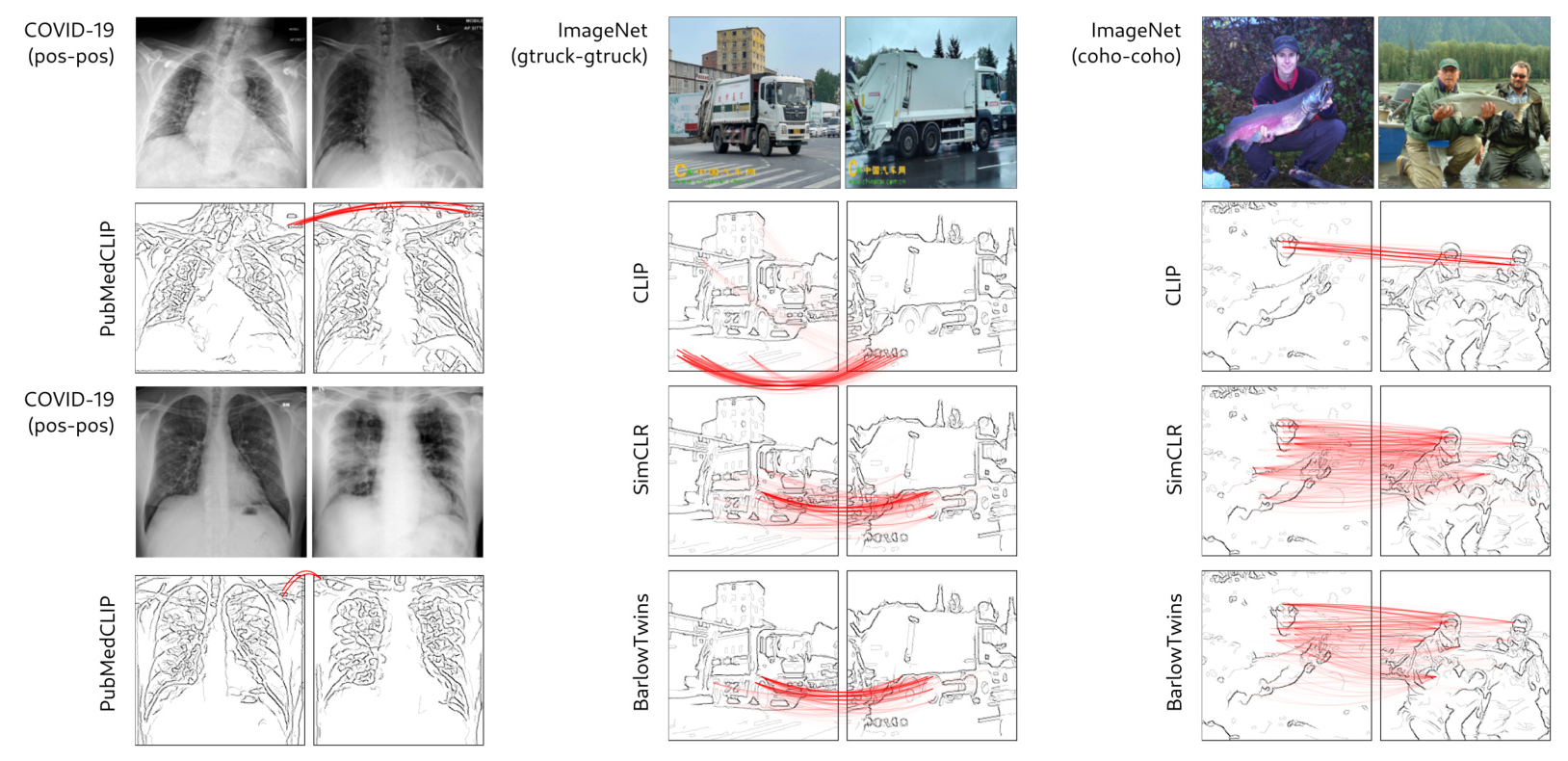
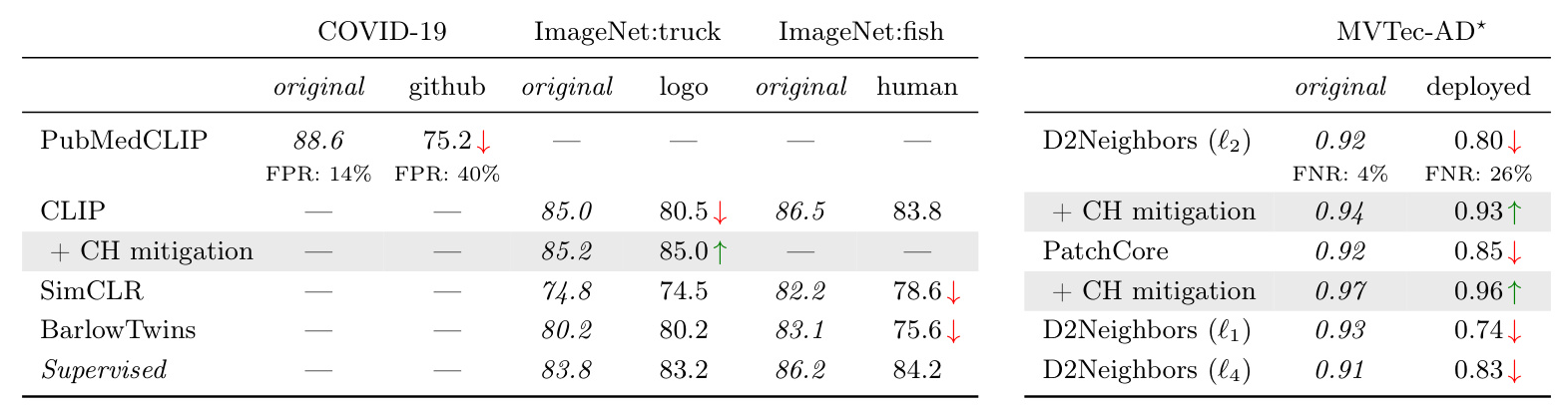
The study first examines representation learning in detecting COVID-19 from X-ray scans. Using a dataset combining NIH’s CXR8 and GitHub-hosted COVID-19 images, the authors train a classifier based on the PubMedCLIP model. Despite achieving high overall accuracy, the model shows a disparity in performance between the NIH and GitHub subsets, with a high false positive rate for the latter. Explainable AI techniques, specifically BiLRP, reveal that the model’s predictions are based on textual annotations in the images, a clear CH effect.
Further analysis of other foundation models (CLIP, SimCLR, BarlowTwins) on ImageNet data shows similar CH effects. For instance, CLIP relies on textual logos for similarity predictions, while SimCLR and BarlowTwins focus on irrelevant features like human presence in the background. These flawed strategies lead to performance degradation when the data conditions change, highlighting the need for robust unsupervised models.
Clever Hans Effects in Anomaly Detection
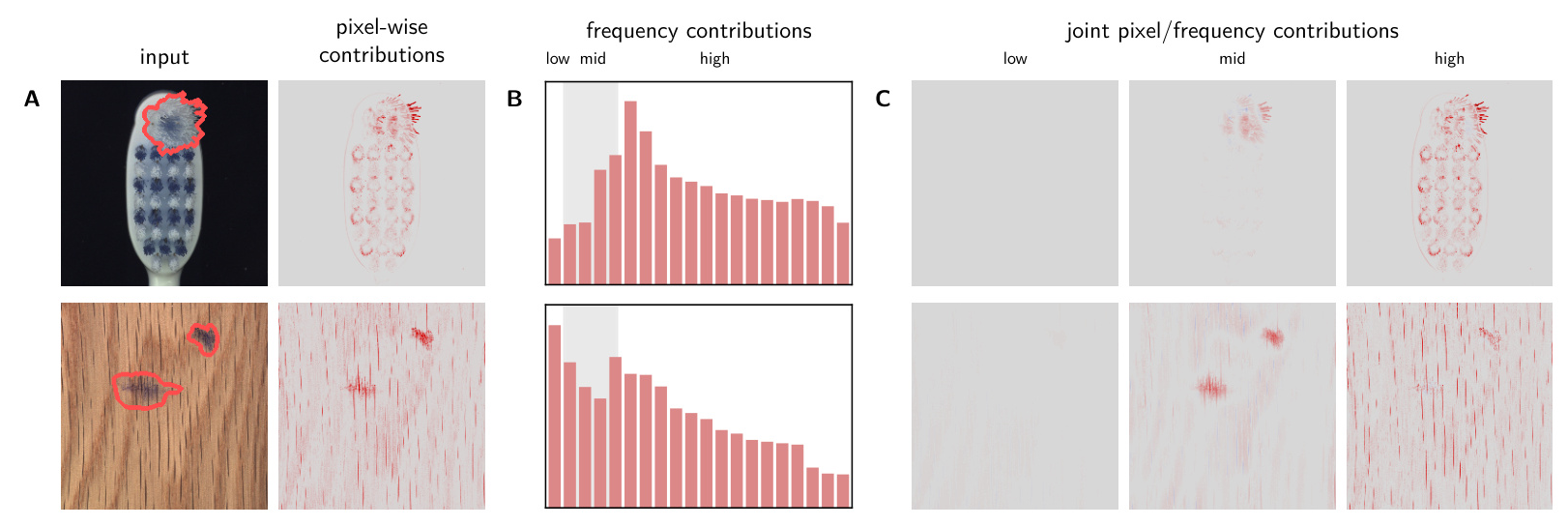
The paper extends the investigation to anomaly detection using the MVTec-AD dataset. The D2Neighbors model, which predicts anomalies based on distances to training data, shows high performance initially. However, Explainable AI analysis reveals that the model relies on irrelevant high-frequency features. When the image resizing algorithm is changed post-deployment, the model’s performance degrades significantly, increasing the false negative rate. This degradation underscores the importance of robust anomaly detection models that can handle changes in data quality.
Alleviating CH in Unsupervised Learning
To mitigate CH effects, the authors propose modifying the unsupervised models directly. For the CLIP model, they remove feature maps responsive to text, improving robustness. Similarly, for anomaly detection, they introduce a blur layer to prune high frequencies. These modifications significantly enhance model performance in post-deployment conditions, demonstrating the effectiveness of targeted CH mitigation strategies.
Discussion
The paper emphasizes the critical role of unsupervised learning in AI systems and the need to address CH effects to ensure reliable predictions. Unlike supervised learning, CH effects in unsupervised models arise more from inductive biases in the learning algorithms than from the data itself. The authors advocate for addressing CH effects directly in the unsupervised models to achieve persistent robustness, benefiting multiple downstream tasks. The study also highlights the potential for extending these findings to other data modalities and unsupervised learning instances.
Methods
ML Models and Data for Representation Learning
The study uses several unsupervised models, including SimCLR, CLIP, BarlowTwins, and PubMedCLIP, trained on datasets like ImageNet and combined NIH-GitHub COVID-19 images. The models are analyzed using Explainable AI techniques to uncover CH effects.
ML Models and Data for Anomaly Detection
For anomaly detection, the D2Neighbors and PatchCore models are evaluated on the MVTec-AD dataset. The study simulates different data preprocessing conditions to assess model robustness post-deployment.
Explanations for Representation Learning
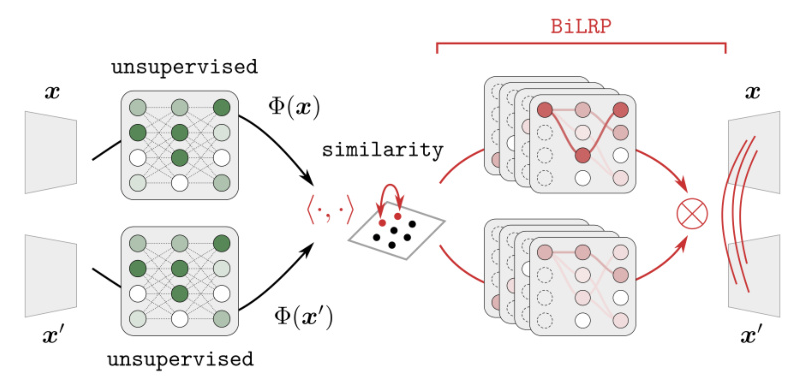
The BiLRP method extends LRP to explain similarity scores in representation learning models. It provides detailed explanations of how input features contribute to model predictions, revealing CH effects.
Explanations for the D2Neighbors Model
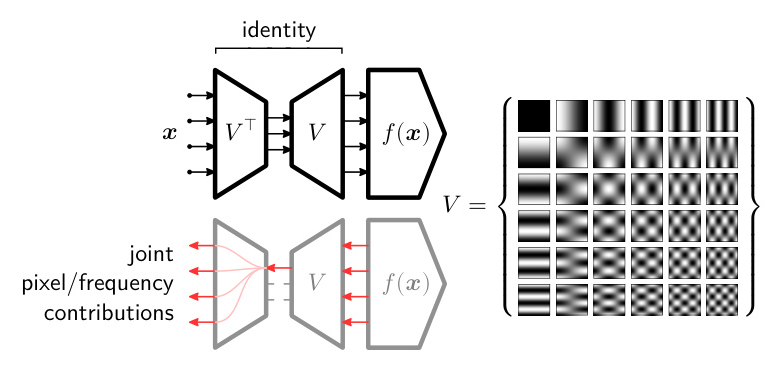
The D2Neighbors model’s anomaly predictions are explained using LRP and virtual layers, mapping input features to pixel-frequency domains. This analysis identifies irrelevant high-frequency features contributing to CH effects.
Conclusion
The paper provides a comprehensive analysis of CH effects in unsupervised learning, highlighting their prevalence and impact on downstream tasks. By leveraging Explainable AI techniques, the authors propose effective strategies to mitigate these effects, enhancing the robustness of unsupervised models. This work underscores the importance of scrutinizing unsupervised learning models to ensure reliable AI systems.