Authors:
Xin Hao、Bahareh Nakisa、Mohmmad Naim Rastgoo、Richard Dazeley
Paper:
https://arxiv.org/abs/2408.07877
Introduction
In human-AI coordination scenarios, human agents often exhibit behaviors that are sparse and unpredictable compared to AI agents. This introduces challenges in obtaining sparse rewards and training AI agents efficiently. To address these challenges, the Intrinsic Reward-enhanced Context-aware (IReCa) reinforcement learning (RL) algorithm is proposed. IReCa leverages intrinsic rewards to facilitate the acquisition of sparse rewards and utilizes environmental context to enhance training efficiency. The algorithm introduces three unique features:
1. Encourages exploration of sparse rewards by incorporating intrinsic rewards.
2. Improves acquisition of sparse rewards by prioritizing corresponding sparse state-action pairs.
3. Enhances training efficiency by optimizing exploration and exploitation through context-aware weights.
Human-AI Coordination Scenario
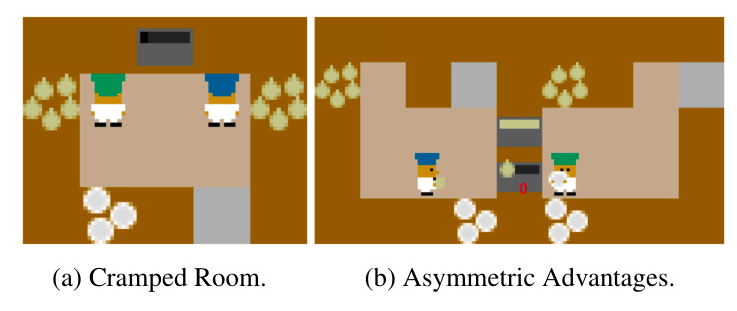
The primary objective in human-AI coordination is to achieve a shared goal through seamless collaboration between AI agents and human coordinators. The Overcooked environment is used as a benchmark for studying coordination dynamics. Two layouts are used:
1. Cramped Room: Poses low-level coordination challenges due to confined space leading to agent collisions.
2. Asymmetric Advantages: Requires high-level strategic planning as agents start in distinct areas with multiple cooking stations.
IReCa Reinforcement Learning
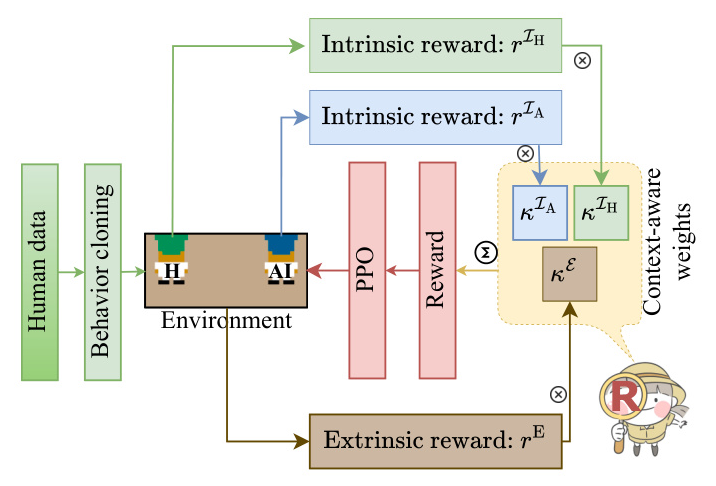
IReCa Overview
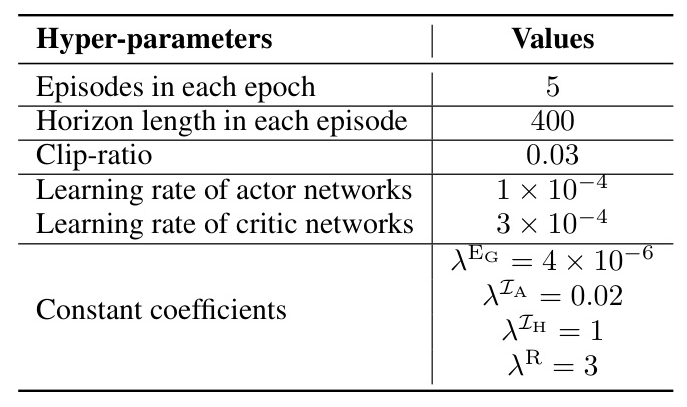
The IReCa RL algorithm integrates extrinsic rewards, intrinsic rewards, and context-aware weights. The AI agent is trained using proximal policy optimization (PPO) and a pre-trained human model. The IReCa reward is given by:
[ rA_t = \kappaE_n rE_t + \kappaIA_n rIA_t + \kappaIH_n rIH_t ]
where ( rE_t ) is the extrinsic reward, ( rIA_t ) and ( rIH_t ) are intrinsic rewards, and ( \kappaE_n ), ( \kappaIA_n ), and ( \kappaIH_n ) are context-aware weights.
Key Definitions
To ensure clarity, six key terms are defined:
1. Horizon: Sequence of future timesteps considered when planning policy.
2. Episode: Sequence of states, actions, and rewards concluding at a terminal state.
3. Epoch: Predefined number of timesteps used for training the model.
4. Reward: Instantaneous objective in an RL problem.
5. Episode Return: Undiscounted sum of all rewards during an episode.
6. Long-term Return: Infinite-horizon discounted return.
Detailed Design
Extrinsic Reward
In complex scenarios with sparse rewards, intermediate-stage rewards guide exploration and exploitation of key actions leading to target sparse rewards. The extrinsic reward is composed of target sparse reward ( rES_t ) and a linearly fading stage reward ( rEG_t ):
[ rE_t = rES_t + \max { 0, 1 – \lambdaEG \cdot t } rEG_t ]
Intrinsic Reward
Intrinsic rewards enhance exploration capabilities. The intrinsic reward consists of two components:
1. Self-motivated: Encourages the AI agent to adopt a diverse policy.
2. Human Coordinator-motivated: Optimizes the AI agent’s policy to be more adaptable to human actions.
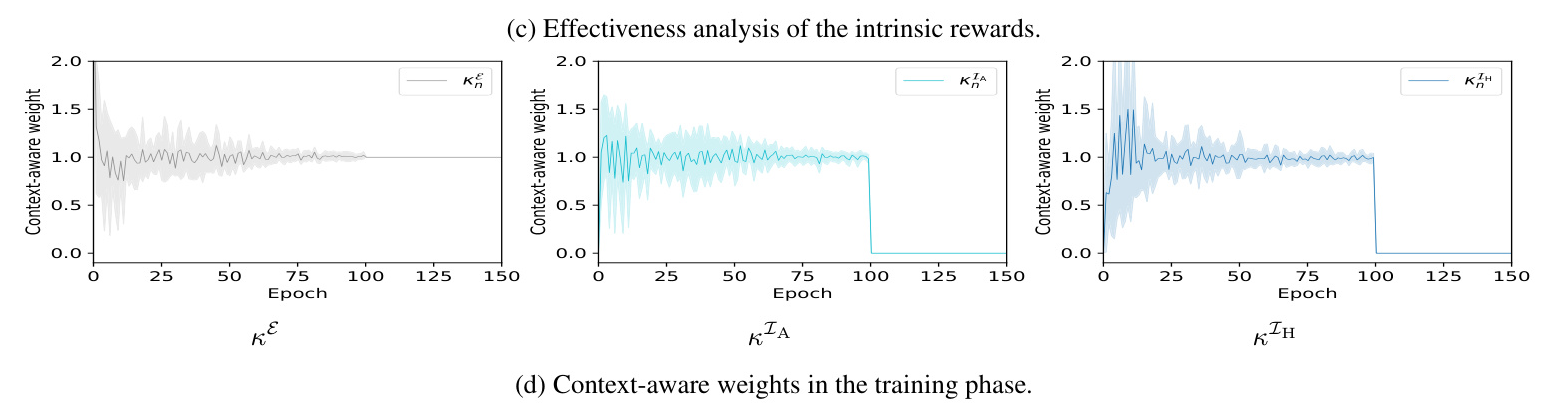
Context-aware Weights
Context-aware weights dynamically balance exploration and exploitation based on the evolving context. They are updated at each epoch and computed using the Softmax function:
[ \hat{\kappaE_n}, \hat{\kappaIA_n}, \hat{\kappaIH_n} = \lambdaR \cdot \text{softmax} \left( \frac{\bar{RE_{n-1}}}{\bar{RE_n}}, \frac{\bar{RIA_{n-1}}}{\bar{RIA_n}}, \frac{\bar{RIH_{n-1}}}{\bar{RIH_n}} \right) ]
Experiments
Environment
Experiments are conducted in the Overcooked environment where a human agent and an AI agent prepare onion soups. The goal is to serve the soup, earning a sparse reward of 20 points. The sequence of actions corresponds to stage rewards.
Agent Policies
The human agent’s behavior is modeled using behavior cloning policy. The AI agent’s policy is developed using the RL algorithm. The state space corresponds to the Overcooked grid world, and the action space includes six discrete actions.
Results and Analysis
Cramped Room
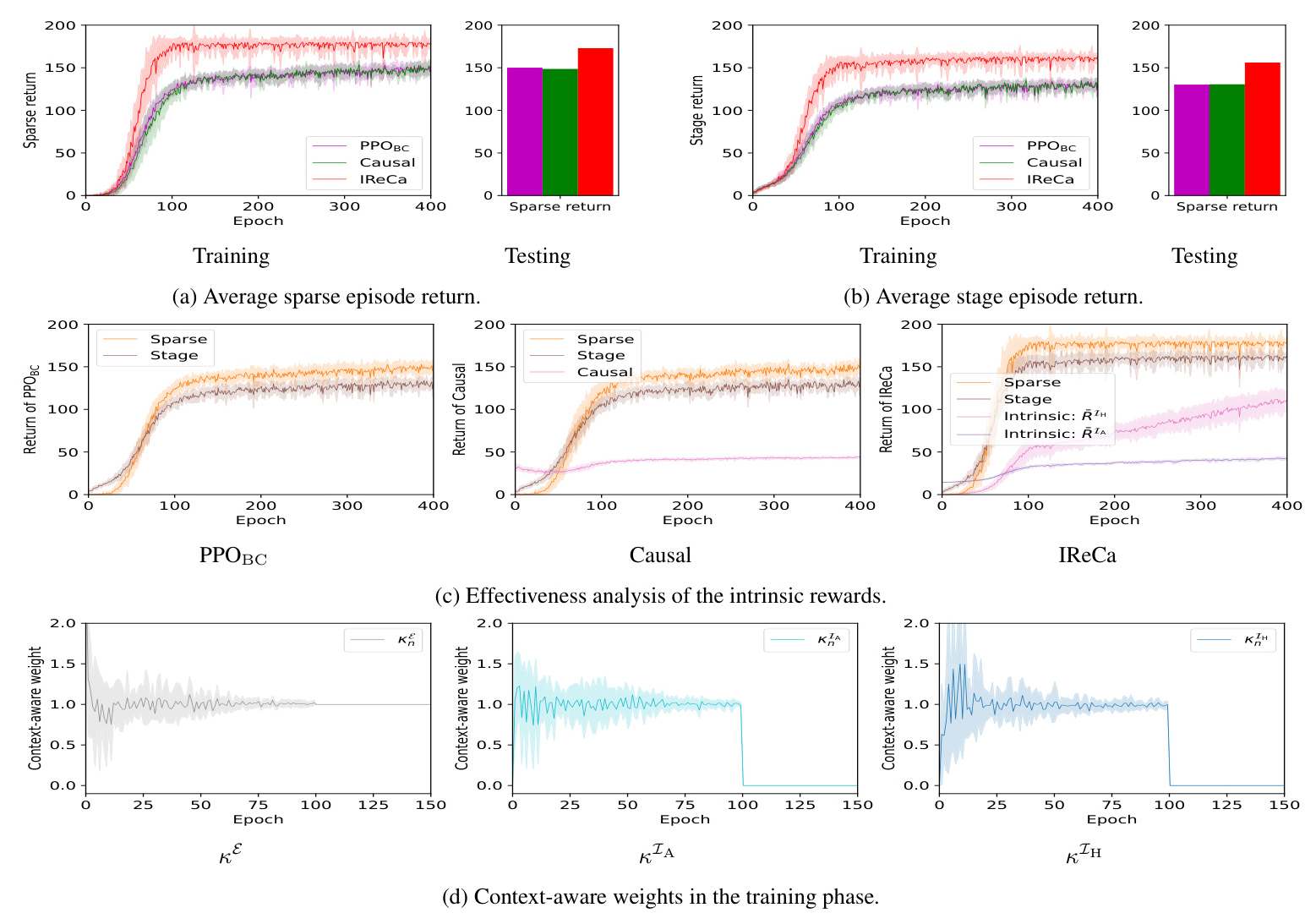
In the Cramped Room layout, IReCa achieves approximately 20% higher average sparse episode returns compared to baseline methods. The intrinsic rewards help the AI agent avoid local optima and achieve better performance. Context-aware weights assign higher values to intrinsic rewards in the initial epochs, leading to better sparse rewards.
Asymmetric Advantages
In the Asymmetric Advantages layout, IReCa consistently outperforms baseline algorithms in sparse, stage, and intrinsic episode returns. The context-aware weights prioritize updates to extrinsic rewards, optimizing the AI agent’s exploration. IReCa reduces the training epochs required for convergence by approximately 67%.
Conclusion
The IReCa RL algorithm enhances human-AI coordination by incorporating intrinsic rewards for comprehensive exploration and context-aware weights for optimizing exploration and exploitation. Experimental results demonstrate that IReCa increases episode returns by approximately 20% and reduces the number of epochs required for convergence by approximately 67%. These findings highlight IReCa’s potential applicability in real-world domains requiring critical human-AI coordination.