

Authors:
Jiajie Li、Garrett Skinner、Gene Yang、Brian R Quaranto、Steven D Schwaitzberg、Peter C W Kim、Jinjun Xiong
Paper:
https://arxiv.org/abs/2408.07981
Introduction
The field of surgery is inherently multimodal, involving dynamic sequences of actions and multi-stage processes that cannot be fully captured through static imagery. While large language models (LLMs) have shown significant promise in medical question answering, their application has been largely limited to static images. This paper introduces LLaVA-Surg, a novel multimodal conversational assistant designed to understand and engage in discussions about surgical videos. The key contributions include the creation of Surg-QA, a large-scale dataset of surgical video-instruction pairs, and the development of a two-stage question-answer generation pipeline to enhance data quality and reduce hallucinations.
Related Work
Surgical Video Question Answering (Surgical VQA)
Early Surgical VQA models treated the task as a classification problem, excelling in identifying surgical steps, instruments, and organs but struggling with open-ended questions. Recent generative methods have improved but are limited to single-turn conversations. LLaVA-Surg advances this by enabling multi-turn dialogues, providing comprehensive surgical knowledge for an interactive learning experience.
Multimodal LLM for Biomedical Image Conversations
Multimodal LLMs have shown potential in interpreting and generating detailed medical image descriptions, aiding diagnostics and patient communication. However, their application to surgical videos remains unexplored. LLaVA-Surg aims to fill this gap by integrating visual and language data to enhance video understanding and generate contextually relevant responses.
Multimodal LLM for Video Conversations
General-domain multimodal models like Video-LLaVA and Video-ChatGPT have demonstrated the potential for real-time, contextually aware responses in video contexts. However, their applicability to domain-specific videos like surgical videos has not been proven. LLaVA-Surg leverages these advancements to create a specialized model for surgical video conversations.
Surgical Video Instruction-tuning Data Generation
Surgical Knowledge Pyramid
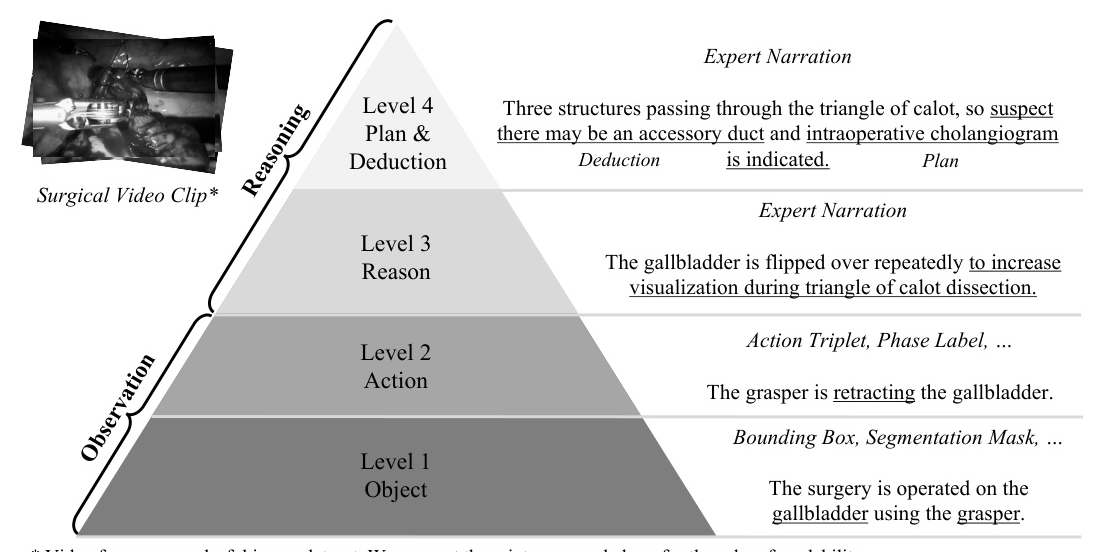
Surgical video interpretation can be categorized into four levels: basic identification of surgical objects, recognition of discrete surgical actions, higher-order reasoning of surgical actions, and expert-level deduction and planning. Existing datasets lack information at levels 3 and 4, which are crucial for comprehensive understanding. Surg-QA addresses this by including all four levels of information.
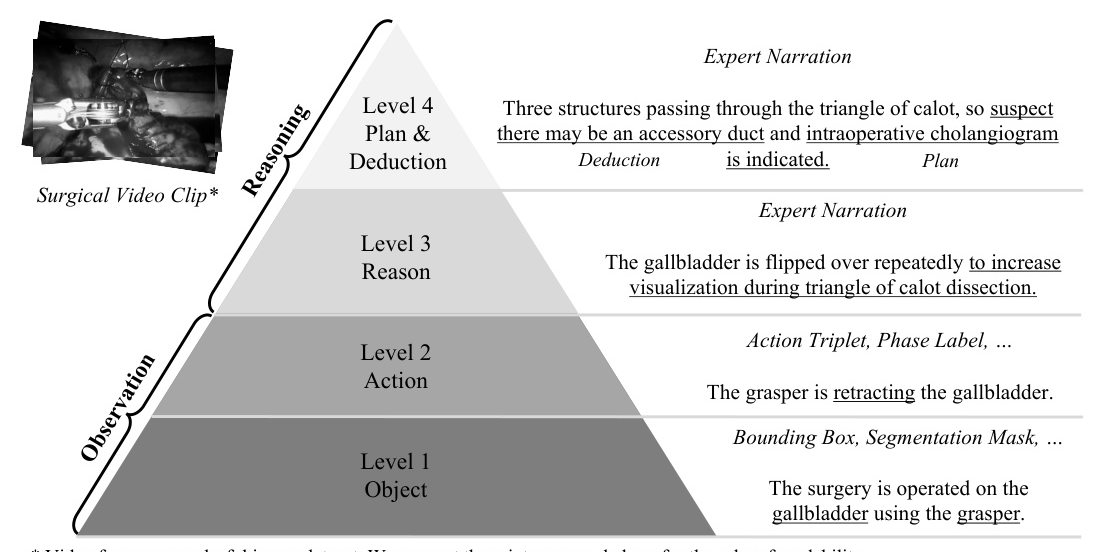
Structured Surgical Video Learning
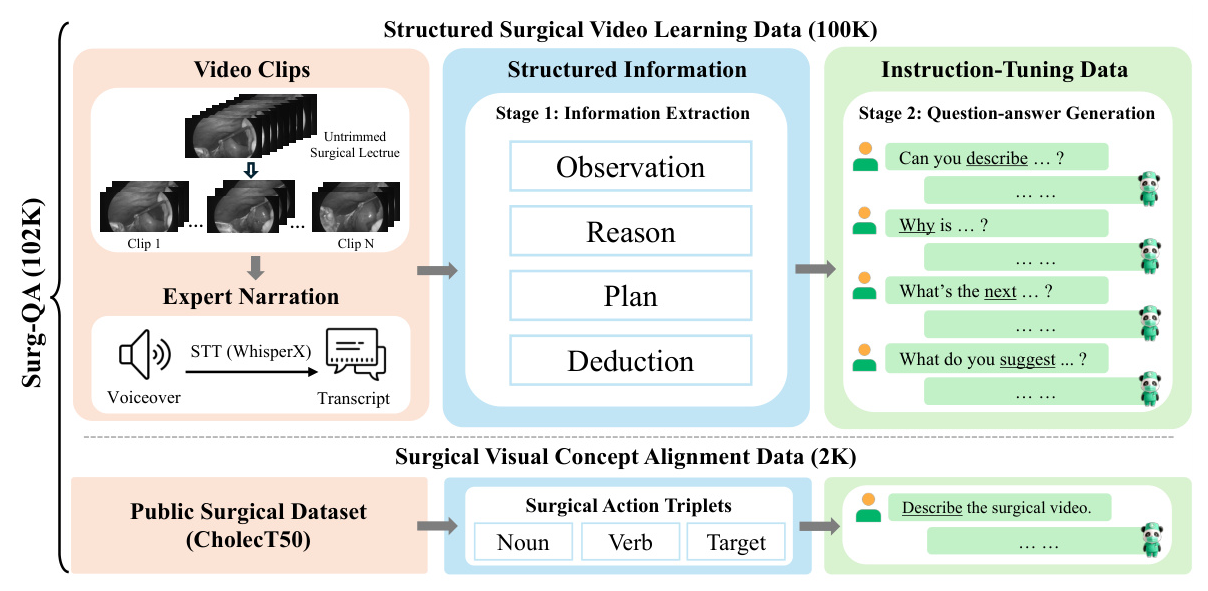
The two-stage extraction-generation approach utilizes the Llama-3-70B model for processing surgical video lectures. The first stage involves transcribing the spoken content of surgical lecture videos into text using WhisperX. The second stage extracts key information from the transcripts, focusing on observation, reason, plan, and deduction. This structured representation ensures high-quality data and reduces the risk of LLM hallucination.
Surgical Visual Concept Alignment
Based on the public surgical dataset CholecT50, this data helps the model recognize fundamental surgical visual concepts such as instruments, organs, and actions. The dataset includes concise descriptions of surgical videos generated from action triplets, enhancing the model’s ability to understand and describe surgical procedures.
Comparisons
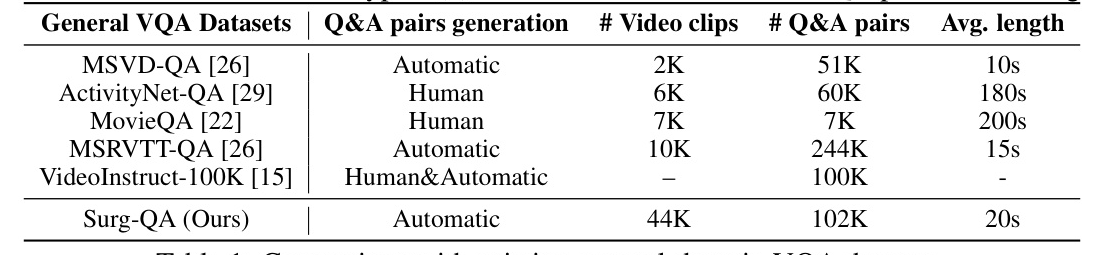
Surg-QA is substantial in size, with 44K videos and 102K QA pairs, making it comparable to general-domain VQA datasets. It surpasses traditional surgical-domain VQA datasets by including more surgical procedures and a wider range of surgical types, providing video-wise question-answer pairs rather than frame-wise annotations.
Surgical Visual Instruction Tuning
Architecture
LLaVA-Surg employs the architecture of Video-ChatGPT, sampling frames from a video and calculating frame-level features using CLIP ViT-L/14. These features are fused through a temporal-fusion operation to derive video-level features, which are then fed through a linear projection layer that connects to the language model.

End-to-End Instruction-Tuning
The model is fine-tuned on 90K surgical video instruction-following data, combining structured surgical video learning data and concept alignment data. This training process balances knowledge from all four levels of the surgical knowledge pyramid, enabling the model to follow various instructions and complete tasks in a conversational manner.
Experiments
Implementation Details
The dataset includes 2,151 surgical procedures, divided into training and test sets. The instruction-tuning data generation pipeline uses WhisperX for transcription and Llama-3-70B-Instruct for information extraction and data generation. The model is fine-tuned on 90K surgical video instruction-following data using CLIP ViT-L/14 as the image encoder.
Quantitative Evaluation
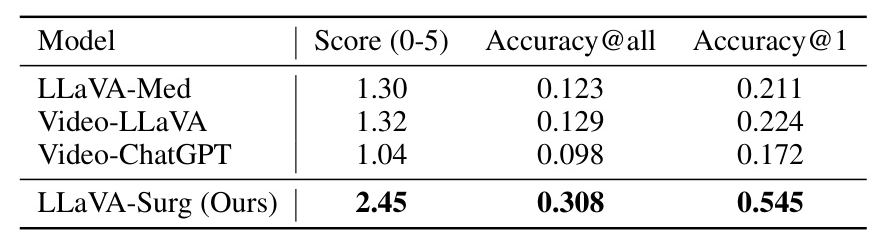
The model’s performance is evaluated on the test split of Surg-QA, consisting of 4,359 open-ended surgical video question-answer pairs. GPT-3.5-Turbo is used for evaluation, scoring the model’s outputs based on their accuracy and relevance. LLaVA-Surg outperforms other significant models like Video-LLaVA and Video-ChatGPT, demonstrating its ability to understand surgical video content and generate accurate, contextually rich answers.
Human Expert Evaluation
A human expert (surgeon) evaluated a subset of the experimental results, assigning scores based on their understanding of the surgical videos. The strong correlation between the scores assigned by the human expert and GPT indicates that the GPT evaluation framework effectively aligns with human expert judgment.

Qualitative Evaluation
LLaVA-Surg accurately identifies surgical procedures and answers subsequent questions, outperforming models like LLaVA-Med. Examples illustrate the model’s ability to describe surgical videos and provide detailed, contextually relevant answers.
Conclusion
LLaVA-Surg introduces Surg-QA, a large-scale surgical video instruction-tuning dataset, and a two-stage question-answer generation pipeline to enhance data quality. The model demonstrates exceptional multimodal conversational skills in understanding and engaging in discussions about surgical videos. Future work will focus on engaging experts to review generated samples to improve the accuracy and reliability of LLaVA-Surg.
