

Authors:
Lukas Strack、Mahmoud Safari、Frank Hutter
Paper:
https://arxiv.org/abs/2408.06820
Introduction
Activation functions are a critical component of deep neural networks, influencing both training dynamics and final performance. While the Rectified Linear Unit (ReLU) is widely used due to its simplicity and effectiveness, other activation functions have been proposed to address specific issues like the dying ReLU problem. However, manually designing optimal activation functions for specific tasks remains challenging. This paper leverages recent advancements in gradient-based search techniques to efficiently identify high-performing activation functions tailored to specific applications.
Related Work
Previous research has explored automated activation function design using gradient descent and black-box optimization methods. These approaches often require extensive computational resources, making them impractical for large-scale applications. This paper builds on the concept of Neural Architecture Search (NAS) and adapts gradient-based one-shot methods to search for activation functions by combining primitive mathematical operations.
Methodology
The Search Space for Activation Functions
The search space is defined as a combination of unary and binary operations, forming a scalar function ( f ). The unary and binary functions are chosen from a set of primitive mathematical operations, including existing activation functions to enrich the search space. The computational graph is continuously relaxed by assigning weighted sums of all unary and binary operations to the edges and vertices of the graph.

Tools from Gradient-Based Neural Architecture Search
The methodology builds on well-established gradient-based NAS methods like DARTS and DrNAS. These methods use bi-level optimization to update model weights and architecture parameters iteratively. The paper adapts these techniques to the space of activation functions, introducing modifications to robustify the approach.
Gradient-Based Activation Function Search
Several techniques are introduced to make gradient-based optimization work for activation function spaces:
- Warmstarting the Search: A short warm-starting phase initializes the search with reasonable settings for both network weights and activation function parameters.
- Constraining Unbounded Operations: Regularizing the search space by constraining unbounded operations to prevent divergence.
- Progressive Shrinking: Tracking activation parameters and progressively dropping operations with the lowest parameters to improve efficacy and expedite the search process.
- DrNAS with Variance Reduction Sampling: Drawing independent samples for each activation cell within the network to reduce variance introduced by the sampling process.
Experiments
Overview
The experiments explore high-performing activation functions across three distinct families of neural architectures: ResNet, Vision Transformers (ViT), and Generative Pre-trained Transformers (GPT). The search process is repeated with different seeds to ensure reliability, and the identified activation functions are evaluated on the networks/datasets they were searched on and transferred to larger models and new datasets.
ResNet
The objective is to enhance the performance of ResNet20 trained on CIFAR10 by improving its activation functions. The search identified five distinct activation functions, which were then evaluated and compared with existing baseline activation functions.
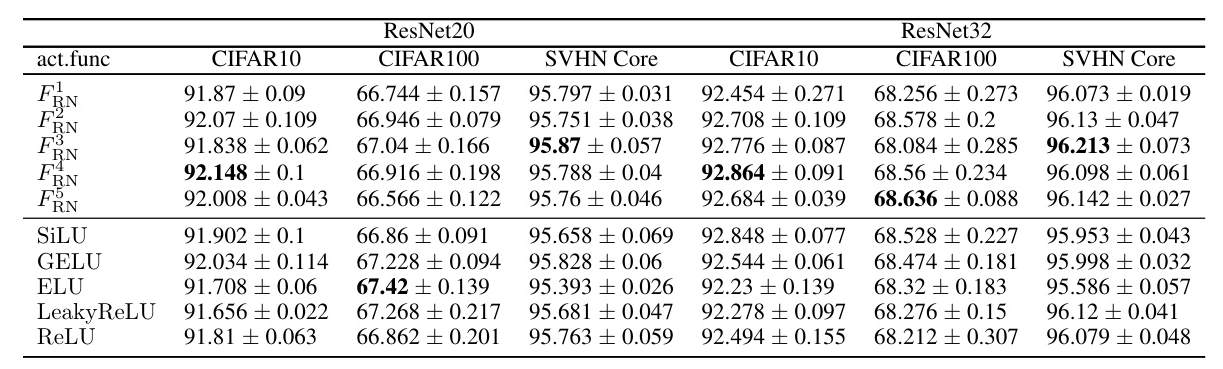
The results show that the newly discovered activations outperform the default ReLU activation and demonstrate strong transferability to larger models and new datasets.

Vision Transformers
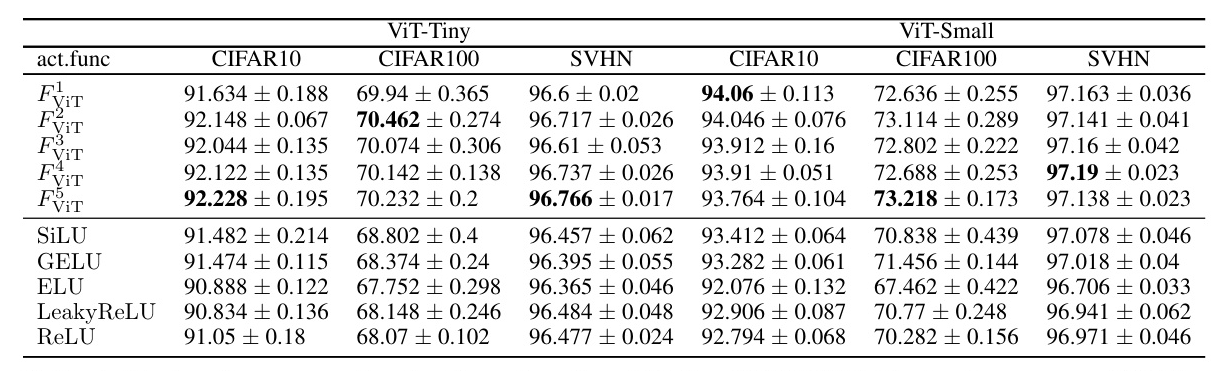
The search was conducted on the ViT-Ti model, a light version of ViT, to avoid computational burden. Five novel activations were identified and evaluated on ViT-tiny and ViT-small models across CIFAR10, CIFAR100, and SVHN Core datasets.
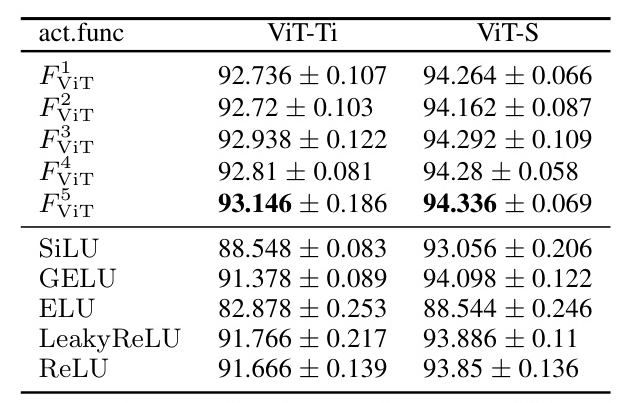
The results indicate that all five activations outperform existing baselines, providing high-performing customized activations for the ViT architecture.
Generative Pre-Trained Transformers
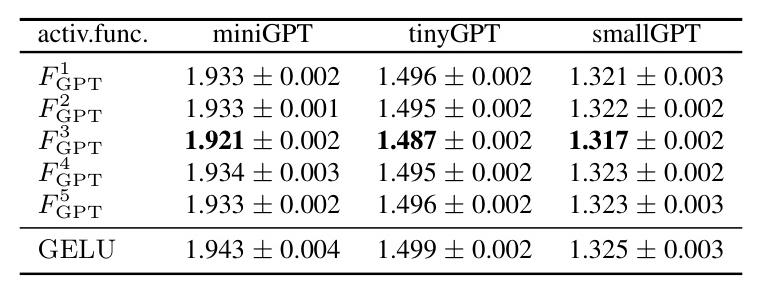
The evaluation was extended to language modeling tasks using a down-scaled version of GPT-2, referred to as miniGPT. Five new activations were identified and evaluated on miniGPT, tinyGPT, and smallGPT models.
The results show that all discovered activations outperform the default GELU activation, with strong transferability to larger models.
Conclusions
The paper demonstrates that modern gradient-based architecture search techniques can be adapted to explore the space of activation functions effectively. The proposed search strategy, combined with a well-designed search space, successfully identifies activation functions tailored to specific deep learning models, surpassing commonly-used alternatives. The optimization is highly efficient, requiring very low overhead, making it convenient for practitioners to employ these methods to design activation functions for their deep learning architectures.
Acknowledgements
This research was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under grant number 417962828. The authors acknowledge support by the state of Baden-Württemberg through bwHPC and the German Research Foundation (DFG) through grant INST 35/1597-1 FUGG. Frank Hutter is a Hector Endowed Fellow at the ELLIS Institute Tübingen.
Code:
https://github.com/automl/grafs