

Authors:
Andrea Lops、Fedelucio Narducci、Azzurra Ragone、Michelantonio Trizio、Claudio Bartolini
Paper:
https://arxiv.org/abs/2408.07846
Introduction
Software testing is a critical step in the software development lifecycle, essential for ensuring code correctness and reliability. Within it, unit testing is the stage concerned with verifying the proper functioning of individual code units. Designing and building unit tests is a costly and labor-intensive process that requires significant time and specialized skills. Automating this process represents a promising area for research and development.
Automated tools for generating unit tests can reduce test engineers’ and software developers’ workload. These tools typically use static code analysis methods to generate test suites. For example, EvoSuite combines static code analysis with evolutionary search to achieve adequate coverage. Large Language Models (LLMs), efficiently exploited in various aspects of software development, could also handle the automatic generation of unit tests. However, previous studies on LLMs have focused on simple scenarios, providing a limited view of LLMs’ performance in real-world software development scenarios.
To address these gaps, we have developed an approach for generating and evaluating test suites that are more representative of real-life complex software projects. Our approach focuses on class-level test code generation and automates the entire process from test generation to test assessment. In this work, we introduce AGONETEST, an automated system designed to generate test suites for Java projects, accompanied by a rigorous and systematic methodology to evaluate these generated test suites.
Background and Related Work
Unit Test Generation
Unit test generation is the automated process of creating test cases for individual software components, such as functions, methods, or modules. Present techniques employ randomness-based, constraint-based, or search-based approaches. For example, EvoSuite works by accepting a Java class or method as input and applying search-based algorithms to generate a test suite that meets coverage criteria such as code or branch coverage. However, EvoSuite often produces tests that lack clarity and readability and is limited to projects using Java 9 or lower.
Unlike EvoSuite, AGONETEST incorporates advanced evaluation metrics and test-smell recognition, providing a more comprehensive assessment of the quality of generated test suites and ensuring readability by leveraging human-like LLM-generated code. Moreover, AGONETEST supports all Java LTS versions, allowing projects built on newer versions to be tested as well.
Large Language Models for Test Generation
Since the emergence of LLMs, they have been used for test suite generation. Early techniques treated test generation as a neural machine translation problem, translating from the primary method to the appropriate test prefix or test assertion. For instance, AthenaTest optimizes BART using a test generation dataset. However, AthenaTest focuses mainly on generating method-level tests, while AGONETEST shifts the focus to the generation of class-level tests.
Several proposals for evaluating LLMs in test suite generation have emerged. For example, CHATTESTER proposes a tool for evaluating and improving LLM-generated tests based on ChatGPT but requires human intervention. AGONETEST, on the other hand, provides support for a variety of LLMs and evaluates each LLM’s performance on a wide range of real-life Java projects.
Limits of Current Approaches in Applying LLMs to Unit Test Generation
Current approaches in applying LLMs to unit test generation exhibit several limitations:
– Limited Scope: Current methods are mostly limited to generating code segments rather than whole modules or components.
– Lack of Automation: No work has fully automated the test generation-execution-assessment loop.
– Subjective Choice of Prompts: The choice of prompts remains subjective, leaving room for further exploration and optimization in prompt engineering.
Overview of AGONETEST
The term agone, originating from ancient Greece and Rome, signified a contest wherein philosophers debated their ideas, with the audience determining the victor. We adopt the term agone metaphorically to represent the competitive evaluation of LLMs and their respective prompting strategies within an arena aimed at generating optimal unit test suites.
AGONETEST is designed to provide software testers with a system for generating and assessing unit tests. This assessment focuses on key metrics such as code coverage and the presence of known test smells, thereby offering a comprehensive assessment of test suite quality. AGONETEST operates on the principle that the evaluation of LLMs in the task of generating high-quality unit tests can be performed through the collaboration of test engineers and data scientists (or prompt engineers).
Strategy Configuration
The system helps test engineers through the following phases:
– Sample Projects Selection: The user chooses which repositories to generate test suites for.
– Configuration Parameters Elicitation: Configuration parameters are elicited from the selected repositories and processed to create prompt templates for the LLMs.
Automated Test Generation
- Prompt Creation: The prompt templates are fully instantiated and then used to generate unit test suites.
- Test Suite Generation: AGONETEST orchestrates the interaction with the selected LLMs, feeding them the instantiated prompts to produce the unit test code.
Strategy Evaluation
- Test Suite Assessment: This phase assesses the quality of the test suites by computing various metrics and identifying test smells. This assessment enables a detailed analysis of the effectiveness and quality of the automated test generation strategies.
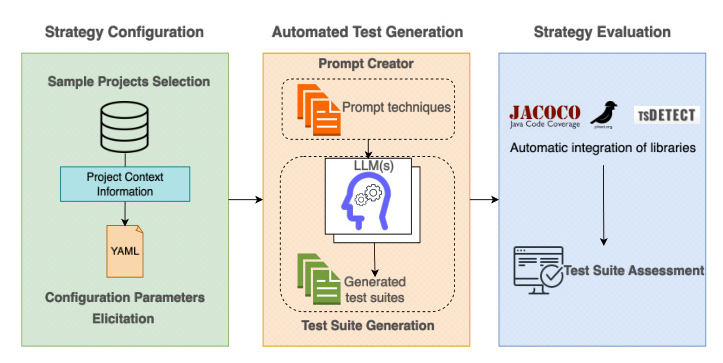
AGONETEST in Practice
In this section, we will demonstrate how AGONETEST operates in practice by describing an end-to-end run of a practical example.
Configuration
AGONETEST utilizes a YAML file as input, where it is possible to specify information related to LLMs and prompts. The YAML file declares the usage of models such as ‘gpt-4’ and ‘gpt-3.5 turbo’ provided by OpenAI. Prompt specification declaration consists of two sections: name and value. The name is an identifier for labeling the type of prompt (zero-shot, few-shots, etc.), while the value is an array of message elements of type OpenAI.
Results Presentation
After running the generation phase, AGONETEST generates a CSV file including, for each LLM selected and each prompting technique, the metrics computed for the focal classes as well as the results about test smells. By examining this file, users can gain valuable insight into the strengths and weaknesses of each LLM and the prompt combination.
Evaluation
In this experimental evaluation, we aim to address the following research questions:
– RQ1: To what extent is it possible to implement an automated end-to-end process for generating test suites?
– RQ2: Can the quality of test suites automatically generated by different LLMs and prompt strategies be effectively assessed?
Dataset
In our experiment, we randomly selected 10 repositories from our dataset CLASSES2TEST. These repositories contain a total of 94 focal classes of various lengths and complexity.
LLMs and Prompts Configuration
For our experiment, we selected two LLMs from the models supported by LiteLLM: ‘gpt-4’ and ‘gpt-3.5 turbo’. The temperature parameter was set to 0 to increase the level of coherence in text generation. We experimented with two types of prompts: zero-shot and few-shot.
Data Collection and Analysis
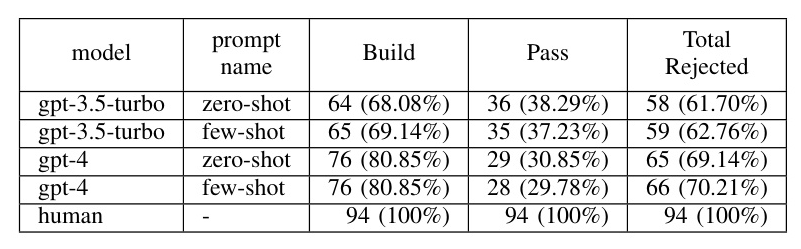
Not all test suites generated from our sample repositories were valid. Some tests failed to build due to syntax errors or incorrect or non-existent imports. The system automatically removes test classes with errors to proceed with the compilation. Once all errors are removed, the system conducts a compile-and-run test to eliminate all classes that are not green suite.

Discussion and Lessons Learned
RQ1: To what extent is it possible to implement an automated end-to-end process for generating test suites?
AGONETEST provides an end-to-end automated process to generate and evaluate test suites without human intervention. However, there are two points requiring attention:
– The compilation success rate of the generated test classes shows room for improvement.
– The percentage of tests passed was relatively low.
RQ2: Can the quality of test suites automatically generated by different LLMs and prompt strategies be effectively assessed?
AGONETEST gives relevant information about the quality of the test suite generated, in terms of code coverage, robustness of the test suite to artificially injected bugs, and test smells. Comparing the output of our LLMs-powered system against tests written by actual test engineers gave us valuable insight into each model-setup pair’s capabilities and limitations.

Lessons Learned
- Compilation and Test Pass Rate: Automating the correction of recurring problems can increase the success rate of the generated tests.
- Performance in Mutation Testing: Improving the robustness of the generated test suites by refining the prompting algorithms and incorporating mutation-aware test generation techniques.
- Scalability and Resource Management: Efficiently managing and parallelizing tasks can alleviate computational overhead and improve scalability.
- Impact of Prompting Techniques: Systematically exploring and evaluating different prompting strategies will help identify the most effective configurations.
- Automated Context Extraction: Enhancing the automation of context extraction by developing more sophisticated parsers and context inference algorithms.
- Real-world Applicability: Continuously upgrading and updating the dataset to include a broader range of real-world repositories and project structures.
Limitations
Dataset and Generalization
The scope of the dataset is limited to Java projects, making the findings hardly generalizable to different programming languages. The repositories included in CLASSES2TEST were selected based on their ability to compile without errors, potentially introducing a bias towards well-structured codebases.
Model and Prompt Variability
The initial experimental setup involved only two models and two prompt types. The limited scope of the initial tests could restrict the breadth of the conclusions. Different temperature settings could yield more varied results, which were not explored in this study.
Compilation and Execution Failures
Approximately 66% of the test classes generated were either rejected during the compilation phase or failed to contribute positively to the metrics due to inherent errors.
Evaluation Metrics
The metrics alone may not fully capture the quality of the test suite.
Conclusion and Future Work
In this paper, we present AGONETEST, a comprehensive framework for automating the generation and assessment of unit test suites using LLMs. The results of our experiments demonstrate that AGONETEST can produce and evaluate unit tests across various real-world projects, offering detailed insights into the performance of different LLMs and prompting techniques.
Future work should focus on systematic research into the most effective LLMs and prompts, coupled with continuous improvements in automated correction mechanisms for recurrent issues.