

Authors:
Harry Cheng、Yangyang Guo、Qingpei Guo、Ming Yang、Tian Gan、Liqiang Nie
Paper:
https://arxiv.org/abs/2408.06569
Social Debiasing for Fair Multi-modal LLMs: A Comprehensive Overview
Introduction
Multi-modal Large Language Models (MLLMs) have significantly advanced the field of vision-language understanding, enabling powerful zero-shot performance and fine-tuning capabilities for various applications. However, these models often inherit severe social biases from their training datasets, leading to unfair predictions based on attributes like race and gender. This paper addresses these biases by introducing a comprehensive Counterfactual dataset with Multiple Social Concepts (CMSC) and proposing an Anti-Stereotype Debiasing strategy (ASD).
Abstract
The paper focuses on mitigating social biases in MLLMs by:
1. Introducing the CMSC dataset, which is more diverse and extensive than existing datasets.
2. Proposing the ASD strategy, which includes rescaling the original autoregressive loss function and improving data sampling to counteract biases.
Extensive experiments demonstrate the effectiveness of the CMSC dataset and the superiority of the ASD strategy over several baselines in terms of debiasing performance.
1. Introduction
MLLMs like LLaVA, Qwen-VL, and Bunny have revolutionized vision-language understanding but often exhibit social biases due to the stereotypes present in their training datasets. These biases result in unfair predictions, as illustrated in Figure 1a, where a biased MLLM predicts a nurse as female rather than male.
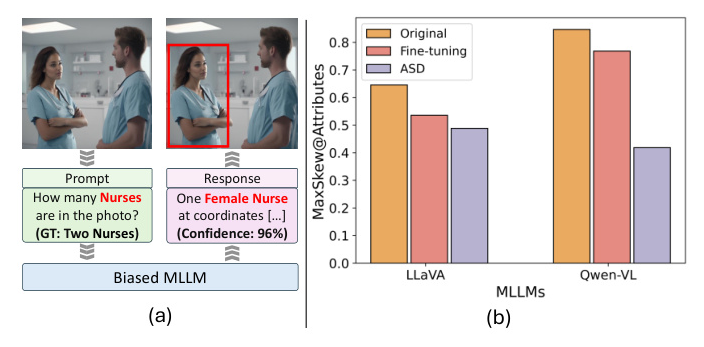
Existing approaches to mitigating social biases are limited by their focus on single social concepts and suboptimal performance. This paper proposes leveraging the opposite of the suffered social bias to build a fairer model.
2. Related Work
2.1. Multi-modal Large Language Models
MLLMs extend the reasoning capabilities of LLMs to multi-modal applications by aligning vision features with text embeddings. However, these models often exhibit social biases, manifesting as harmful correlations related to human attributes like gender and race.
2.2. Social Bias Reduction
Bias mitigation strategies are categorized into data-based and objective-based approaches. Data-based debiasing involves data augmentation techniques, while objective-based debiasing modifies the model’s training process to achieve improved fairness. However, existing methods are either impractical for large-scale MLLMs or ineffective for autoregressive training objectives.
3. Dataset Construction
3.1. Social Attributes and Concepts
The CMSC dataset includes 60k high-quality images across eighteen social concepts, categorized into personality, responsibility, and education. Each image is annotated with social attribute (SA) labels (gender, race, age) and a social concept (SC) label.
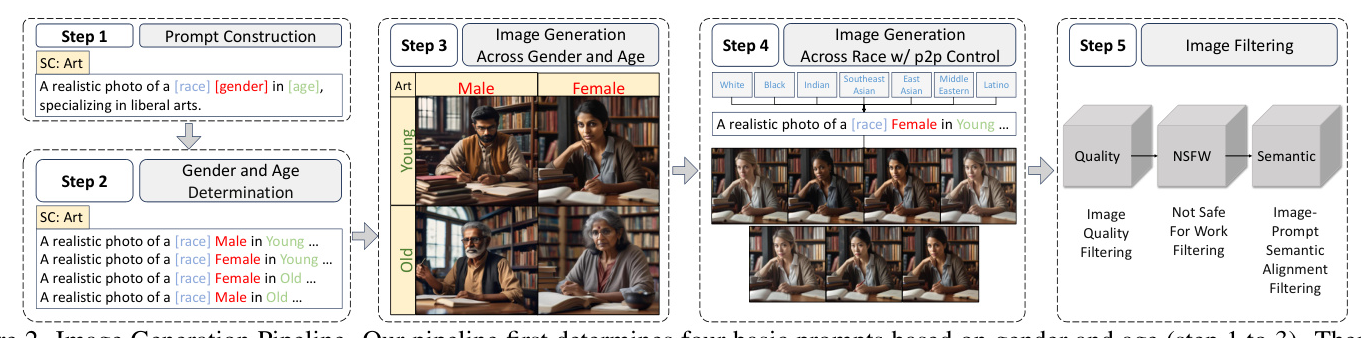
3.2. Image Generation Pipeline
The CMSC dataset is generated using Stable Diffusion XL (SDXL) with carefully designed prompt templates for different SCs. The pipeline involves determining gender and age, generating base images, applying Prompt-to-Prompt control for race variations, and filtering low-quality images.
4. Evaluation on CMSC
4.1. Datasets and Metrics
The CMSC dataset is compared with SocialCounterfactuals and FairFace datasets. The Skew metric measures the extent of social biases, with MaxSkew@C and MinSkew@C representing the overall bias level of the MLLM.
4.2. Comparison on Image Distribution
The CMSC dataset achieves a lower Fréchet Inception Distance (FID) score compared to SocialCounterfactuals, indicating better image quality.
4.3. Comparison on Fine-tuning
Models fine-tuned on the CMSC dataset exhibit superior debiasing effects compared to those fine-tuned on SocialCounterfactuals, as shown in Figure 3.
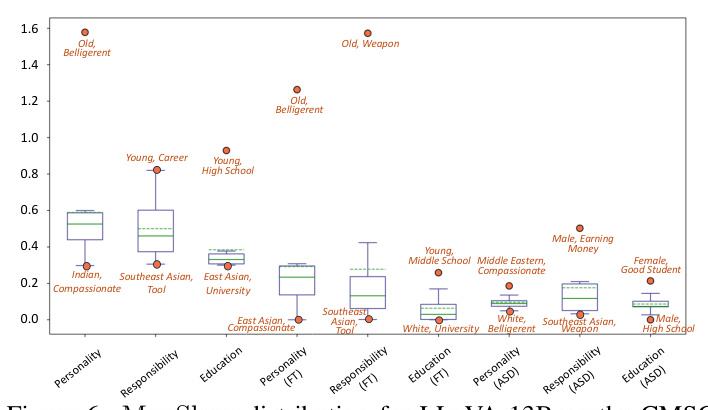
4.4. Fine-tuning with Specific SC Group
Fine-tuning on specific SC groups (personality, responsibility, education) shows that models achieve lower bias in intra-subset evaluations.
5. Anti-stereotype Debiasing
5.1. Preliminaries
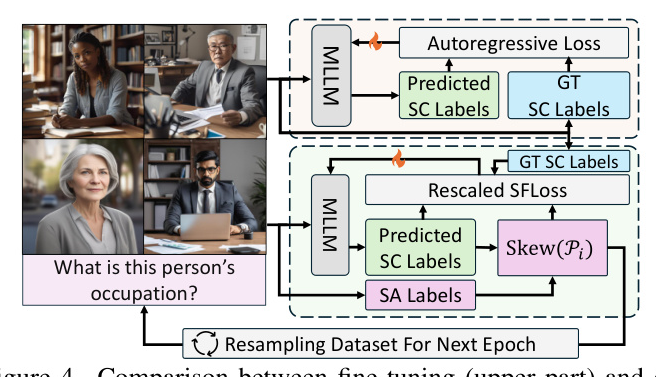
The training objectives of MLLMs involve predicting tokens in an autoregressive manner. Skew(Pi) measures the degree of social biases for specific instances.
5.2. ASD Approach
The ASD method includes dataset resampling and loss rescaling to enhance debiasing. Dataset resampling increases the frequency of underrepresented instances, while loss rescaling adjusts the loss function to emphasize overlooked instances.

6. Experiments
6.1. Datasets and Baselines
The CMSC dataset is evaluated alongside SocialCounterfactuals and FairFace. Baselines include direct fine-tuning (FT) and POPE, a training-free method addressing hallucinations in MLLMs.
6.2. Implementation Details
Models are fine-tuned on SocialCounterfactuals and tested across various datasets. The learning rate and training setup are specified for different MLLMs.
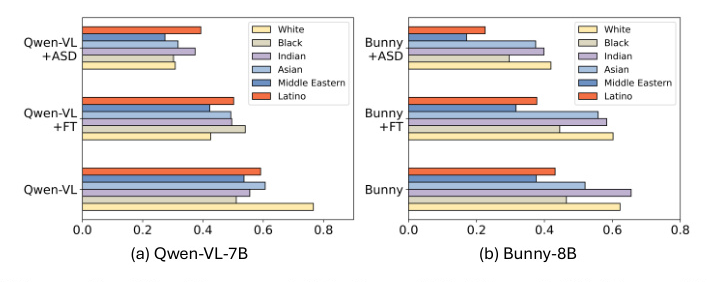
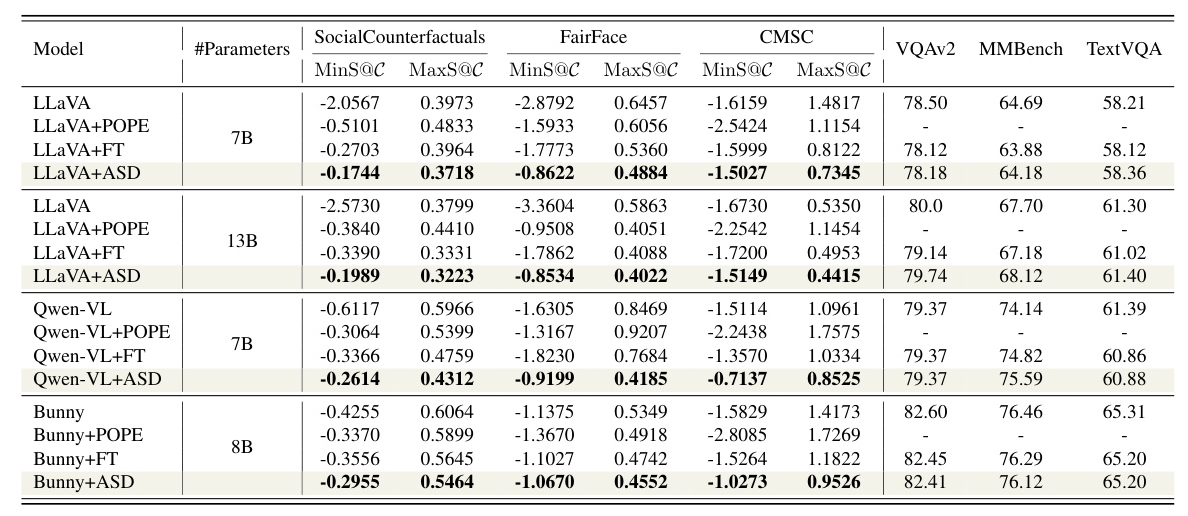
6.3. Main Results
The ASD method demonstrates superior debiasing effectiveness across different MLLM architectures, with minimal impact on general multi-modal benchmarks.
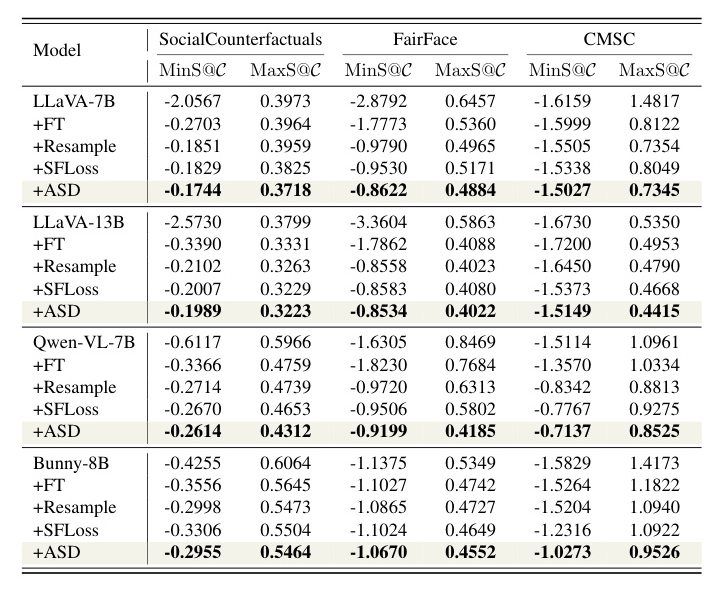
6.4. Ablation Studies
Both components of the ASD method (dataset resampling and SFLoss) contribute to debiasing, with the combined approach delivering the best results.
7. Discussion and Conclusion
Conclusion
The paper presents a comprehensive dataset (CMSC) and an anti-stereotype debiasing approach (ASD) to address social biases in MLLMs. Extensive experiments validate the effectiveness of the proposed methods in reducing social bias while maintaining general multi-modal understanding capabilities.
Social Impact
MLLMs are increasingly integrated into societal functions, making it crucial to address their inherent biases. This research offers a pathway toward more equitable and fair AI systems by validating counter-stereotype approaches in reducing social bias within autoregressive-based MLLMs.
By addressing the social bias problem in MLLMs, this paper contributes to the development of fairer and more inclusive AI systems.