

Authors:
Federico Belotti、Fabio Dadda、Marco Cremaschi、Roberto Avogadro、Riccardo Pozzi、Matteo Palmonari
Paper:
https://arxiv.org/abs/2408.06423
Introduction
Tables are essential tools for organizing and sharing information in various fields, including business and science. However, understanding the meaning of table contents can be challenging. Semantic Table Interpretation (STI) aims to address this by annotating tabular data to disambiguate their meaning. This involves tasks such as Cell-Entity Annotation (CEA), Column-Type Annotation (CTA), and Column-Property Annotation (CPA). The goal is to match table cells with entities from a background Knowledge Graph (KG), transforming tables into Knowledge Graphs or enriching them with additional information.
Related Work
Entity Disambiguation (ED) in tables is typically divided into two sub-tasks: Entity Retrieval (ER) and Entity Disambiguation (ED). Approaches to ED can be categorized into heuristic, machine learning (ML), and probabilistic models, as well as those based on Large Language Models (LLMs).
Heuristic, ML, and Probabilistic Approaches
Heuristic approaches often rely on string similarity, contextual information, and engineered features. ML techniques, such as Support Vector Machines (SVM) and Neural Networks (NN), learn patterns from labeled datasets. Probabilistic models, like Markov models, handle uncertainty using probability theory.
LLM-based Approaches
LLM-based approaches can be divided into encoder-based and decoder-based models. Encoder-based models, like TURL, use pre-trained transformers to capture both textual and relational knowledge. Decoder-based models, like TableLlama, use autoregressive LLMs fine-tuned with instruction tuning to perform specific tasks, including ED.
Considered Approaches
This study evaluates four state-of-the-art (SOTA) approaches for ED in tables: TableLlama, TURL, Alligator, and Dagobah.
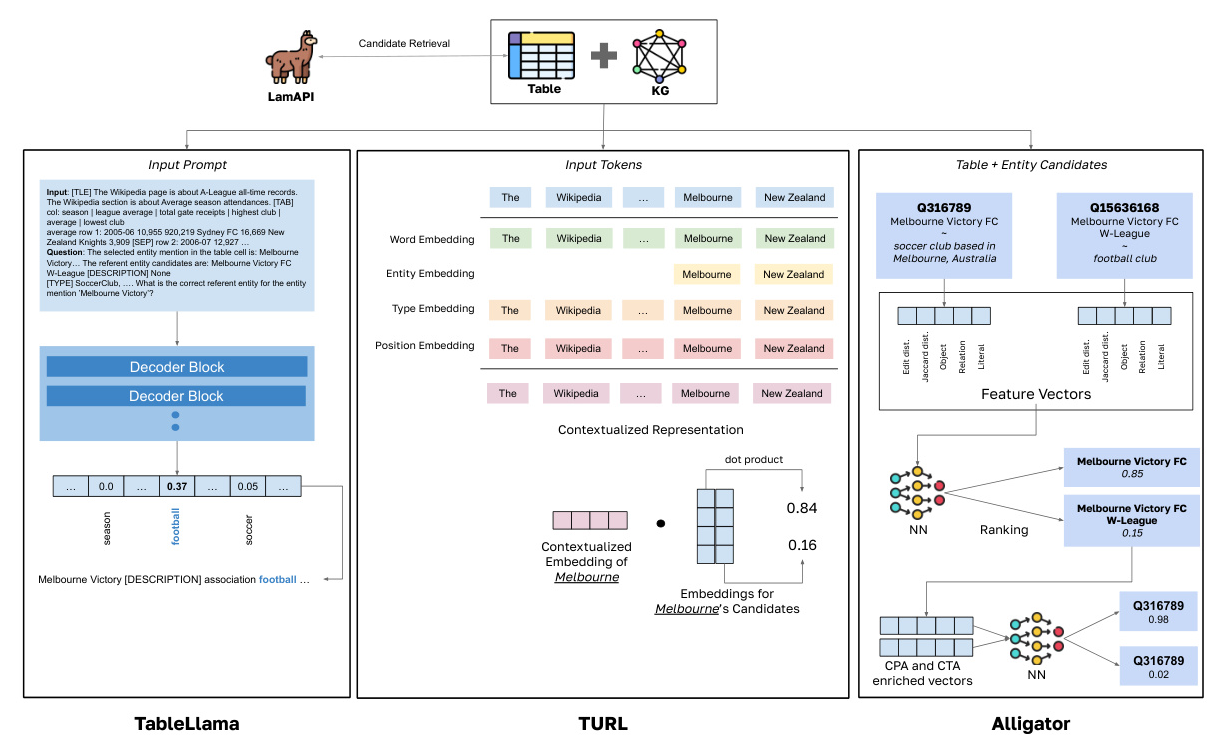
TableLlama
TableLlama uses Llama2, an autoregressive LLM, fine-tuned with instruction tuning on a multi-task dataset called TableInstruct. It handles tasks like CTA, CPA, and CEA by converting them into prompt-based text generation tasks.
TURL
TURL uses a BERT-based encoder-only model fine-tuned on relational web tables. It captures both textual and relational knowledge through a structure-aware transformer and is fine-tuned for specific downstream tasks like CEA.
Alligator
Alligator is a feature-based ML approach that uses engineered features and neural networks to score and rank candidate entities. It processes tables through multiple steps, including data analysis, entity retrieval, feature extraction, and context-based scoring.
Dagobah
Dagobah is a heuristic-based algorithm that performs CEA, CPA, and CTA through a multi-step pipeline. It uses Elasticsearch for entity retrieval and combines context and literal similarity for candidate pre-scoring.
Study Set-up
Datasets
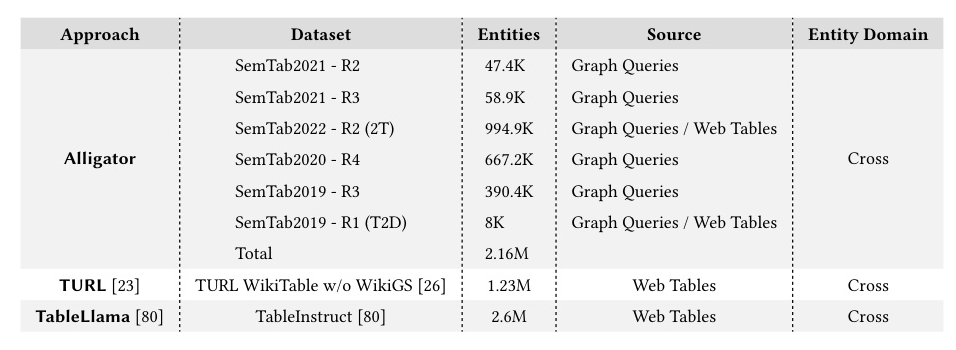
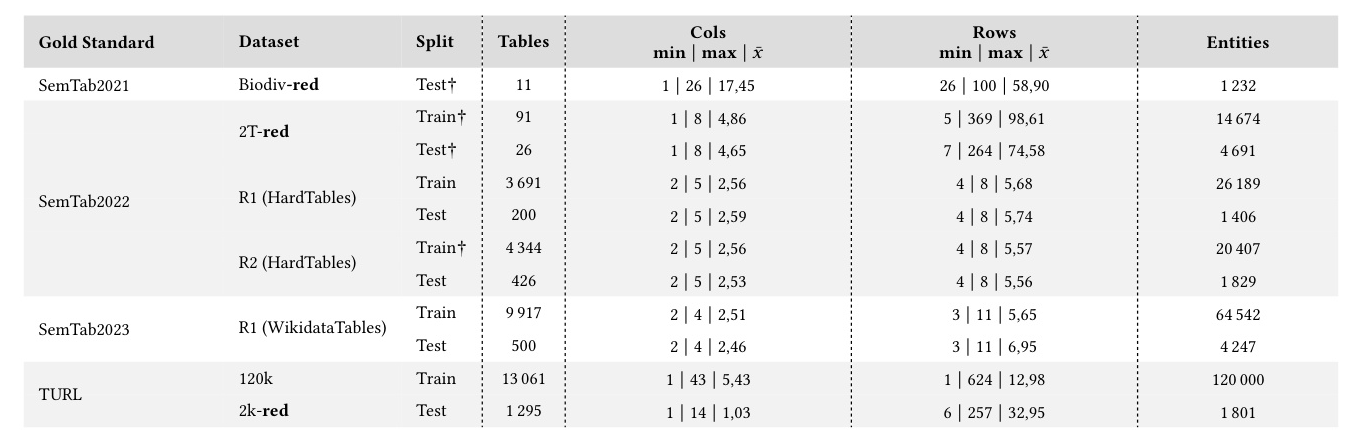
The study uses various datasets from different sources, including SemTab2021, SemTab2022, SemTab2023, and TURL. These datasets cover different domains and table sizes, providing a comprehensive evaluation ground.
Evaluation Metrics
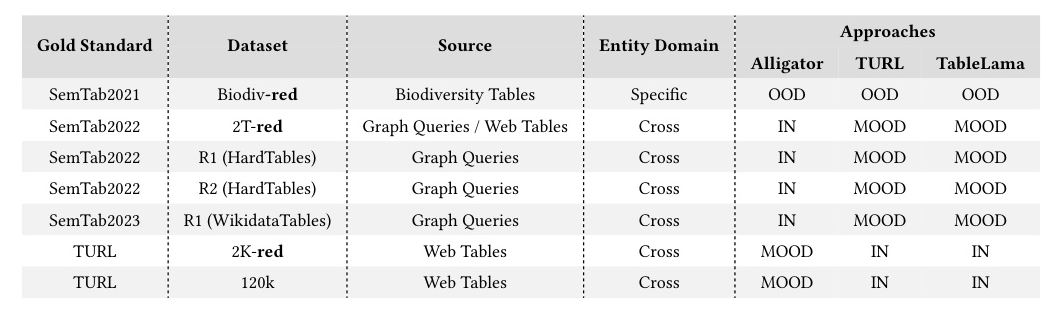
The evaluation metrics include Precision, Recall, and F1-score, which are equivalent to Accuracy in this study. The models are tested on in-domain (IN), out-of-domain (OOD), and moderately-out-of-domain (MOOD) settings.
Candidate Entity Retrieval
LamAPI, an entity retrieval system, is used to retrieve candidates for mentions in the tables. It provides high coverage and performance compared to other retrieval systems like Wikidata-Lookup.
Training and Implementation
The models are pre-trained and fine-tuned on specific datasets. TURL and TableLlama are fine-tuned on MOOD data, while Alligator is fine-tuned on a subset of the TURL dataset. The experiments are conducted on high-performance computing infrastructure.
Results and Discussion
Main Results
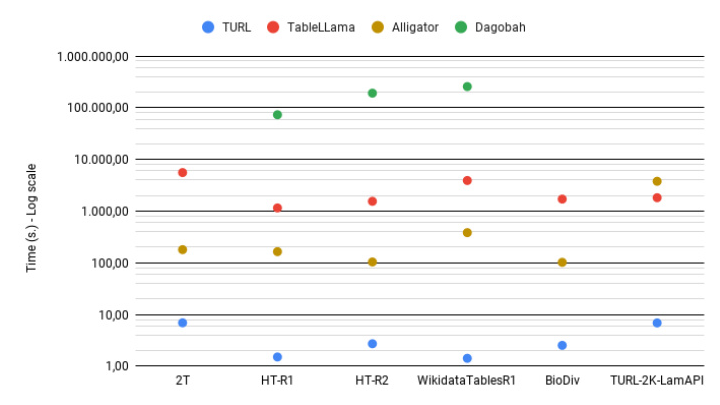
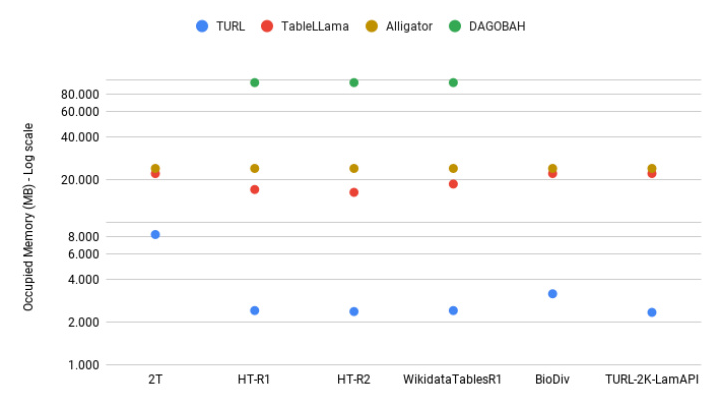
The performance of the models varies across different datasets and settings. TableLlama generally achieves higher accuracy, especially on MOOD and OOD data, while Alligator excels on in-domain data. TURL shows the fastest execution time and lowest memory usage but lacks generalization capabilities.
Ablation Studies
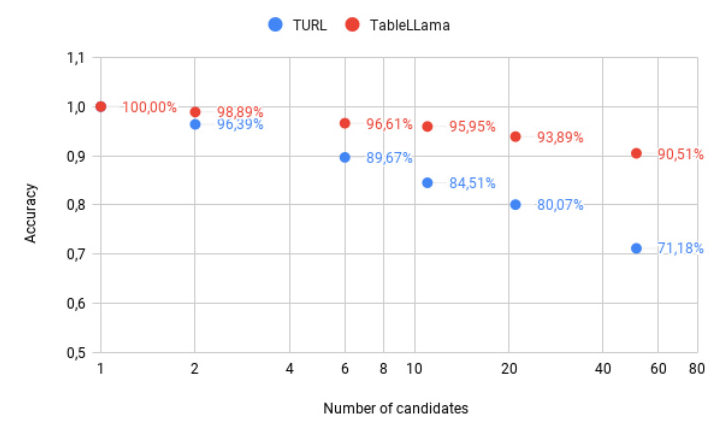
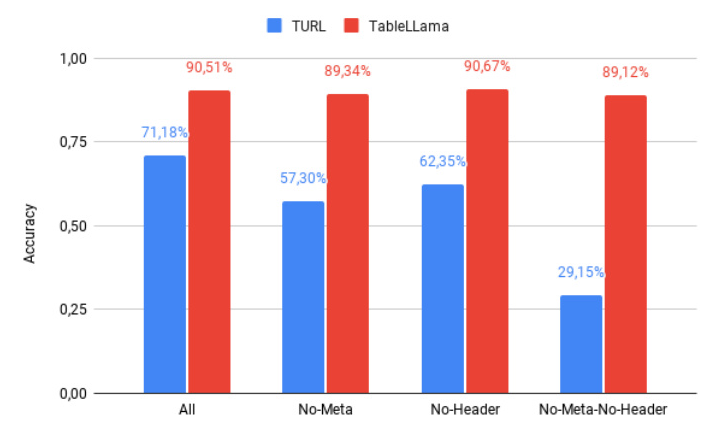
Ablation studies reveal that the number of candidates and the presence of table metadata significantly impact the performance of TURL and TableLlama. TableLlama is less affected by the absence of metadata, indicating better generalization.
Discussion
Generative GTUM approaches like TableLlama show promising accuracy and generalization but require significant computational resources. Specific STI models like Alligator can outperform generalistic models in in-domain settings with higher efficiency.
Conclusions and Future Works
This study provides insights into the strengths and limitations of different ED approaches for tables. Future work includes developing smaller, more efficient LLM-based models and enabling NIL handling and confidence scoring for cell annotations.
Illustrations
-
Architectures of TableLlama, TURL, and Alligator.
! (https://example.com/illustration1.png)
(https://example.com/illustration1.png) -
Statistics of the datasets used to pre-train the considered approaches.
! (https://example.com/illustration2.png)
(https://example.com/illustration2.png) -
Statistics of the datasets used to fine-tune and evaluate models.
! (https://example.com/illustration3.png)
(https://example.com/illustration3.png) -
Characteristics of the datasets used to test the approaches based on ML.
! (https://example.com/illustration4.png)
(https://example.com/illustration4.png) -
Performances of the four algorithms on our test data.
! (https://example.com/illustration5.png)
(https://example.com/illustration5.png) -
Overall elapsed time per dataset.
! (https://example.com/illustration6.png)
(https://example.com/illustration6.png) -
Overall occupied memory per dataset.
! (https://example.com/illustration7.png)
(https://example.com/illustration7.png) -
Accuracies achieved by TableLlama and TURL w.r.t. the number of candidates.
! (https://example.com/illustration8.png)
(https://example.com/illustration8.png) -
Accuracies achieved by TableLlama and TURL w.r.t. the presence of table’s metadata.
! (https://example.com/illustration9.png)
(https://example.com/illustration9.png)
This comprehensive evaluation provides a foundation for future research in entity disambiguation in tables, highlighting the potential and challenges of different approaches.