Authors:
Musa Taib、Jiajun Wu、Steve Drew、Geoffrey G. Messier
Paper:
https://arxiv.org/abs/2408.07845
Introduction
The Housing and Homelessness System of Care (HHSC) aims to connect individuals experiencing homelessness with supportive housing. This system comprises various agencies, each with different information technology platforms, leading to isolated data silos. Larger agencies can train and test artificial intelligence (AI) tools due to their extensive data, but smaller agencies often lack this capability. This paper introduces a Federated Learning (FL) approach to enable all agencies to collaboratively train a predictive model without sharing sensitive data, thereby ensuring equitable access to quality AI tools while preserving privacy.
Background
Emergency housing shelters in North America were initially designed for short-term stays but now often serve individuals for extended periods due to various challenges. The Housing First philosophy emphasizes quickly connecting individuals to supportive housing to improve their chances of exiting the shelter system. However, matching shelter users to supportive housing is complex due to the limited availability of supportive housing spaces and the need to prioritize chronic and episodic shelter users.
Machine learning (ML) can rapidly identify first-time shelter users at risk of becoming chronic or episodic users, using only the initial months of shelter records. The goal is not to automate housing decisions but to assist human staff in identifying at-risk individuals who might be overlooked by other programs.
Challenges in Equitable Access to ML
HHSCs consist of numerous agencies, each maintaining its own administrative database. Predicting homelessness risk is most accurate when training on data capturing interactions across all agencies. However, merging datasets is challenging due to privacy concerns, incompatible IT systems, and the absence of unique identity numbers for individuals across agencies. Smaller agencies, with limited data, struggle to train effective ML models, creating an equity issue in access to high-quality ML tools.
Federated Learning Approach
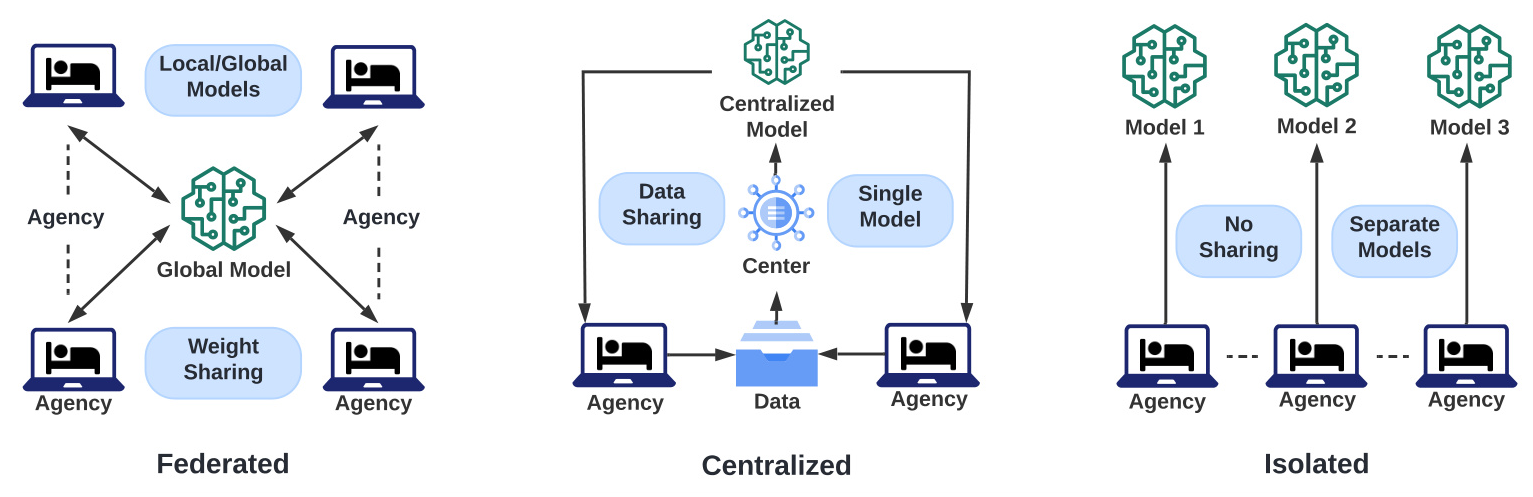
The proposed solution is a Federated Learning (FL) approach that utilizes disconnected datasets while respecting privacy. This method involves horizontal partitioning, where each agency’s dataset defines a partition. The model is trained using shelter stay data, ensuring generalizability and equity across HHSCs.
Labeling Process
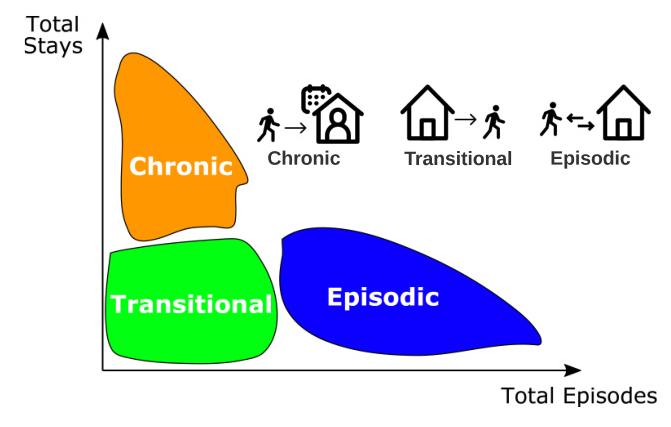
The labeling process uses historical shelter access records to determine the number of stays and episodes for each individual. A k-means clustering algorithm assigns labels (transitional, chronic, episodic) based on these values. The FL approach uses a decentralized k-means algorithm to pool data without merging records, preserving privacy.
Methodology
Problem Formulation
The task is formulated as a multi-class prediction problem, where the goal is to train a classifier to predict whether an individual will become a chronic, episodic, or transitional shelter user based on their shelter stay patterns.
Training Details
Three scenarios are considered:
1. Centralized: All data is merged centrally, and the model is trained on this dataset.
2. Federated: Agencies collaboratively train a single model using FL, avoiding data merging.
3. Isolated: Each agency trains its own model independently.
The FL framework follows the FedAvg algorithm, involving decentralized labeling, local model training, and aggregation of local models into a global model.
Evaluation
Experimental Setup
Experiments were conducted using anonymized shelter data from the Calgary Homeless Foundation, covering 6,840,069 sleep records for 50,455 individuals across 8 shelters. The dataset was preprocessed to create features based on shelter stay patterns and labeled using the decentralized k-means algorithm.
Hyperparameter Selection
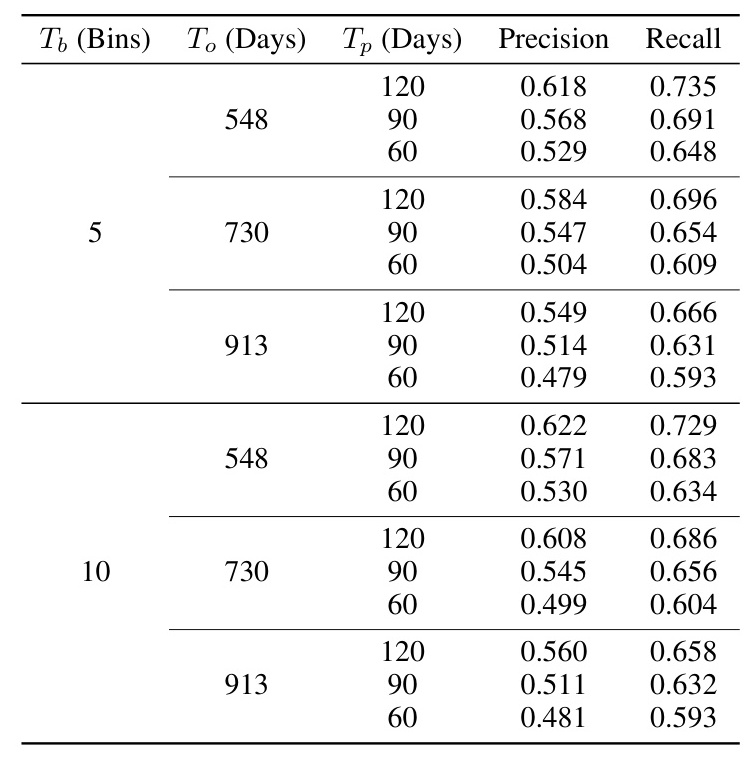
Key hyperparameters include the observation window (To), the number of time bins (Tb), and the prediction window (Tp). The best performance was achieved with larger To and Tb values and a smaller Tp value.
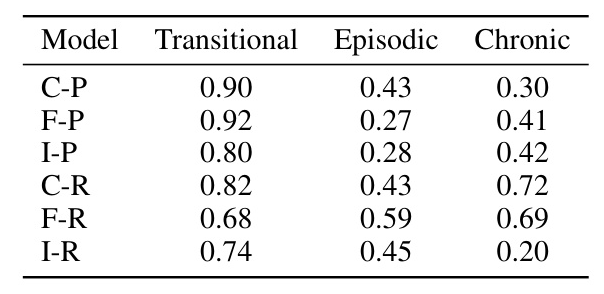
Performance Comparison
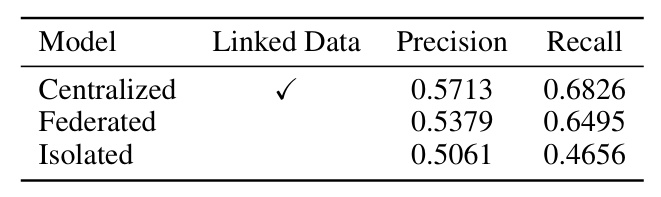
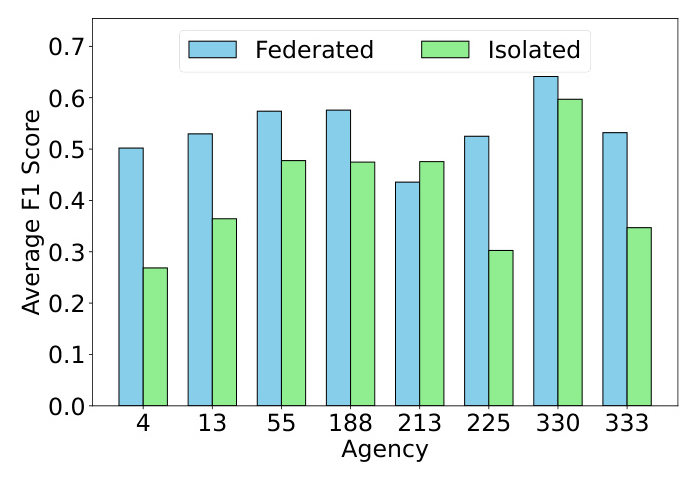
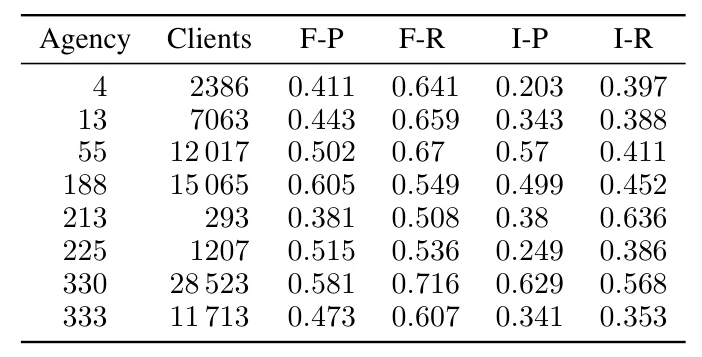
The Centralized scenario achieved the best performance, but the Federated model performed nearly as well, demonstrating the feasibility of FL in this context. The Isolated scenario performed the worst, particularly for smaller agencies with limited data.
Discussion
Centralized vs. Federated
While the Centralized model outperforms others, it is often impractical due to privacy and logistical challenges. The Federated approach offers a viable compromise, providing good performance without requiring centralized data merging.
Achieving Equity with Federated Learning
FL addresses the disparity in data analytics capabilities between large and small agencies. Smaller agencies benefit significantly from the aggregated insights available through FL, ensuring equitable access to high-quality ML tools.
Reducing the Need for Data Linkage
FL eliminates the need for direct data linkage, reducing privacy concerns and logistical complexities. This approach allows agencies to collaborate on model training without sharing sensitive information.
Conclusion
This study demonstrates the potential of Federated Learning to enhance equitable access to AI tools in the HHSC. By enabling collaborative model training without data sharing, FL addresses privacy concerns and logistical challenges, promoting equity across the system. Future research can build on this framework to develop more robust ML applications in social services.