

Authors:
Tao Zheng、Liejun Wang、Yinfeng Yu
Paper:
https://arxiv.org/abs/2408.06911
Introduction
Speech communication is a fundamental mode of human interaction, but environmental noise often degrades the quality and clarity of speech data. Speech enhancement (SE) technology aims to mitigate the impact of noise while preserving the integrity of the original signal. This paper introduces a novel speech enhancement framework, HFSDA, which integrates heterogeneous spatial features and incorporates a dual-dimension attention mechanism to significantly enhance speech clarity and quality in noisy environments.
Related Work
Self-Supervised Learning Models
Self-supervised learning (SSL) models have shown significant progress in speech tasks. Early methods like Contrastive Predictive Coding (CPC) and Autoregressive Predictive Coding (APC) introduced unsupervised learning to audio pre-training. The wav2vec series further enhanced automatic speech recognition (ASR) performance. HuBERT and WavLM improved the performance and generalization ability of audio ASR. Applying SSL models to downstream tasks, including speech emotion recognition (SER) and SE, has demonstrated performance improvements.
Conformer
The Conformer model combines the strengths of CNN and Transformer architectures to enhance model performance by capturing both global and local information. This model has been effectively used in speech enhancement tasks, leveraging multi-head self-attention mechanisms and convolutional encoder-decoder frameworks.
Method
Overall Architecture
The proposed model architecture is depicted in Fig. 1. Speech data is processed using two branches: one transforms the speech waveform into a spectrogram via STFT and applies ODConv technology, while the other extracts high-level semantic information using a self-supervised model. These features are merged and fed into a Dual-Dimension Attention (DDA) module, which extracts features across both time and frequency dimensions. The model employs an L1 smooth loss function for optimization.
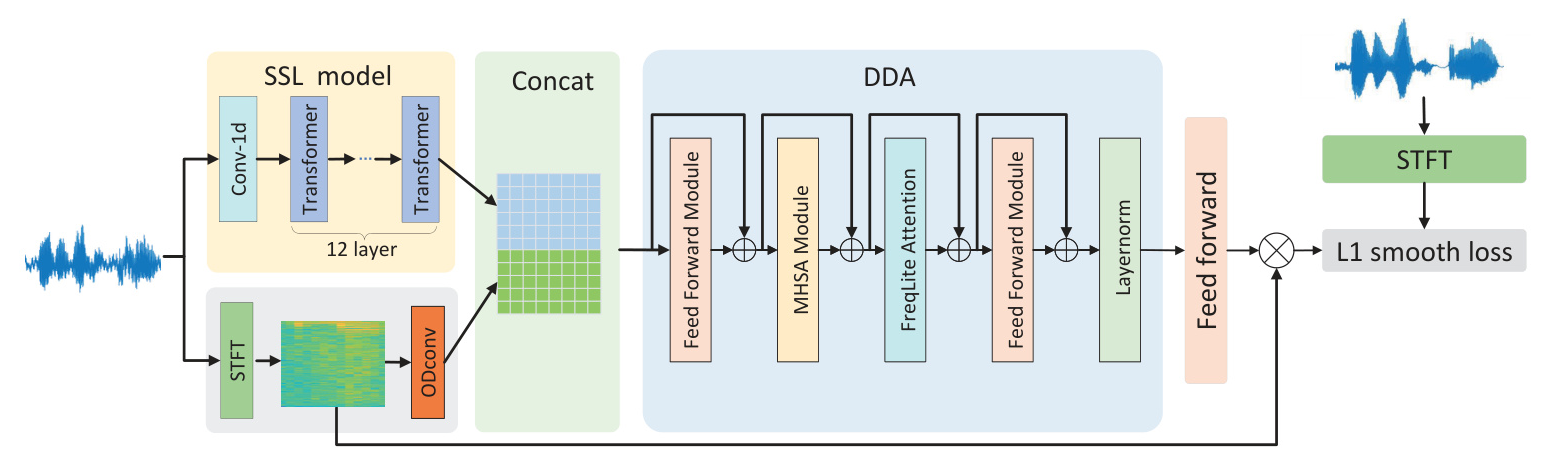
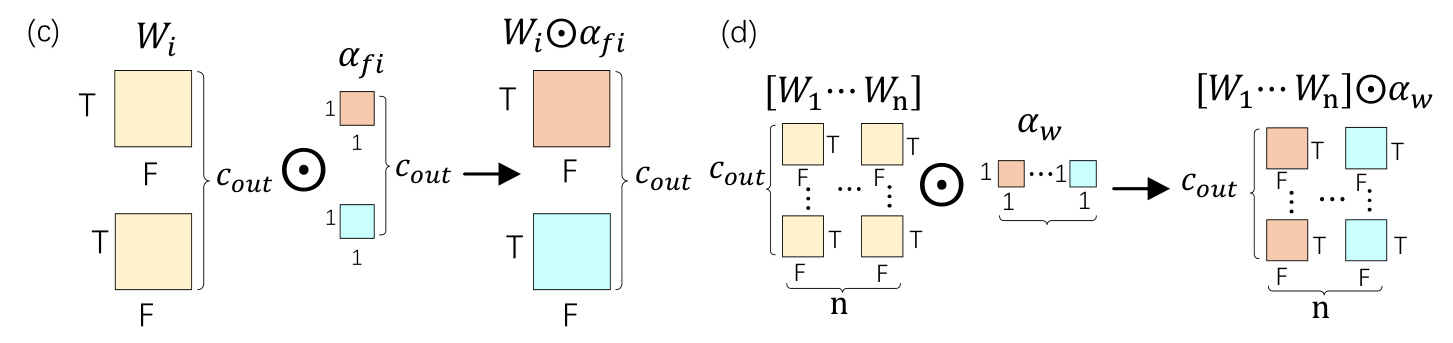
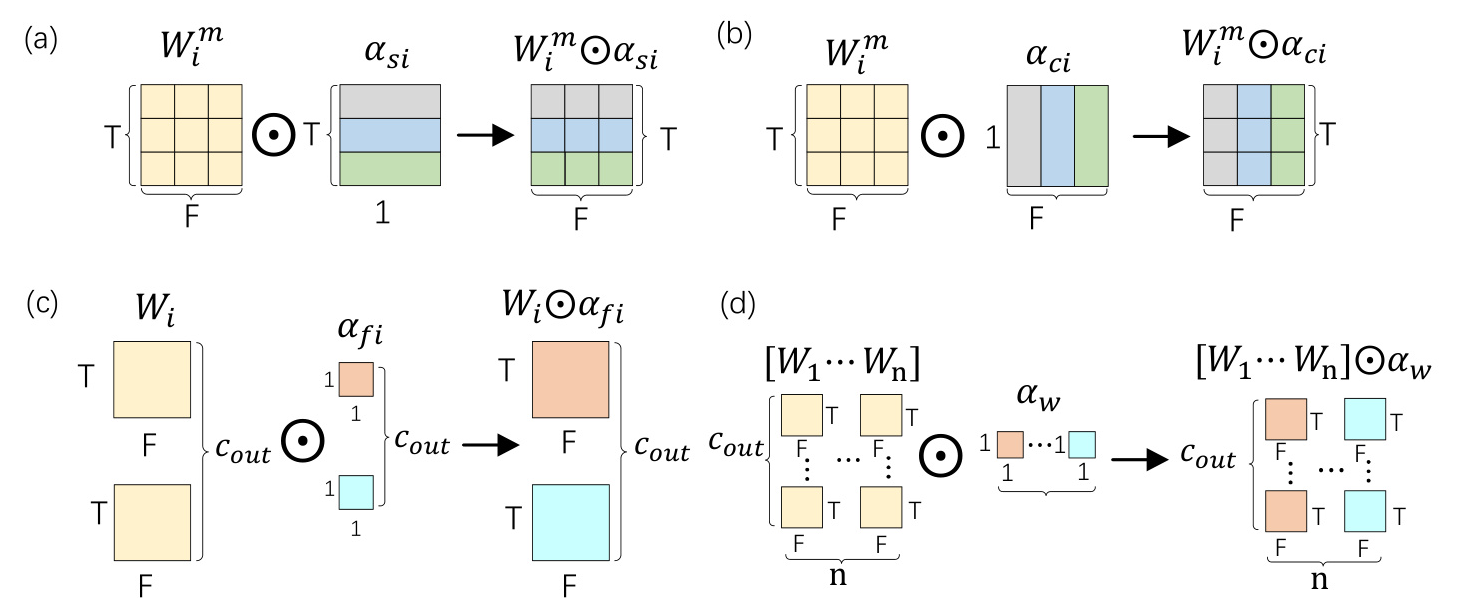
ODConv Module
The ODConv mechanism dynamically adjusts convolution kernel weights in response to input data, enhancing feature extraction capabilities. This mechanism applies attention weights sequentially across time, frequency, output channel, and convolution kernel dimensions, as illustrated in Fig. 2.
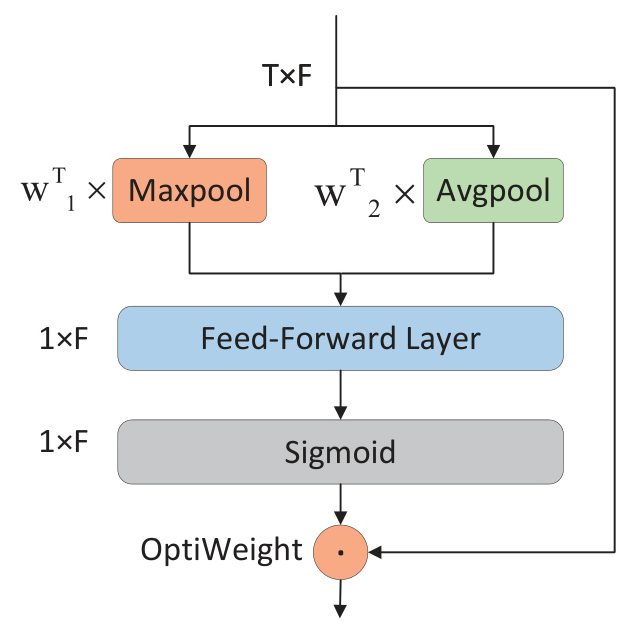
DDA Module
The DDA module integrates multi-head self-attention (MHSA) along the temporal dimension and FreqLite Attention (FA) along the frequency dimension, enabling dual-dimension attention. The FA module, depicted in Fig. 3, focuses on frequency dimension information, enhancing the model’s sensitivity to frequency details and improving computational efficiency.
Experimental Setup
Dataset and Assessment Indicators
The VCTK-DEMAND dataset, comprising mixed noise and clean speech, was used to evaluate the model’s denoising performance. The evaluation metrics included Perceptual Evaluation of Speech Quality (PESQ), CSIG, CBAK, COVL, and the Short-Time Objective Intelligibility (STOI) measure.
Experimental Setup
During preprocessing, speech from the training set was segmented into 1.5-second slices, while test set speech was kept at its original length. Spectral feature extraction employed a 25-millisecond window length with a 400-point FFT and a 10-millisecond step size. The model utilized two DDA blocks, with a batch size of 16 and the Adam optimizer for training over 200 epochs.
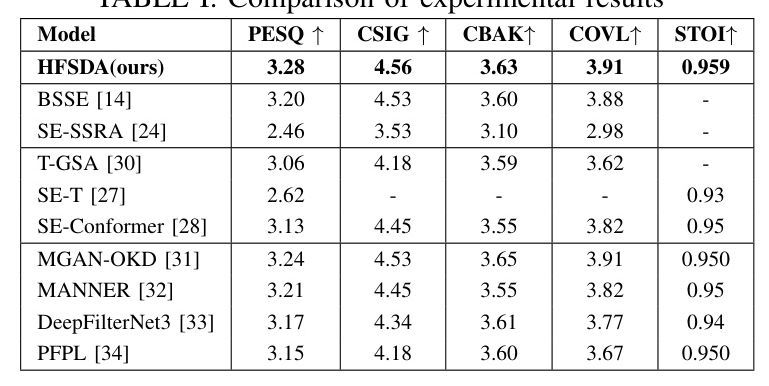
Performance Comparison
The proposed model was compared with advanced enhancement models and those employing Transformer and Conformer architectures. The results, presented in Table I, show that the HFSDA model outperforms all reference baselines in terms of performance.
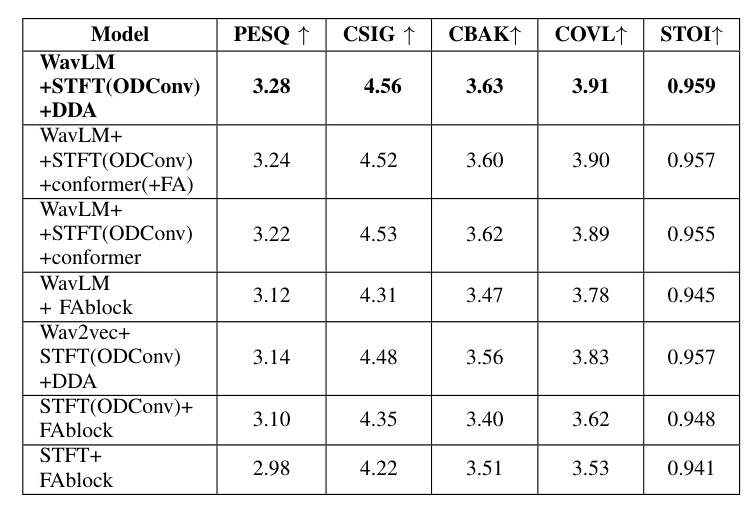
Ablation Analysis
Ablation studies, as shown in Table II, were conducted to validate the functional significance of the constituent modules. The results indicate the superior suitability of the lightweight FreqLite Attention module and the substantial influence of heterogeneous space fusion features on model performance.
Conclusions
The HFSDA model effectively addresses the complexities of noisy communication environments by integrating heterogeneous spatial features and a dual-dimension attention mechanism. This approach significantly enhances speech clarity and quality, as demonstrated by extensive evaluations on the VCTK-DEMAND dataset. The research paves the way for novel approaches to spatial feature fusion in speech enhancement.
This blog post provides a detailed interpretation of the paper “Heterogeneous Space Fusion and Dual-Dimension Attention: A New Paradigm for Speech Enhancement,” explaining the novel framework and its components, experimental setup, and results. The illustrations included in the paper are referenced to enhance understanding.