

Authors:
Hao Li、Fabian Deuser、Wenping Yina、Xuanshu Luo、Paul Walther、Gengchen Mai、Wei Huang、Martin Werner
Paper:
https://arxiv.org/abs/2408.06761
Introduction
The rapid advancement in Remote Sensing (RS) technology has significantly enhanced the availability of large-scale, high-quality Earth observation (EO) data, which is crucial for timely humanitarian responses to natural disasters. Street View Imagery (SVI) has also gained momentum in urban studies and computer vision, providing a unique ground-level perspective that complements traditional satellite imagery analysis. In disaster mapping scenarios, two types of information are critical: disaster damage perception and geolocation awareness. This paper introduces a novel disaster mapping framework, CVDisaster, which addresses both geolocalization and damage perception estimation using cross-view SVI and Very High-Resolution (VHR) satellite imagery. The framework is evaluated using a case study of Hurricane IAN, demonstrating its potential for timely and accurate disaster response.
Related Work
GeoAI for Disaster Mapping and Localization
Disaster mapping has been successfully used to support disaster response and humanitarian aid activities. Traditional disaster mapping workflows, however, are often inefficient for large-scale areas and timely damage assessment. High-resolution satellite imagery and GeoAI techniques offer promising solutions to these challenges. Previous works have focused on improving the speed and accuracy of disaster mappings and extracting accurate location information from social media text data. However, there is a need for an integrated framework that can achieve large-scale damage perception and cross-view geolocalization simultaneously.
Street-View Imagery for Urban Analytics
SVI has become a crucial data source for urban studies, applied across various fields such as urban morphology, traffic flow analysis, and public health. SVI provides detailed ground-level information, which is essential for disaster assessment and emergency response. Combining SVI with RS data can enhance the precision and efficiency of disaster response and support post-disaster recovery and reconstruction. However, research integrating SVI with RS data in disaster response scenarios is still limited.
Cross-View Geolocalization
Cross-view geolocalization enhances classic location-based services and navigation systems by matching ground-level imagery with overhead imagery. This technique is particularly useful in GNSS-denied environments, such as during a disaster. Previous works have introduced various datasets and methods for cross-view geolocalization, but none have specifically addressed disaster scenarios. The key to cross-view geolocalization is contrastive learning, which involves minimizing the distance between embeddings of similar images while maximizing the distance to dissimilar images.
Methodology
Task Statement
The objective is to learn a cross-view embedding space where two tasks are solved simultaneously: geolocalization of SVI based on their similarities with satellite imagery and estimation of damage perception levels from cross-view imagery pairs. The framework integrates two GeoAI models: CVDisaster-Geoloc for geolocalization and CVDisaster-Est for damage perception estimation.
Cross-View Geolocalization via Contrastive Learning
CVDisaster-Geoloc formulates the task of cross-view geolocalization as an imagery retrieval problem. A Siamese network with a ConvNeXt backbone is used as the image encoder. The network is pre-trained on large-scale datasets (CVUSA, CVACT, and VIGOR) using a contrastive learning objective and fine-tuned with new cross-view imagery from the case study area.
Siamese Image Encoder with ConvNeXt
ConvNeXt, a modernized Convolution Neural Network (CNN), is used as the image encoder. It retains the simplicity and effectiveness of classic CNNs while incorporating modern neural architecture designs for performance boosting. The Siamese network is trained on cross-view imagery pairs, and the inference can handle a single input of SVI as a query base.
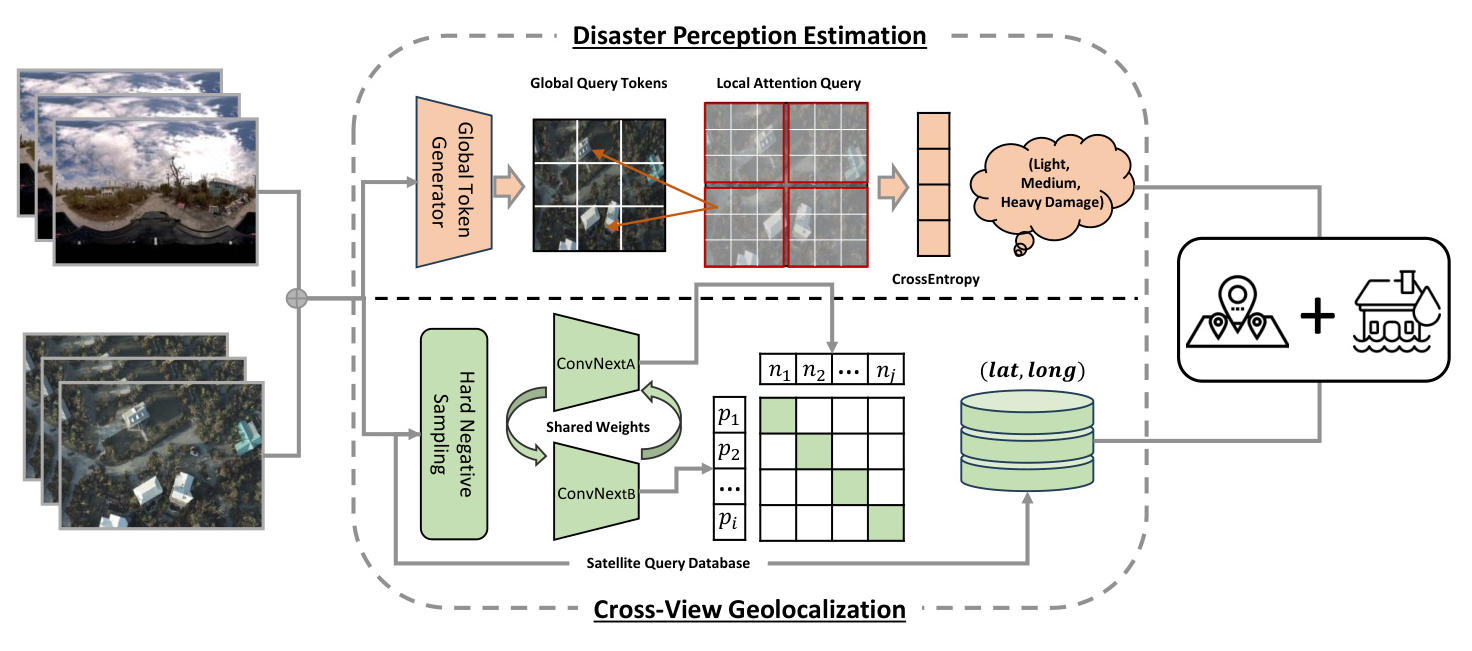
Contrastive Learning with Hard Negative Sampling
Contrastive learning involves minimizing the distance between embeddings of similar images while maximizing the distance to dissimilar images. The InfoNCE loss function is used for both pre-training and fine-tuning stages. The model is fine-tuned on the new cross-view imagery collected from the study area after Hurricane IAN.
Damage Perception Estimation with Cross-View Imagery
CVDisaster-Est tackles the task of damage perception estimation as a multi-class image classification problem. A coupled Global Context Vision Transformer (CGCViT) model is developed, consisting of two separate branches for SVI and satellite imagery. The CGCViT model benefits from complementary prediction capabilities learned from cross-view pairs.
Coupled Global Context Vision Transformer
The CGCViT model includes four stages of local and global self-attention modules, with global attention querying long-range perception fields. The global query token is pre-computed between each stage, allowing local self-attention to access long-range information without increasing computation complexity.
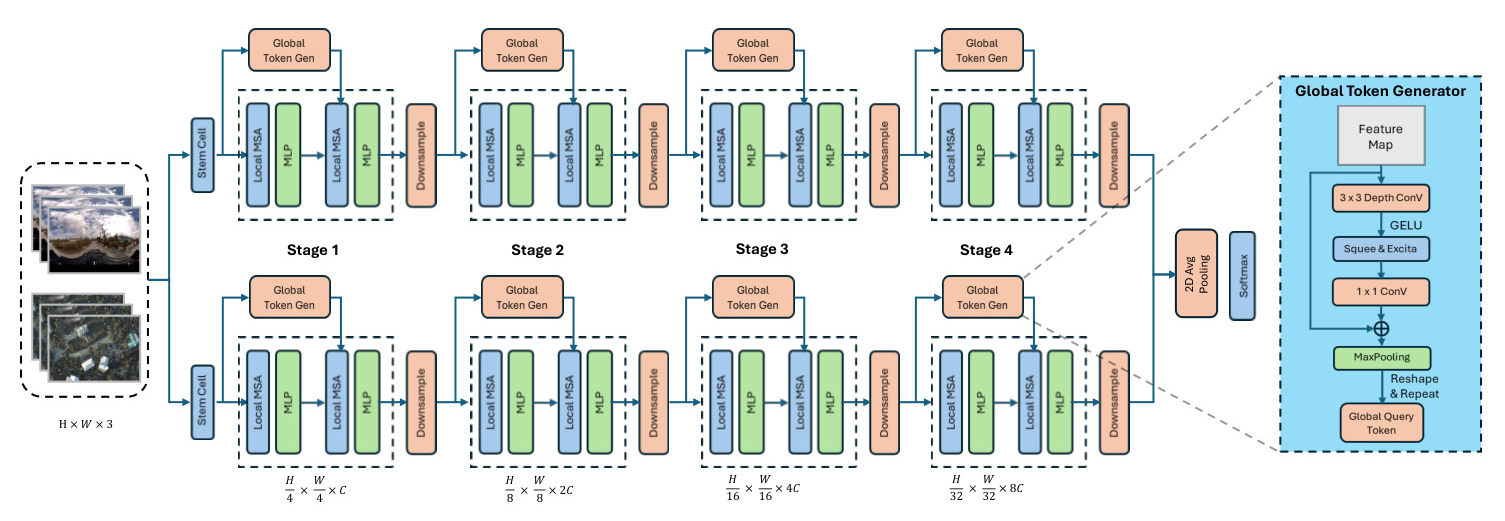
Experiment
Dataset Overview
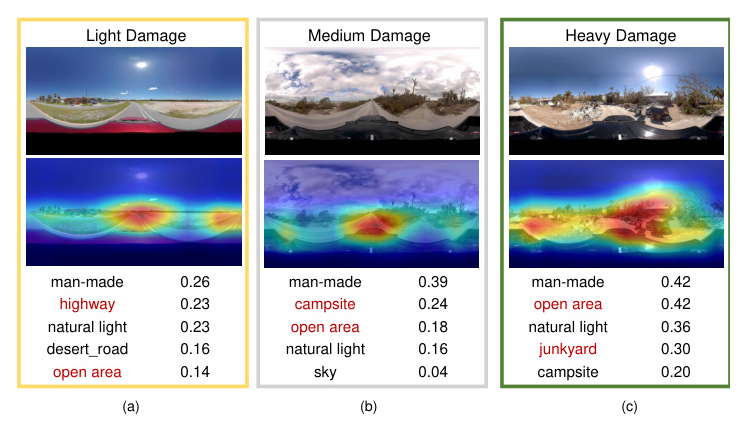
The CVIAN dataset, created for this study, includes VHR satellite imagery and SVI collected around Sanibel Island after Hurricane IAN. The dataset is split into five subareas, with SVI manually labeled for damage perception levels (light, medium, and heavy damages).
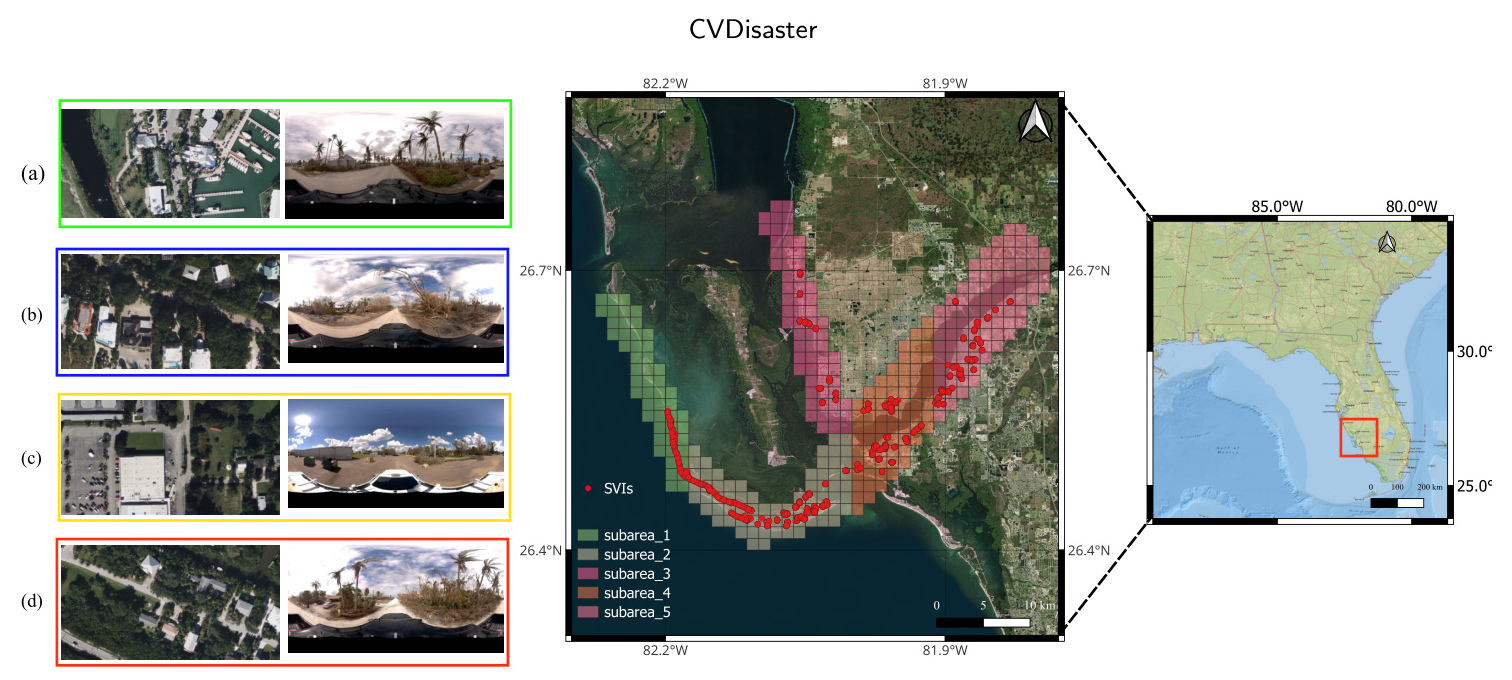
Experiment Setup for Cross-View Geolocalization
The ConvNeXt-Base model, pre-trained on CVUSA, is fine-tuned on the CVIAN dataset. Various data augmentation techniques are used to improve the model’s robustness. The CGCViT model is fine-tuned with the same cross-view imagery pairs for damage perception estimation.
Geo-Localization Results
The performance of pre-trained cross-view geolocalization models is compared with the fine-tuned CVDisaster-Geoloc model. The fine-tuned model achieves significant performance improvements, demonstrating the value of pre-trained models for timely disaster response.
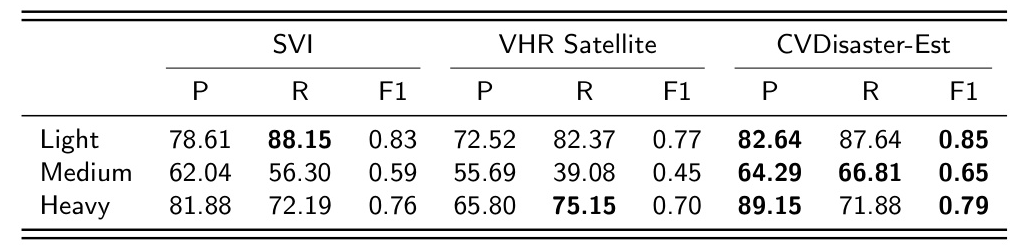
Disaster Mapping Results
The CVDisaster-Est model is compared with single-view models for damage perception estimation. The cross-view model outperforms single-view models, highlighting the advantages of using cross-view imagery for disaster perception estimation.
Discussions
The CVDisaster framework demonstrates promising results for cross-view geolocalization and disaster perception estimation. Future work should focus on automatically extracting and quantifying damage-related indicators from SVI and considering temporal changes during disaster scenarios. Extending the CVIAN dataset to cover multiple areas and disaster types will further validate the framework’s effectiveness.
Conclusions
CVDisaster is a novel framework that simultaneously achieves cross-view geolocalization and disaster damage perception estimation. The case study on Hurricane IAN confirms its advantages over traditional positioning techniques and damage assessment approaches. The framework’s competitive performance with limited fine-tuning efforts highlights its potential for timely and accurate disaster response.
Acknowledgements
The authors acknowledge the computing time granted by the Institute for Distributed Intelligent Systems and provided on the GPU cluster Monacum One at the University of the Bundeswehr Munich.
Disclosure Statement
No potential conflict of interest was reported by the authors.