

Authors:
Vladimir Cherkassky、Eng Hock Lee
Paper:
https://arxiv.org/abs/2408.06598
Introduction
In the paper titled “A Perspective on Large Language Models, Intelligent Machines, and Knowledge Acquisition,” Vladimir Cherkassky and Eng Hock Lee from the University of Minnesota delve into the capabilities and limitations of Large Language Models (LLMs) like GPT-4. They explore the philosophical context of human knowledge acquisition and the Turing test, and provide empirical evaluations of LLMs, particularly focusing on their understanding of abstract concepts and reasoning.
Intelligent Machines: A Philosophical Perspective
The Debate on AI Intelligence
Large Language Models (LLMs) such as GPT-4, Llama 2, and PaLM 2 are often seen as tools that mimic human intelligence. However, there is a contrasting view that LLMs lack true understanding and generate responses based on statistical correlations in data. This debate hinges on differing definitions of “intelligence” and “knowledge.”
The Turing Test and Its Limitations
The Turing test, proposed by Alan Turing, suggests that a machine’s ability to exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human can be tested through an “imitation game.” However, the paper argues that the Turing test is subjective and its results depend on the intelligence of the human interrogators. This leads to the concept of the Reverse Turing Test, where the quality of LLM responses mirrors the quality of human questions.
Philosophical Theories of Mind
The paper discusses dualism and materialism, two philosophical theories of mind. Dualism, dating back to Descartes, posits that the mind and body are distinct entities, implying that human intelligence cannot be replicated by a physical system like a computer. Materialism, on the other hand, views the mind as an emergent property of the physical brain, aligning with the functionalist perspective that intelligent behavior can be imitated by a computer.
Functionalism and Artificial General Intelligence (AGI)
Functionalism asserts that mental states are defined by their functional roles, which can be replicated by different physical systems. This view supports the idea of “strong AI,” where human mind is seen as software running on brain hardware. The paper also discusses computational functionalism and the potential of LLMs to achieve Artificial General Intelligence (AGI) within the next 5-10 years.
The Chinese Room Argument
John Searle’s Chinese Room thought experiment argues against strong AI by illustrating that computers manipulate symbols without understanding their meaning, unlike humans who understand the meaning behind symbols.
Observer-Independent vs. Observer-Relative Knowledge
The paper distinguishes between observer-independent knowledge (e.g., natural sciences) and observer-relative knowledge (e.g., social sciences). This distinction is crucial for understanding LLM capabilities, as most successful LLM applications generate observer-relative knowledge.
Empirical Evaluation of LLM Capabilities
Methodology
The paper evaluates LLM capabilities by focusing on understanding abstract concepts and reasoning, using GPT-4 as the test subject. The evaluation adopts an experimental design setting, presenting carefully designed questions that require understanding of abstract concepts in various areas.
Simple Math Questions
Rational and Irrational Numbers
GPT-4 was tested on two related questions about rational and irrational numbers. While it correctly answered one question, it provided an incorrect response to the other, indicating a lack of consistent understanding.
Inductive Inference for Integer Sequences
GPT-4 was tested on predicting sequences of numbers. It correctly answered one question but failed another, even though both questions had the same underlying concept, indicating a lack of understanding of prime numbers.
Scientific and Machine Learning Questions
Continuous Functions
GPT-4 was asked about the predictability of a continuous function’s value within a given range. It provided a wrong answer, indicating a lack of understanding of the concept of continuous functions.
Training and Test Error in Machine Learning
GPT-4 was asked whether training error can exceed test error in machine learning. It provided a verbose but incorrect explanation, indicating a lack of conceptual understanding.
Common Sense Questions
International Politics
GPT-4 was asked whether the US President can dislodge the leader of another country. Its response contained logical inconsistencies, indicating a lack of understanding.
Understanding Humor
GPT-4 was tested on its understanding of humor through a sarcastic question. Its response showed a lack of understanding of the sarcastic and nonsensical nature of the question.
Discussion: LLMs as a Tool for Knowledge Transfer
Historical Context of Knowledge Transfer
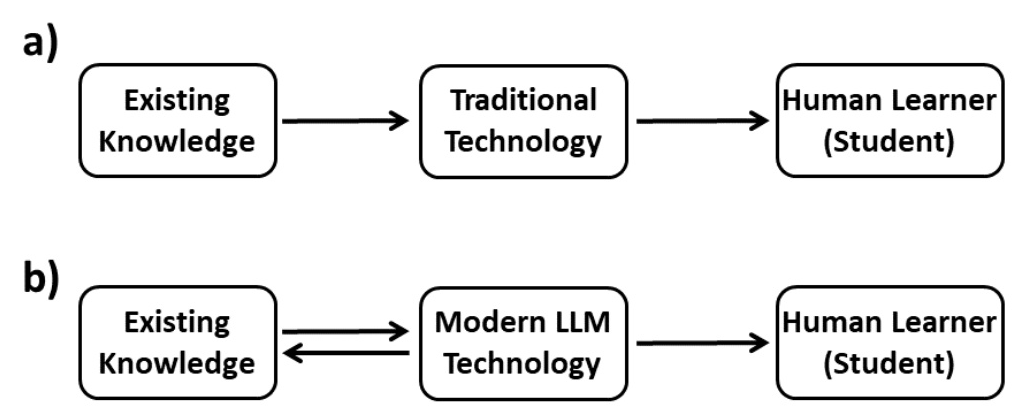
The paper discusses the evolution of knowledge transfer, highlighting the impact of digital technologies like the World Wide Web and LLMs. It argues that LLMs should be viewed as mechanisms for knowledge retrieval and transfer, rather than knowledge generation.
Impact on Education
The paper discusses the impact of LLMs on education, emphasizing the importance of understanding abstract concepts. It warns against using LLMs as shortcuts for memorization, which is critical for human learning.
Scientific Understanding of DL and LLMs
The paper critiques the current state of AI research, arguing that it is driven by engineering and beliefs rather than science. It calls for a solid scientific framework to understand the capabilities and limitations of DL and LLMs.
Conclusion
The paper concludes that while LLMs like GPT-4 can generate correct answers, they lack understanding of abstract concepts. It emphasizes the need for a well-defined notion of intelligence and knowledge to better understand LLM capabilities and their impact on human knowledge acquisition and education.
Illustrations
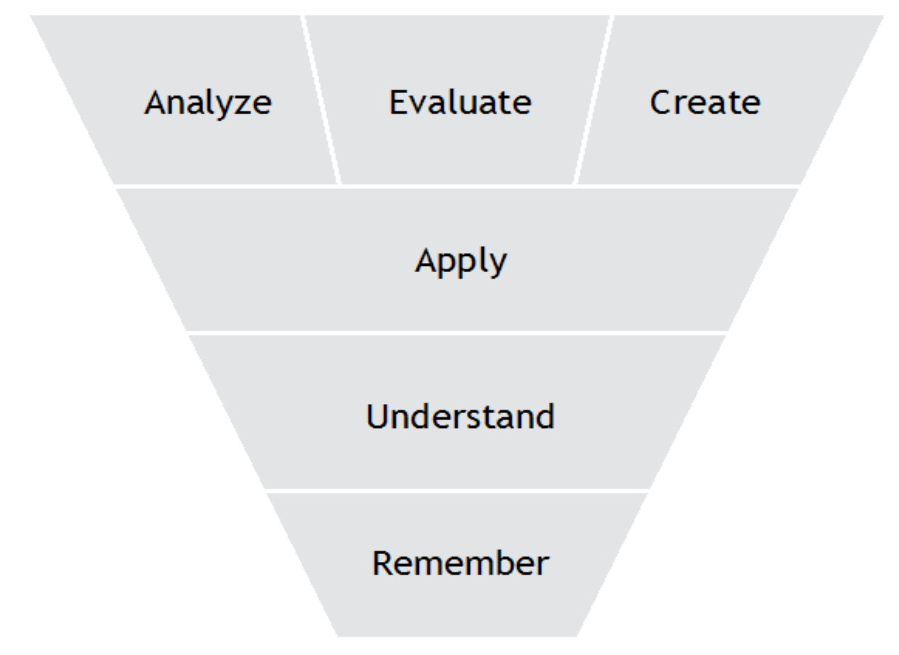
- Bloom’s Taxonomy: An inverted pyramid of learning levels, highlighting the hierarchical nature of human learning.
- Knowledge Transfer: Diagrams showing the effect of digital technology on human learning and knowledge transfer in pre-digital and digital worlds.
- Mathematical Example: An example illustrating the inconsistency in GPT-4’s understanding of rational and irrational numbers.
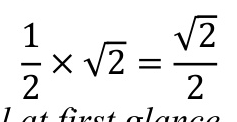
This detailed interpretive blog provides a comprehensive overview of the paper’s chapters, highlighting the key points and discussions presented by the authors.