

Authors:
Mohamed Osman、Daniel Z. Kaplan、Tamer Nadeem
Paper:
https://arxiv.org/abs/2408.07851
Introduction
Speech Emotion Recognition (SER) has become a pivotal area of research due to its potential to enhance human-computer interaction by making it more natural and empathetic. Recent advancements in self-supervised learning (SSL) have led to the development of powerful speech representation models such as wav2vec2, HuBERT, and WavLM. Despite their impressive performance on various speech processing tasks, these models face significant challenges in generalizing across diverse languages and emotional expressions.
Existing SER benchmarks often focus on a limited set of well-studied datasets, which may not accurately reflect real-world scenarios. Moreover, the emphasis on in-domain evaluation fails to capture the crucial aspect of out-of-domain generalization, which is essential for practical applications. To address these limitations, this paper introduces a large-scale benchmark that evaluates SER models on a diverse collection of multilingual datasets, emphasizing zero-shot performance.
Related Work
Self-supervised learning has revolutionized speech representation learning, enabling models to capture rich acoustic features without relying on labeled data. Models like wav2vec 2.0, HuBERT, and WavLM have achieved state-of-the-art performance on various speech processing tasks, including speech recognition, speaker identification, and emotion recognition.
Cross-lingual SER has gained attention as a means to develop models that can generalize across languages. However, existing studies often focus on a limited set of languages and datasets, making it difficult to assess the true generalization capabilities of the models. Well-known SER benchmarks such as IEMOCAP and MSP-Podcast have played a crucial role in advancing the field but often emphasize in-domain evaluation.
Recent works such as EMO-SUPERB and SERAB have made notable contributions to SER but have limitations in terms of the diversity of languages, datasets, and the emphasis on out-of-domain generalization. This paper aims to address these limitations by introducing a large-scale benchmark that focuses on out-of-domain generalization and includes a diverse set of multilingual datasets.
Methodology
Dataset Selection and Preprocessing
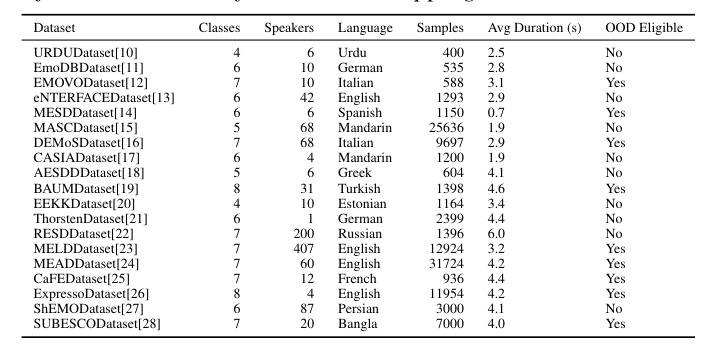
A diverse collection of multilingual datasets was curated for the benchmark, covering various languages and emotional expressions. The datasets were preprocessed to ensure consistency and compatibility with the evaluation protocol. The maximum audio length was set to 30 seconds, and the audios were processed appropriately for each backbone model tested. The label space was remapped to a unified eight-class space to facilitate cross-dataset comparisons. The datasets used for out-of-domain evaluations were matched by having the same classes, excluding ‘other’.
Backbone Models
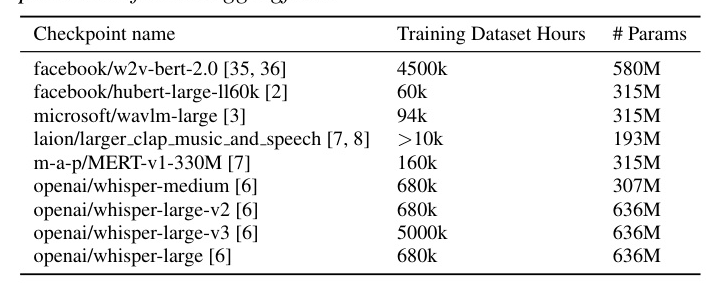
State-of-the-art speech representation models were employed as backbones for the benchmark. These models were selected based on their strong performance on various speech processing tasks and their ability to capture rich acoustic features. In addition to SSL models, the benchmark also evaluated MERT, a music recognition model, and CLAP, a contrastive learning model. The Whisper encoder, trained under an encoder-decoder setup for ASR, was also evaluated.
Model Architecture and Training
A simple multilayer perceptron (MLP) architecture with approximately 500K parameters was employed for emotion classification. The MLP consisted of two hidden layers and was trained for 100 epochs. Label smoothing with a factor of 0.1 was applied to improve generalization. Instead of averaging the features before classification, the MLP was executed on every feature frame, and the mean of the predictions was taken.
Logit Adjustment
To account for varying class distributions across datasets, logit adjustment was employed during evaluation. This technique adjusts the model’s output logits based on the difference between the training and testing dataset distributions, mitigating the impact of class imbalance and enabling fair comparisons.
Evaluation Protocol
The evaluation protocol established a subset of datasets as out-of-domain (OOD) eligible, which had the same exact classes after the class mapping. For each model, a performance matrix was constructed where the rows represented the training datasets and the columns represented the evaluation datasets. In-domain performance was indicated by diagonal elements, while off-diagonal elements corresponded to out-of-domain zero-shot performance. The quality of the backbone models was assessed based on three key metrics: in-domain separability, out-of-domain performance given training dataset, and average performance on unseen datasets.

Results and Discussion
In-domain Separability
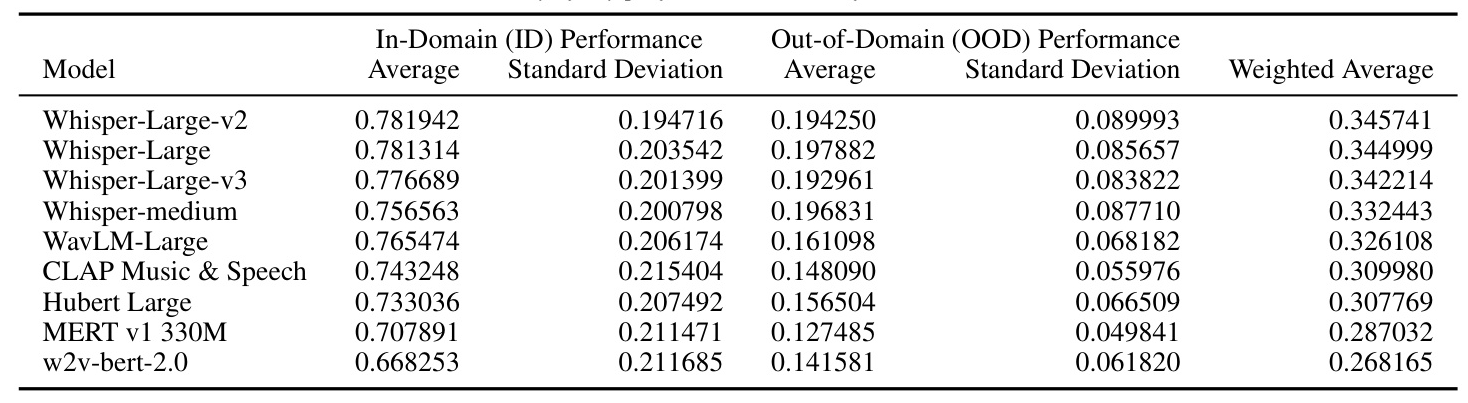
The in-domain separability performance of various models was evaluated, focusing on their ability to distinguish between different emotional states in speech. The Whisper-Large-v2 model led in in-domain SER performance, with the highest mean accuracy and low variability across datasets. Other models like Whisper-Large-v3, Whisper-medium, WavLM-Large, and CLAP Music & Speech showed competent but slightly more variable performances. Models like Hubert Large, MERT v1 330M, and w2v-bert-2.0 exhibited the lowest accuracies with higher fluctuations in their effectiveness across different datasets.
Out-of-domain Performance Given Training Dataset
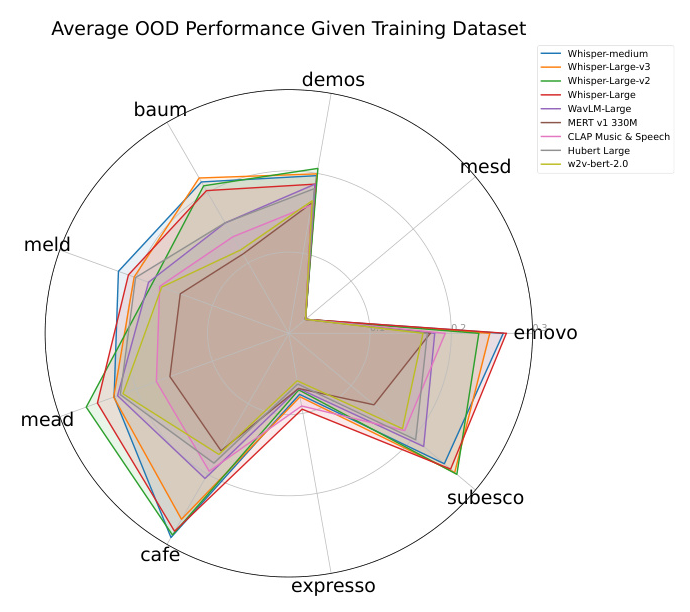
The average out-of-domain performance for each model was evaluated. The Whisper models demonstrated the highest out-of-domain performance, indicating their superior generalization capabilities compared to the SSL models. However, there was high variability in OOD performance across training sets. Training on some datasets like BAUM led to much better OOD generalization than others like MELD.
Average Performance on Unseen Datasets
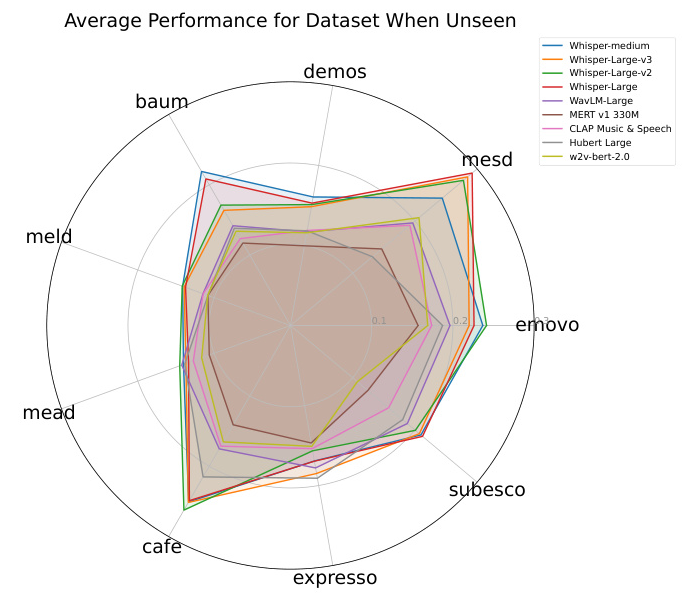
The average performance of the evaluated models on each dataset when the models were not trained on that dataset was assessed. The results highlighted the varying levels of difficulty across datasets, with some datasets posing greater challenges for out-of-domain generalization. Notably, EMOVO, MELD, and MEAD were the most challenging for models not trained on them, while models generalized best to URDU and AESDD.
General Outcomes
The Whisper models consistently achieved the highest scores across all metrics, further confirming their effectiveness in cross-lingual SER. However, the high standard deviations indicated that performance was quite variable depending on the specific train/test combination. This suggested that model robustness is still a challenge and there is room for improvement in developing models that perform consistently well across diverse datasets.
Conclusion
This paper introduced a comprehensive benchmark for evaluating the robustness and generalization of speech emotion recognition models across diverse languages and emotional expressions. The benchmark focused on less commonly used datasets to mitigate overfitting and encourage the development of more robust models. Through extensive experiments with state-of-the-art speech representation models, it was found that the Whisper model, primarily designed for automatic speech recognition, outperformed dedicated SSL models in cross-lingual SER.
The benchmark, along with the released code and evaluation protocol, serves as a valuable resource for the research community to assess and advance the state of cross-lingual SER. The insights gained from this work can guide future research efforts in developing more robust and generalizable SER models.
Future Works
Future directions include exploring advanced techniques for domain adaptation, few-shot learning, and meta-learning to further improve the generalization capabilities of SER models. Additionally, investigating the specific characteristics of datasets that contribute to better generalization can provide valuable insights for dataset design and selection. The hope is that this benchmark and its findings will inspire researchers to push the boundaries of cross-lingual SER and develop models that can effectively handle the diversity of languages and emotional expressions encountered in real-world applications.